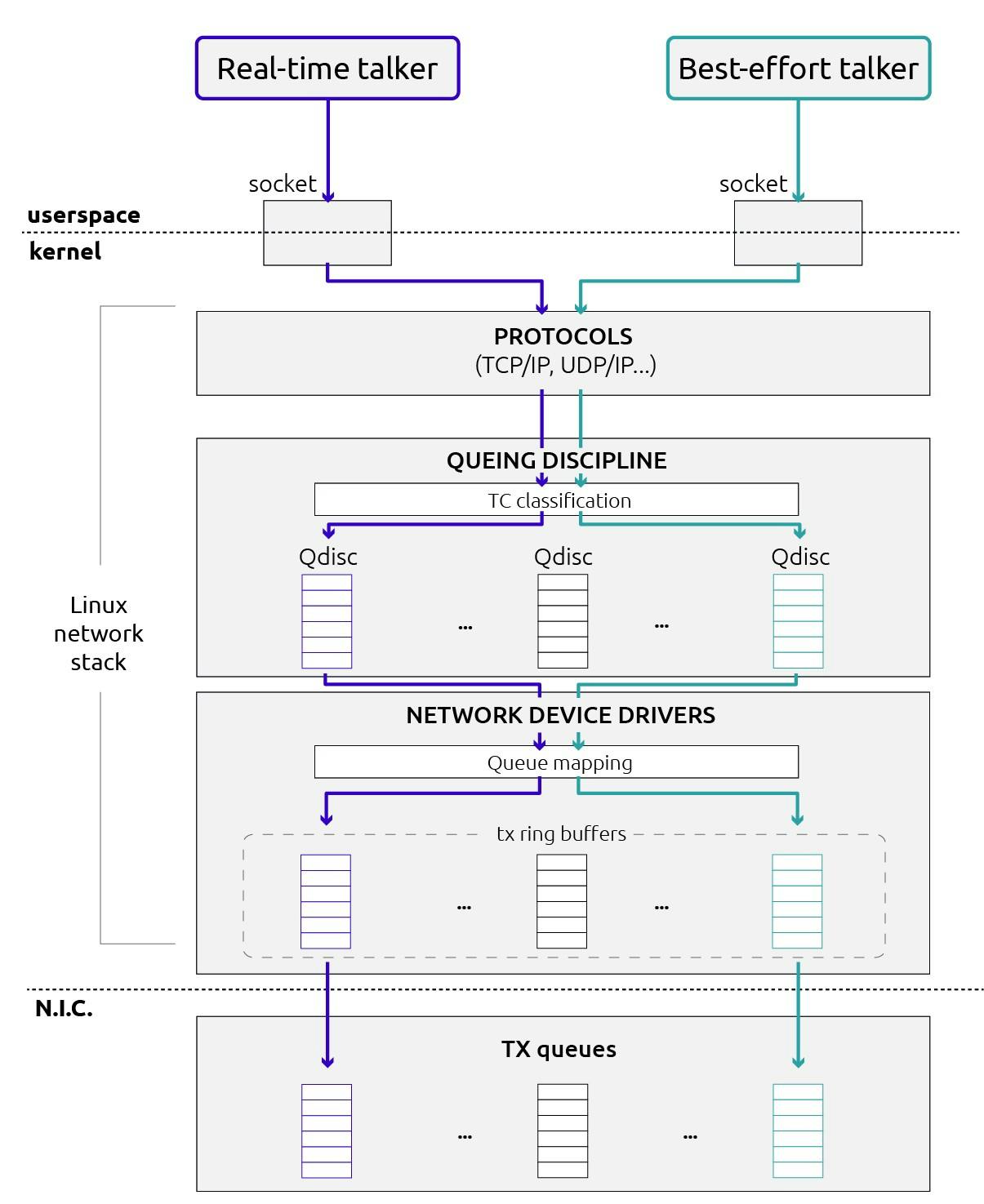
An evaluation of the Linux communication stack for real-time robotic applications . The content of this article comes from “ ” available at Real-time Linux communications: an evaluation of the Linux communication stack for real-time robotic applications https://arxiv.org/pdf/1808.10821.pdf Peer written with Carlos San Vicente Gutiérrez, Lander Usategui San Juan and Irati Zamalloa Ugarte . As robotics systems become more distributed, the communications between different robot modules play a key role for the reliability of the overall robot control. In this article, we present a study of the Linux communication stack meant for real-time robotic applications. We evaluate the real-time performance of UDP based communications in Linux on multicore embedded devices as test platforms. We prove that, under an appropriate configuration, the Linux kernel greatly enhances the determinism of communications using the UDP protocol. Furthermore, we demonstrate that concurrent traffic disrupts the bounded latencies and propose a solution by separating the real-time application and the corresponding interrupt in a CPU. Introduction The Ethernet communication standard is widely used in robotics systems due to its popularity and reduced cost. When it comes to real-time communications, while historically Ethernet represented a popular contender, many manufacturers selected field buses instead. As introduced in previous work [1], we are starting to observe a change though. With the arrival of the ‘Time Sensitive Networking” (TSN) standards, Ethernet is expected to gain wider adoption for real-time robotic applications. There are currently several communication technologies based on the Ethernet protocols. Some protocols such as Profinet RT [2] or Powerlink [3] use a network stack specifically designed for the protocol1 . Other protocols, such as the Data Distributed Services (DDS) [4], OPC-UA [5] or Profinet are built on top of the well known TCP/IP and UDP/IP OSI layers. This facilitates the process of interoperating with common transport protocols and ensures a high compatibility between devices. However, their corresponding network stacks and drivers are typically not optimized for real-time communications. The real-time performance is limited when compared to other Ethernet alternatives with specific network stacks. In this work, we aim to measure and evaluate the real-time performance of the Linux network subsystem with the UDP and IP protocols. UDP is used by several real-time transport protocols such as the Real Time Publish Subscribe protocol (RTPS). We aim to determine which configuration provides better isolation in a mixed-critical traffic scenario. To achieve real-time performance, the network stack will be deployed in a Real-Time Operating System (RTOS). In the case of Linux, the standard kernel does not provide realtime capabilities. However, with the Real-time Preemption patch (PREEMPT-RT), it is possible to achieve real-time computing capabilities as demonstrated [6]. Despite the Linux network subsystem not being optimized for bounded maximum latencies, with this work, we expect to achieve reasonable deterministic communications with PREEMPT-RT, as well as a suitable configuration. Setting up Real-Time communication in Linux The Real-time Preemption patch (PREEMPT-RT) There are currently different approaches to use Linux for real-time applications. A common path is to leave the most critical tasks to an embedded RTOS and give to Linux the highest level commands. A second approach is to use a dual-kernel scheme like Xenomai [7] and RTAI [8] which deploy a microkernel running in parallel with a separate Linux kernel. The problem for this kind of solution is that it requires special tools and libraries. A third approach is to use a single-kernel. The Real-Time Linux (RTL) Collaborative Project [9] is the most relevant open-source solution for this option. The project is based on the PREEMPT-RT patch and aims to create a predictable