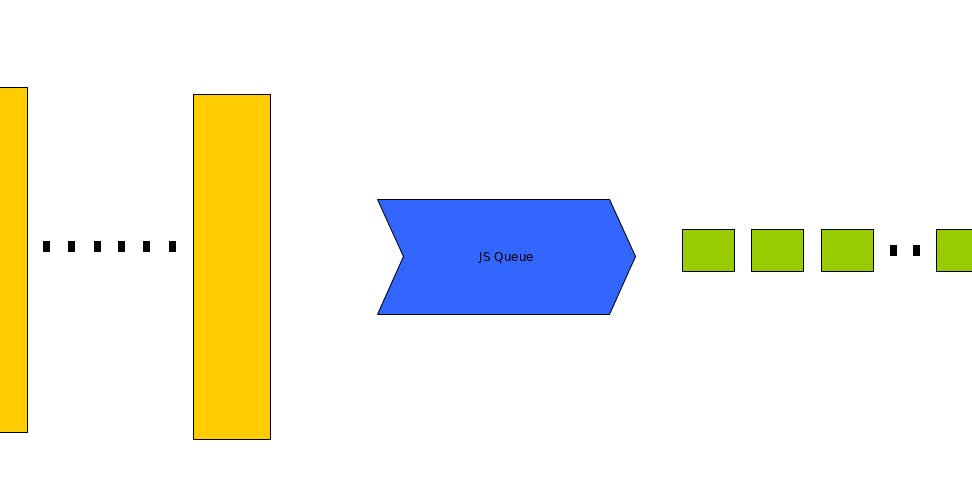
A FIFO buffer is a commonly needed data structure for many use-cases. Items are put into the buffer and retrieved in the order they were put in. This is similar functionality as a Queue. The difference between a Queue and a Buffer is that in the buffer the data that is inserted are all of the same data type. Further an arbitrary amount of data can be inserted and and the retrieval amount is also arbitrary. What are the use cases, where you want to put and retrieve arbitrary number items of the same type? Diverging into fields other than data processing: Think bank accounts: Money is put in different amount and taken out in quantities as needed..The same applies to grain storage on a farm..But the banks and the granaries do these. What is left for us in IT is Audio Data, which arrives at very fast, but has to depart at a slower specific speed so that it can be heard. Today’s culprit for this are the Text to Speech engines that facilitate interactive machine/human communication. The machine gets text (probably from an AI engine) which it converts to Audio bytes to be sent to the human at a specific speed that the human can hear. As expected the machine generates audio bytes at a rapid clip which then has to be buffered in order to be able to keep the delivery to the human at a much slower rate. An analogy is your local gas station. The Text to speech is the gasoline tanker which pumps a lot of gasoline at a rapid rate, filling up the gas tanks in the bowels of the gas station. These are then delivered at a much slower rate into the customer’s cars or other vehicles. In summary, conversion of text to speech (audio) can take place much more rapidly. There is the need for an Audio Buffer which receives audio from the text to speech (tts) to fill the buffer. This buffer is then drained at the rate of human speech and is comprehensible to the human. Audio data: The data consists of a sequence of numbers representing values of a audio signal at regular intervals (called sampling rate). There is also the concept of channels, which is multiple audio signals, which results in a sequence of multiple values. For the purpose of this article we will consider only one channel on the input side, and one channel on the output side. Numpy: This is software that facilitates storage/retrieval of arrays of numbers that is optimized for performance. Design: The requirements are: to be able to input in an arbitrary number of audio data frames (a frame is number representing an audio data point), which is a ordered array of audio signal values. On the output side be able to retrieve an arbitrary amount of these frames. We of course have to add convenient features to handle the limitations, which are a limited buffer size (causes buffer full conditions on input), no audio data available (buffer empty on the output side). Other convenience features will include zero-fill of audio data, in the case more audio data is requested, than available in the buffer retrieval. Implementation: The following describes an implementation of such a buffer in Python: Incoming audio bytes are stored in Buffer. The Buffer has a ‘bottom’ pointer, which points to the extent to which the buffer is filled. It also has a ‘start pointer’ which is the beginning of the buffer where new data can be pushed. The start pointer is fixed to the beginning of the buffer. The bottom pointer is ‘dynamic’ and goes ‘up and down’: up when data is extracted and ‘down’ when data is inserted. The data is always inserted at the top (start pointer) of the buffer resulting in existing data in the buffer being pushed ‘down’ thus increasing the value of the bottom pointer. The buffer empty condition occurs when the bottom pointer equals the start pointer. The buffer full condition occurs when the bottom pointer equals the length of the buffer. We can also include ‘graceful fails’ to handle the conditions where the buffer is full. When the buffer is full and data needs to be inserted, raise an Exception. When the buffer is empty (including the case where more data is requested than available in the buffer) return ‘zeroes’ for the missing data. This is the audio equivalent of ‘silence’ when no words are spoken. A diagram of this buffer is: Coding: (Disclaimer: No AI was used to generate the code below. All blame(praise is better) is to be assigned to the Author..) Following Object