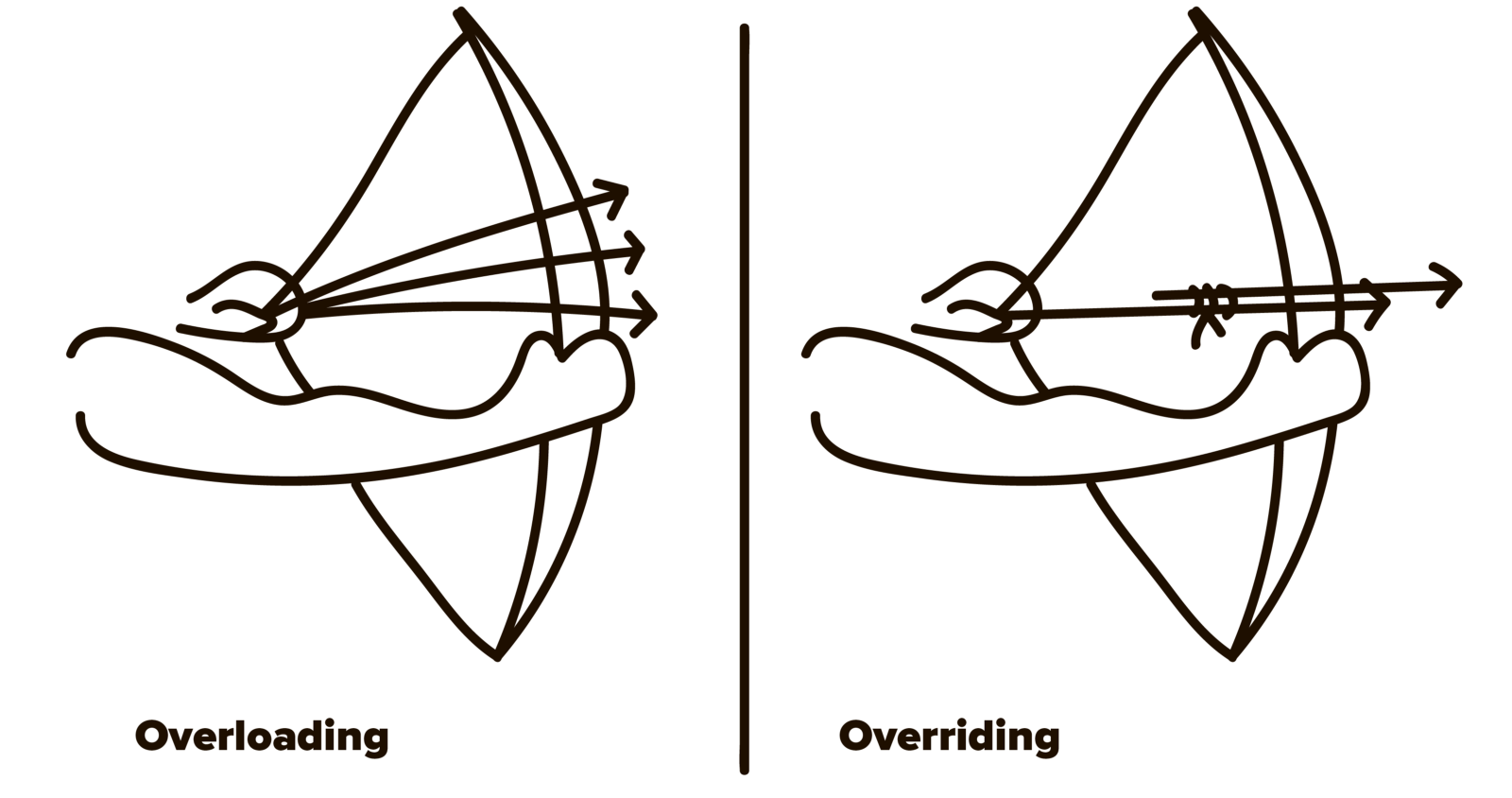
I’m running , a Telegram channel about and in general. Here are the best posts of September 2018. @pythonetc Python programming Overriding vs overloading There are two concepts with similar names that can be easily confused: overriding and overloading. Overriding happens when a child class defines a method that is already provided by its parents effectively replacing it. In some languages you have to explicitly mark the overriding method (C# requires the modifier), in some languages it's optional (the annotation in Java). Python doesn't require any special modifier nor does it have a standard way to mark such methods (some people like to use a custom decorator that does virtually nothing, just for the sake of readability). override @Override @override Overloading is another story. Overloading is having multiple functions with the same name but different signatures. It’s supported by languages like Java and C++ and is often used as a way to provide default arguments: class Foo { public static void main(String[] args) { System.out.println(Hello()); } public static String Hello() { return Hello("world"); } public static String Hello(String name) { return "Hello, " + name; }} Python doesn’t support finding functions by their signatures, only be their names. You can write code that analyzes the types and number of arguments explicitly. That usually looks clumsy and generally is not a nice thing to do: def quadrilateral_area(*args): if len(args) == 4: quadrilateral = Quadrilateral(*args) elif len(args) == 1: quadrilateral = args[0] else: raise TypeError() return quadrilateral.area() If you need type hints for this, the module can help you with the decorator: typing @overload from typing import overload @overloaddef quadrilateral_area( q: Quadrilateral) -> float: ... @overloaddef quadrilateral_area( p1: Point, p2: Point, p3: Point, p4: Point) -> float: ... Autovivification allows you to create a dictionary that returns the default value if the requested key is missing (instead of raising ). To create a you should provide not a default value but a factory of such values. collections.defaultdict KeyError defaultdict That allows you to create a dictionary that virtually contains infinite levels of nested dicts, allowing you to do something like . d[a][b][c]...[z] >>> def infinite_dict():... return defaultdict(infinite_dict)...>>> d = infinite_dict()>>> d[1][2][3][4] = 10>>> dict(d[1][2][3][5]){} Such behavior is called “autovivification”, the term came from the Perl language. Object instantiation An object instantiation includes two significant steps. First, the method of a class is called. It creates and returns a brand new object. Second, Python calls the method of that object. Its work is to set up the initial state of the object. __new__ __init__ However, isn't called if returns an object that is not an instance of the original class. The reason for this is that it was probably created by another class, hence was already called for that object: __init__ __new__ __init__ class Foo: def __new__(cls, x): return dict(x=x) def __init__(self, x): print(x) # Never called print(Foo(0)) That also means that you should not ever create instances of the same class in with a regular constructor ( ). It could lead to the double execution or even infinite recursion. __new__ Foo(...) __init__ Infinite recursion: class Foo: def __new__(cls, x): return Foo(-x) # Recursion Double : __init__ class Foo: def __new__(cls, x): if x < 0: return Foo(-x) return super().