and deterministic environment turning the Linux kernel into a viable real-time platform. The ultimate goal of the RTL project is to mainline the PREEMPT-RT patch. The importance behind this effort is not related to the creation of a Linux-based RTOS, but to provide the Linux kernel with real-time capabilities. The main benefit is that it is possible to use the Linux standard tools and libraries without the need of specific real-time APIs. Also, Linux is widely used and strongly supported, this helps to keep the OS updated with new technologies and features, something which is often a problem in smaller projects due to resource limitations. The Linux Networking Architecture While it is possible to bypass the Linux Network Stack using custom drivers or user-space network libraries, we are interested in using the Linux Network Stack; mainly, because it is easier to maintain and integrate with a user-space application or communication middlewares. In addition, the Linux Network Stack supports a wide range of drivers which allow to deploy an application in different devices. **Linux Traffic Control**An important module of the networking subsystem is the Linux kernel packet scheduler, which is configured with the user-space tool Linux Traffic Control (TC) [10]. TC provides mechanisms to control the way enqueued packets are sent and received. It provides a set of functionality such as shaping, scheduling, policing and dropping network traffic. The main element of the Linux packet scheduler module are the queuing disciplines (Qdisc), which are network traffic disciplines to create queues and quality of service (QoS) rules for reception and transmission. There are ingress and egress Qdisc for reception and transmission respectively. The egress Qdisc provides shaping, scheduling and filter capabilities for data transmission from the network protocol layers to the network interface ring buffers. On the other hand, the ingress Qdisc provides filter and dropping capabilities for the reception path from the network interface ring buffers to the network protocol layers (although these are commonly less used). For the egress Qdisc there are two basic types of disciplines: classless Qdisc and classful Qdisc. The classless Qdisc does not contain another Qdisc so there is only one level of queuing. The classless Qdisc only determines whether the packet is classified, delayed or dropped. The classful Qdisc can contain another Qdisc, so there could be several levels of queues. In such case, there may be different filters to determine from which Qdisc packets will be transmitted. Qdisc can be used to avoid traffic congestion with non real-time traffic at the transmission path (figure aside). For a classless Qdisc, the default discipline is the PFIFO_FAST, which has three FIFO priority bands. In the case of a classful Qdisc there is the PRIO qdisc which can contain an arbitrary number of classes of differing priority. There are also specific egress Qdisc destined for multiqueue network devices, for example the MQPRIO Qdisc [11], which is a queuing discipline to map traffic flows to hardware queues based on the priority of the packet. This Qdisc will dequeue packets with higher priority allowing to avoid contention problems in the transmission path. In addition to the priority Qdisc, it is common to attach a shaper to limit low priority traffic bandwidth such as a the ‘Token Bucket Filter’ TBF Qdisc [12]. Recently, because of the interest in support TSN in the Linux network stack, new Qdiscs have been created or are currently under development. The IEEE 802.1Q-2014 Credit Based Shaper (CBS) [13], Qdisc has already been included from kernel 4.15. The CBS is used to enforce a Quality of Service by limiting the data rate of a traffic class. Currently there are two Qdisc under development, the ‘Earliest Transmit Time First (ETF)’ [14] which provides a per-queue transmit time based scheduling and the ‘Time-Aware Priority Scheduler’ (TAPRIO) which provides per-port scheduling. These