Oriented principles, the code is written as an class/object and is easy to use. The entire code is: import numpy as np #numpy is the standard package or numerical array processing class AudioBuf: def __init__(self,bufSize:int,name:str='',dtype=np.int16): self.buffer = np.zeros((bufSize), dtype=dtype) self.bufSize=bufSize self.dtype=dtype self.idx=0 self.name=name #give a name to the buffer. def putInBuf(self,inData:np.ndarray[np.dtype[np.int16]]): inData=inData[:, 0] #Get the 1st col = channel 0 - mono remainder = self.bufSize - self.idx #space available for insertion if remainder < len(inData): msg=f'Error: Buffer {self.name} is full' print(msg) self.showBuf() raise ValueError(msg) self.buffer[self.idx:self.idx + len(inData)] = inData self.idx += len(inData) def getFromBuf(self,outDataLen:int = None)->np.ndarray: if not outDataLen: outDataLen=self.idx # return entire data of length is not specified if self.idx >= outDataLen: retVal = self.buffer[:outDataLen] self.buffer[0:self.idx-outDataLen]=self.buffer[outDataLen:self.idx] #move buffer up self.idx -= outDataLen else: retVal=np.zeros((outDataLen), dtype=self.dtype) retVal[0:self.idx] = self.buffer[0:self.idx] self.idx=0 return np.reshape(retVal,(-1,1)) #The -1 value automatically calculates to the number of elements def showBuf(self): print(f'AudioBuf : {self.name} has length= {self.idx} with capacity {self.bufSize}') Conclusion: Audio buffering is essential and more important now due to numerous audio processing applications. The audio buffer algorithm presented above is a convenient python class. A FIFO buffer is a commonly needed data structure for many use-cases. Items are put into the buffer and retrieved in the order they were put in. This is similar functionality as a Queue. The difference between a Queue and a Buffer is that in the buffer the data that is inserted are all of the same data type. Further an arbitrary amount of data can be inserted and and the retrieval amount is also arbitrary. What are the use cases, where you want to put and retrieve arbitrary number items of the same type? Diverging into fields other than data processing: Think bank accounts: Money is put in different amount and taken out in quantities as needed..The same applies to grain storage on a farm..But the banks and the granaries do these. What is left for us in IT is Audio Data, which arrives at very fast, but has to depart at a slower specific speed so that it can be heard. Today’s culprit for this are the Text to Speech engines that facilitate interactive machine/human communication. The machine gets text (probably from an AI engine) which it converts to Audio bytes to be sent to the human at a specific speed that the human can hear. As expected the machine generates audio bytes at a rapid clip which then has to be buffered in order to be able to keep the delivery to the human at a much slower rate. An analogy is your local gas station. The Text to speech is the gasoline tanker which pumps a lot of gasoline at a rapid rate, filling up the gas tanks in the bowels of the gas station. These are then delivered at a much slower rate into the customer’s cars or other vehicles. In summary, conversion of text to speech (audio) can take place much more rapidly. There is the need for an Audio Buffer which receives audio from the text to speech (tts) to fill the buffer. This buffer is then drained at the rate of human speech and is comprehensible to the human. Audio data: The data consists of a sequence of numbers representing values of a audio signal at regular intervals (called sampling rate). There is also the concept of channels, which is multiple audio signals, which results in a sequence of multiple values. Audio data: For the purpose of this article we will consider only one channel on the input side, and one channel on the output side. Numpy: This is software that facilitates storage/retrieval of arrays of numbers that is optimized for performance. Numpy: Design: The requirements are: to be able to input in an arbitrary number of audio data frames (a frame is number representing an audio data point), which is a ordered array of audio signal values. On the output side be able to retrieve an arbitrary amount of these frames. We of course have to add convenient features to handle the limitations, which are a limited buffer size (causes buffer full conditions on input), no audio data available (buffer empty on