__new__(cls) def __init__(self, x): print(x) self._x = x The proper way: class Foo: def __new__(cls, x): if x < 0: return cls.__new__(cls, -x) return super().__new__(cls) def __init__(self, x): print(x) self._x = x [] In Python, you can override square brackets operator ( ) by defining magic method. This is how you create an object that virtually contains an infinite number of repeated elements: [] __getitem__ class Cycle: def __init__(self, lst): self._lst = lst def __getitem__(self, index): return self._lst[ index % len(self._lst) ] print(Cycle(['a', 'b', 'c'])[100]) # 'b' The unusual thing here is that the operator supports a unique syntax. It can be used not only like this — , but also like this — , or , or , or even . The semantic is , but you can use it any way you want for your custom objects. [] [2] [2:10] [2:10:2] [2::2] [:] [start:stop:step] But what gets as an index parameter if you call it using that syntax? The slice objects exist precisely for that. __getitem__ In : class Inspector:...: def __getitem__(self, index):...: print(index)...:In : Inspector()[1]1In : Inspector()[1:2]slice(1, 2, None)In : Inspector()[1:2:3]slice(1, 2, 3)In : Inspector()[:]slice(None, None, None) You can even combine tuple and slice syntaxes: In : Inspector()[:, 0, :](slice(None, None, None), 0, slice(None, None, None)) is not doing anything for you except simply storing , and attributes. slice start stop step In : s = slice(1, 2, 3)In : s.startOut: 1In : s.stopOut: 2In : s.stepOut: 3 Coroutine cancellation Any running coroutine can be cancelled via the method. will be thrown into the coroutine that will lead for it and all wrapping coroutines to be terminated, unless the error is caught and suppressed. asyncio cancel() CancelledError is a subclass of that means that it can be accidentally caught by that is meant to catch “any error”. To safely do this within a coroutine, you stuck with something like this: CancelledError Exception try ... except Exception try: await action()except asyncio.CancelledError: raiseexcept Exception: logging.exception('action failed') In , the common practice to schedule execution of some code at a later time is to spawn a task that does : asyncio await asyncio.sleep(x) import asyncio async def do(n=0): print(n) await asyncio.sleep(1) loop.create_task(do(n + 1)) loop.create_task(do(n + 1)) loop = asyncio.get_event_loop()loop.create_task(do())loop.run_forever() However, creating a new task may be expensive and is not necessary if you aren’t planning to any asynchronous operations (like the function in the example). Another way to do this is to use and functions that schedule an asynchronous callback to be called: do loop.call_later loop.call_at import asyncio def do(n=0): print(n) loop = asyncio.get_event_loop() loop.call_later(1, do, n+1) loop.call_later(1, do, n+1) loop = asyncio.get_event_loop() do() loop.run_forever()