
This story draft by @scripting has not been reviewed by an editor, YET.
Maintaining Coreset Accuracy in Big Data Streaming

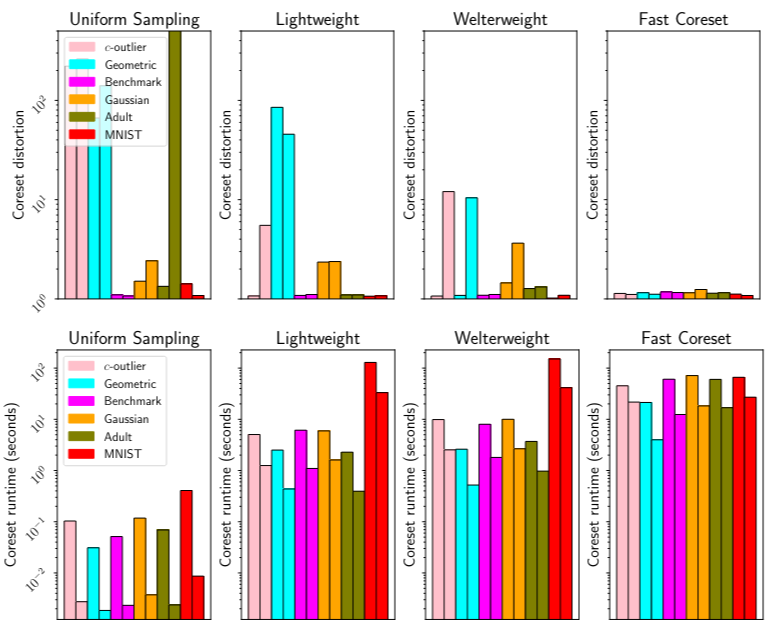
Weaving spells of logic and creativity, bringing ideas to life, and automating the impossible.
Story's Credibility


Weaving spells of logic and creativity, bringing ideas to life, and automating the impossible.
Story's Credibility
About Author

Weaving spells of logic and creativity, bringing ideas to life, and automating the impossible.