the output side). Other convenience features will include zero-fill of audio data, in the case more audio data is requested, than available in the buffer retrieval. Implementation: The following describes an implementation of such a buffer in Python: Incoming audio bytes are stored in Buffer. The Buffer has a ‘bottom’ pointer, which points to the extent to which the buffer is filled. It also has a ‘start pointer’ which is the beginning of the buffer where new data can be pushed. The start pointer is fixed to the beginning of the buffer. The bottom pointer is ‘dynamic’ and goes ‘up and down’: up when data is extracted and ‘down’ when data is inserted. The data is always inserted at the top (start pointer) of the buffer resulting in existing data in the buffer being pushed ‘down’ thus increasing the value of the bottom pointer. The buffer empty condition occurs when the bottom pointer equals the start pointer. The buffer full condition occurs when the bottom pointer equals the length of the buffer. We can also include ‘graceful fails’ to handle the conditions where the buffer is full. When the buffer is full and data needs to be inserted, raise an Exception. When the buffer is empty (including the case where more data is requested than available in the buffer) return ‘zeroes’ for the missing data. This is the audio equivalent of ‘silence’ when no words are spoken. A diagram of this buffer is: Coding: (Disclaimer: No AI was used to generate the code below. All blame(praise is better) is to be assigned to the Author..) Following Object Oriented principles, the code is written as an class/object and is easy to use. The entire code is: import numpy as np #numpy is the standard package or numerical array processing class AudioBuf: def __init__(self,bufSize:int,name:str='',dtype=np.int16): self.buffer = np.zeros((bufSize), dtype=dtype) self.bufSize=bufSize self.dtype=dtype self.idx=0 self.name=name #give a name to the buffer. def putInBuf(self,inData:np.ndarray[np.dtype[np.int16]]): inData=inData[:, 0] #Get the 1st col = channel 0 - mono remainder = self.bufSize - self.idx #space available for insertion if remainder < len(inData): msg=f'Error: Buffer {self.name} is full' print(msg) self.showBuf() raise ValueError(msg) self.buffer[self.idx:self.idx + len(inData)] = inData self.idx += len(inData) def getFromBuf(self,outDataLen:int = None)->np.ndarray: if not outDataLen: outDataLen=self.idx # return entire data of length is not specified if self.idx >= outDataLen: retVal = self.buffer[:outDataLen] self.buffer[0:self.idx-outDataLen]=self.buffer[outDataLen:self.idx] #move buffer up self.idx -= outDataLen else: retVal=np.zeros((outDataLen), dtype=self.dtype) retVal[0:self.idx] = self.buffer[0:self.idx] self.idx=0 return np.reshape(retVal,(-1,1)) #The -1 value automatically calculates to the number of elements def showBuf(self): print(f'AudioBuf : {self.name} has length= {self.idx} with capacity {self.bufSize}') import numpy as np #numpy is the standard package or numerical array processing class AudioBuf: def __init__(self,bufSize:int,name:str='',dtype=np.int16): self.buffer = np.zeros((bufSize), dtype=dtype) self.bufSize=bufSize self.dtype=dtype self.idx=0 self.name=name #give a name to the buffer. def putInBuf(self,inData:np.ndarray[np.dtype[np.int16]]): inData=inData[:, 0] #Get the 1st col = channel 0 - mono remainder = self.bufSize - self.idx #space available for insertion if remainder < len(inData): msg=f'Error: Buffer {self.name} is full' print(msg) self.showBuf() raise ValueError(msg) self.buffer[self.idx:self.idx + len(inData)] = inData self.idx += len(inData) def getFromBuf(self,outDataLen:int = None)->np.ndarray: if not outDataLen: outDataLen=self.idx # return entire data of length is not specified if self.idx >= outDataLen: retVal = self.buffer[:outDataLen] self.buffer[0:self.idx-outDataLen]=self.buffer[outDataLen:self.idx] #move buffer up self.idx -= outDataLen else: retVal=np.zeros((outDataLen), dtype=self.dtype) retVal[0:self.idx] = self.buffer[0:self.idx] self.idx=0 return np.reshape(retVal,(-1,1)) #The -1 value automatically calculates to the number of elements def showBuf(self): print(f'AudioBuf : {self.name} has length= {self.idx} with capacity {self.bufSize}') Conclusion: Audio buffering is essential and more important now due to numerous audio processing applications. The audio buffer algorithm presented above is a convenient python class.