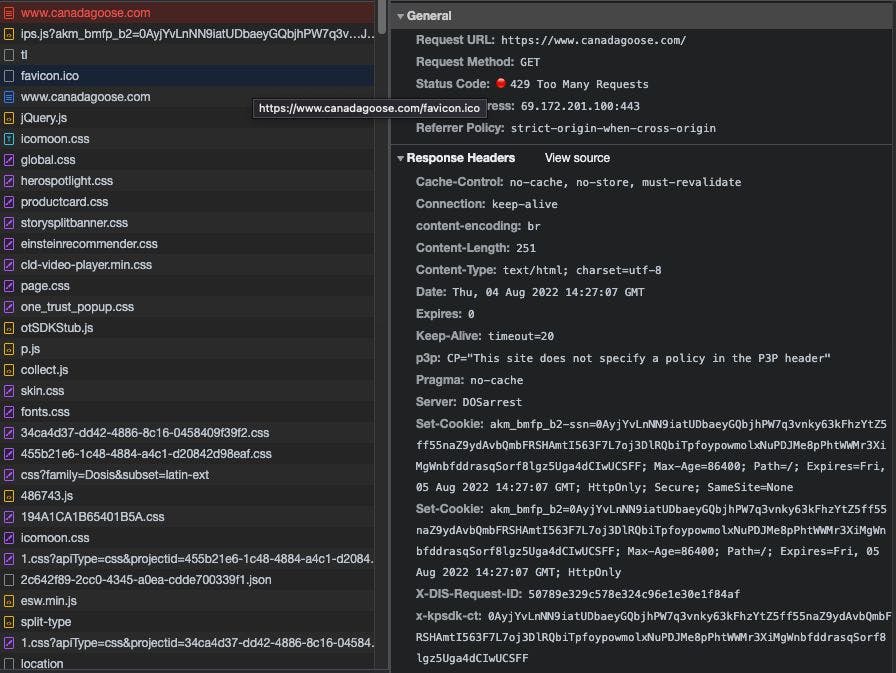
A Quick Benchmark From a Web Scraping Perspective A bit of Context In the Web Scraping industry, we've heard a lot of times about Selenium and Playwright when there's the need for a fully-headed scraper in Python (and of course Puppeteer for JS). And it is almost ironic that two of the most used tools were built for purposes other than web scraping. Both Selenium and Playwright are, in fact, browser automation tools, created for helping front-end developers test their work, automating tests about the websites they are building using different browsers. But what is a scraper if not an automated browser going around the web? What Is Selenium? As mentioned before, Selenium is an open-source automated testing framework used to validate web applications across different browsers and platforms. It's a suite with several components and modules, and you can find a great explanation of its history in . this great blog post by Krishna Rungta For our web scraping purposes, what matters most is that it supports Firefox, Edge, Safari, and Chrome, via their webdrivers that need to be installed separately. A webdriver is a control interface for the browser, a sort of "remote controller" for browsers. On a high level, a typical web scraper works like the following: Selenium WebDriver receives a command from the scraper Commands are converted into an HTTP request by the JSON wire protocol. Before executing any test cases, every browser has its driver which initializes the server. The browser then starts receiving the request through its driver. What Is Playwright? is an open-source Node.js library started by Microsoft for automating browsers based on Chromium, Firefox, and WebKit through a single API, created by the same team that was working on Puppeteer in Google. Playwright The primary goal of Playwright is to improve automated UI testing. It is, of course, very similar to Puppeteer, which works only with Chromium-based browsers and supports only Javascript language. In the automation test industry, Playwright got a lot of good feedback for its speed: about this, there's a that compares several frameworks for automation testing, including Selenium, Playwright, and Puppeteer. great benchmark by Checkly Its architecture is quite different from Selenium's one because it interacts directly with slightly modified versions of the browsers bundled with the installation package via API, without the need for a Webdriver. This makes the setup pretty straightforward but doesn't preclude the chance to interact with a standard Chrome instead of the bundled one. My Two Cents You could have noticed that I often mentioned Puppeteer but it is not in the scope of this post. This is because it can be programmed only in Javascript and not in Python, which is the language I prefer. Yes, there is Pyppeteer but it's an unofficial porting in Python of Puppeteer, and still didn't try it. Restricting the comparison between Selenium and Playwright, my personal choice falls on the second one. The easy setup and maintenance make the difference in a large web scraping project and the integration with other packages like to avoid bot detections is quite straightforward. playwright_stealth Being able to jump from one browser to another without the need to install anything make the fixing of scrapers fast and gives plenty of options. You can also use an installation of Chrome using a persistent context, which means you can have a real user profile for the whole execution of your scraper. I’m leaving you where you can see how Playwright works and some code to test it. this great article by Scrapfly Thank you for reading The Web Scraping Club. This post is public so feel free to share it. Latest Posts in The Lab THE LAB #6: Changing Ciphers in Scrapy to avoid bans by TLS Fingerprinting THE LAB #5: The Lab #5 - Scraping Airbnb.com using GraphQL THE LAB #4: Scrapyd - how to manage and schedule a fleet of scrapers THE LAB #3: scraping Cloudflare protected websites THE LAB #2: scraping data from a website with Datadome and xsrf tokens THE LAB #1: scraping data from an app Also published here