Qdisc will allow to create deterministic scheduling in software or to offload the work to the network hardware if it is supported. **Traffic classification**In order to steer a traffic flow to a Qdisc or to a ring buffer, the traffic flow must be classified usually by marking the traffic with a priority. There are several ways to set the priority of a specific traffic flow: a) from the user-space using socket options SO_PRIORITY and IP_TOS, b) with iptables and c) with net_prio cgroups. Setting the priority of a flow maps the traffic from a socket (or an application) to a Socket Buffer (SKB) priority, which is an internal priority for the kernel networking layer. The SKB priority is used by the MQPRIO Qdisc to map the traffic flow to a traffic class of the Qdisc. At the same time, each traffic class is mapped to a TX ring buffer. **Network hard IRQ threads and softirqs**At the reception path, the processing of the packets is driven by the kernel interrupt handling mechanism and the “New API” (NAPI) network drivers. NAPI is a mechanism designed to improve the performance for high network loads. When there is a considerable incoming traffic, a high number of interrupts will be generated. Handling each interrupt to process the packets is not very efficient when there are many packets already queued. For this reason NAPI uses interrupt mitigation when high bandwidth incoming packets are detected. Then, the kernel switches to a polling-based processing, checking periodically if there are queued packets. When there is not as much load, the interrupts are re-enabled again. In summary, the Linux kernel uses the interrupt-driven mode by default and only switches to polling mode when the flow of incoming packets exceeds a certain threshold, known as the “weight” of the network interface. This approach works very well as a compromise between latency and throughput, adapting its behavior to the network load status. The problem is that NAPI may introduce additional latency, for example when there is bursty traffic. There are some differences between how PREEMPT-RT and a normal kernel handle interrupts and consequently how packets are handled at the reception path. The modifications of PREEMPT-RT allow to configure the system to improve the networking stack determinism. In PREEMPT-RT, most interrupt request (IRQ) handlers are forced to run in threads specifically created for that interrupt. These threads are called IRQ threads [15]. Handling IRQs as kernel threads allows priority and CPU affinity to be managed individually. IRQ handlers running in threads can themselves be interrupted, so that the latency due to interrupts are mitigated. For a multiqueue NIC, there is an IRQ for each TX and RX queue of the network interface, allowing to prioritize the processing of each queue individually. For example, it is possible to use a queue for real-time traffic and raise the priority of that queue above the other queue IRQ threads. Another important difference is the context where the softirq are executed. From version 3.6.1-rt1, the soft IRQ handlers are executed in the context of the thread that raised that Soft IRQ [16]. This means that the NET_RX soft IRQ will be normally executed in the context of the network device IRQ thread, which allows a fine control of the networking processing context. However, if the network IRQ thread is preempted or it exhausts its NAPI weight time slice, it is executed in the ksoftirqd/n (where n is the logical number of the CPU). Processing packets in the ksoftirqd/n context is troublesome for real-time because this thread is used by different processes for deferred work and can add latency. Also, as the ksoftirqd runs with SCHED_OTHER policy, the thread execution can be easily preempted. In practice, the soft IRQs are normally executed in the context of NIC IRQ threads and in the ksoftirqd/n thread for high network loads and under heavy stress (CPU, memory, I/O, etc.). **Socket allocation**One of the current limitations of the network stack for bounded latency is socket memory allocation. Every packet in the stack needs a sckbuff struct which holds meta-data of the packet. This struct needs to be allocated for each packet, and the time required for the allocation represents a large part of the overhead for processing the packet and jitter source. network One of the last projects of the Linux network developers is the XDP or eXpress Data Path [17] which aims to provide a high performance, network data path in the Linux kernel. XDP will provide faster packet processing by eliminating the socket meta-data allocation. Despite realtime communications are not the main motivation behind this project, XDP looks like an interesting feature to be used as an express data path for real-time communications [18]. programmable Experimental results To evaluate the real-time performance of the network stack, we used two embedded devices, measuring the latencies of a round-trip test. Round-trip test The network latency is measured as the round-trip time (RTT), also called ping-pong test. For the test we use a client in one of the devices and a server in the other. The roundtrip latency is measured as the time it takes for a message to travel from the client to the server, and from the server back to the client. For the client and server one we used a modified version of cyclictest [19] which allows us to save the statistics and create latency histograms which show the amount of jitter and worst-case latency of the test. Additionally, we count the number of missed deadlines for a 1 millisecond target loop time. For the timing loop we used the clock_nanosleep primitive. We also used memory locking, the FIFO scheduler and set a real-time priority of 80. In all the tests, we marked the traffic as priority traffic using the socket option SO_PRIORITY. To generate load in the system, we used the program stress and, to generate traffic, the program iperf. Graphical presentation of the measured round-trip latency. T1 is the time-stamp when data is send from the round-trip client and T2 is the time-stamp when data is received again at the round-trip client. Round-trip latency is defined as T2 — T1. Task and IRQ affinity and CPU shielding In real-time systems, real-time tasks and interrupts can be pinned to a specific CPU to separate their resources from non real-time tasks. This is an effective way to prevent non real-time processes interferences. There are several ways to set the affinity of tasks and IRQs with CPUs. For the experiments, we decided to compare two levels of isolation. In the first case, we pin the real-time task the IRQ of the real-time traffic queue to the same CPU. We use “pthread_setaffinity_np” and “smp irq affinity” to set the priorities of the IRQs. In the second case, we use cpusets [20], which is part of the Linux cgroups to assign a CPU for real-time tasks. With this method, we can also migrate all processes running in the isolated CPU, so that only the real-time task is allowed to run in that CPU . We also set the affinity of all the IRQs to the non real-time CPU, while the IRQs of the real-time queue (of the network device) are set with affinity in the isolated CPU. In the experimental setup, we use the described methods to isolate applications sending and receiving real-time traffic. The tests are run using different configurations: , , and . In the first case, , we use a vanilla kernel. In the second case, , we use a PREEMPT-RT kernel without binding the round-trip programs and network IRQs to any CPU. In the third case, , we bind the IRQ thread of the priority queue and the client and server programs to CPU 1 of each device. Finally, in the fourth case, , we run the roundtrip application in an isolated CPU. In all the cases, we set the priority of the RTT test client and server to a 80 value. no-rt rt-normal rt-affinities rt-isolation no-rt rt-normal rt-affinities rt-isolation In order to have an intuition about the determinism of each configuration, we ran a 1 hour cyclictest, obtaining the following worst-case latencies: no-rt: 13197 µs, rtnormal/rt-affinities: 110 µs and rt-isolation: 88 µs. **System and network load**For each case, we run the tests in different load conditions: idle, stress, tx-traffic and rx-traffic: : No other user-space program running except the client and server. idle : We generate some load to stress the CPU and memory and block memory. stress : We generate some concurrent traffic in the transmission path of the client. We send 100 Mbps traffic from the client to the PC. tx-traffic : We generate some concurrent traffic in the reception path of the server. We send 100 Mbps traffic from the PC to the server rx-traffic When generating concurrent traffic, there is also congestion in the MAC queues of both devices. However, as the traffic of the test is prioritized, the delay added by the link layer is not meaningful for the test. Results We have compared the results obtained for a round-trip test of 3 hours of duration, sending UDP packets of 500 Bytes at a 1 millisecond rate. The following tables show the statistics of the different configuration used under different conditions. For real-time benchmarks, the most important metrics are the worst-cases (Max), packet loss and the number of missed deadlines. In this case, we decided to set a 1 millisecond deadline to match it with the sending rate. As it can be seen in Table I, the non real-time kernel results in what seems to be the best average performance, but in contrast, it has a high number of missed deadlines and a high maximum latency value; even when the system is idle. The latency suffers specially when the system is stressed due to the lack of preemption in the kernel. For rt-normal (Table II), the latencies are bounded when the system is stressed. When generating concurrent traffic, we observe higher latency values and some missed deadliness. For rt-affinities, we can see an improvement compared to the previous scenario. Specially for concurrent traffic (Table III). We can also see that when pinning the round-trip threads and the Ethernet IRQs for the priority to the same CPU, the latency seems to be bounded. In the case of no-isolation (table IV), we appreciate a similar behavior when compared to the affinity case. We can see that stressing the non isolated CPU has some impact on the tasks of the isolated core. However, in the idle case, for short test we observed very low jitter. To the best of our knowledge, one of the main contributions of such latency was the scheduler ticker, which is generated each 10 milliseconds . While it is possible to avoid it in the client because it runs in a timed loop, in the server side, it is not possible to avoid the ticker. As both devices are not synchronized, at some point, the clock of the server side drifts from the client and the scheduler ticker interferes in the server execution. This effect can be seen in the following Figure: Time-plot for isolated CPU. At the beginning, we can observe the effect of the scheduler ticker preempting the real-time task and adding latency to the round-trip test latencies. When running the test with 200 Mbps RX-traffic, we observed that best-effort traffic is processed in the ksoftirqd/0 context continuously. This generates high latency spikes in all the cases, even for the isolation case. To trace the source of these latency spikes, we should trace the kernel taking a snapshot when the latency occurs. Real-time Ethernet round-trip-time histograms for idle system. Real-time Ethernet round-trip-time histograms for system under load (stress). Real-time Ethernet round-trip-time histograms for concurrent low priority traffic in the transmission path. Real-time Ethernet round-trip-time histograms for concurrent low priority traffic in the reception path. Conclusions and future work The results obtained prove that the Linux real-time setup presented improves greatly the determinism of communications using the UDP protocol. First, we confirm that the communication delay caused when the system is under heavy load is mitigated by making use of a real-time kernel and by running the application with real-time priority.Second, we demonstrate that, whenever there is concurrent traffic, simply setting the priorities of the real-time process is not enough. Separating the real-time application and the corresponding interrupt in a CPU seems to be an effective approach to avoid high latencies. For higher concurrent traffic loads, however, we can still see unbounded latency and further research is required to overcome this limitation with our current setup. We conclude that, under certain circumstances and for a variety of stress and traffic overload situations, Linux can indeed meet some real-time constraints for communications. Hereby, we present an evaluation of the Linux communication stack meant for real-time robotic applications. Future work should take into account that the network stack has not been fully optimized for low and bounded latency; there is certainly room for improvement. It seems to us that there is some ongoing work inside the Linux network stack, such as the XDP [17] project, showing promise for an improved real-time performance. In future work, it might be interesting to test some of these features and compare the results. References [1] C. S. V. Gutiérrez, L. U. S. Juan, I. Z. Ugarte, and V. M. Vilches, “Time-sensitive networking for robotics,” CoRR, vol. abs/1804.07643, 2018. [Online]. Available: http://arxiv.org/abs/1804.07643 [2] “PROFINET the leading industrial ethernet standard,” profibus.com/technology/profinet/, accessed: 2018–04–12. https://www. [3] “POWERLINK — powerlink standarization group,” ethernet-powerlink.org/powerlink/technology, accessed: 2018–04–12. https://www. [4] “Data Distribution Service Specification, version 1.4,” omg.org/spec/DDS/1.4/, accessed: 2018–04–12. https://www. [5] “OPC-UA — the opc unified architecture (ua),” org/about/opc-technologies/opc-ua/, accessed: 2018–04–12. https://opcfoundation. [6] H. Fayyad-Kazan, L. Perneel, and M. Timmerman, “Linuxpreempt-rt vs. commercial rtoss: how big is the performance gap?” GSTF Journal on Computing (JoC), vol. 3, no. 1, 2018. [Online]. Available: http://dl6.globalstf.org/index.php/joc/article/view/1088 [7] “Xenomai project home page,” April 2018, [Accessed: 2018–04–12]. [Online]. Available: https://xenomai.org/ [8] “Rtai project home page,” April 2018, [Accessed: 2018–04–12]. [Online]. Available: https://www.rtai.org/ [9] “The RTL Collaborative Project,” realtime/rtl/start, accessed: 2018–04–12. https://wiki.linuxfoundation.org/ [10] “Traffic control — linux queuing disciplines,” man-pages/man8/tc.8.html, accessed: 2018–04–12. http://man7.org/linux/ [11] “Multiqueue Priority Qdisc — linux man pages,” systutorials.com/docs/linux/man/8-tc-mqprio/, accessed: 2018–04–12. https://www. [12] “Token Bucket Filter — linux queuing disciplines,” systutorials.com/docs/linux/man/8-tc-tbf/, accessed: 2018–04–12. https://www. [13] “ CBS — Credit Based Shaper (CBS) Qdisc,” man-pages/man8/tc-cbs.8.html, accessed: 2018–04–12 http://man7.org/linux/ [14] “Scheduled packet transmission: Etf,” [Accessed: 2018–04–12]. [Online]. Available: https://lwn.net/Articles/758592/ [15] J. Edge, “Moving interrupts to threads,” October 2008, [Accessed: 2018–04–12]. [Online]. Available: https://lwn.net/Articles/302043/ [16] J. Corbet, “Software interrupts and realtime,” October 2012, [Accessed: 2018–04–12]. [Online]. Available: 520076/ https://lwn.net/Articles/ [17] “XDP (eXpress Data Path) documentation,” 701224/, accessed: 2018–04–12. https://lwn.net/Articles/ [18] “The road towards a linux tsn infrastructure, jesus sanchezpalencia,” April 2018, [Accessed: 2018–04–12]. [Online]. Available: https://elinux.org/images/5/56/ELC-2018-USA-TSNonLinux.pdf [19] “Cyclictest,” April 2018, [Accessed: 2018–04–12]. [Online]. Available: tools/cyclictest https://wiki.linuxfoundation.org/realtime/documentation/howto/ [20] S. Derr, “CPUSETS,” cgroup-v1/cpusets.txt, accessed: 2018–04–12. https://www.kernel.org/doc/Documentation/