





645 reads
Origin of Interface in Object Oriented Programming
by Pathik DesaiJanuary 24th, 2023





Too Long; Didn't Read
Program to Interface is a fundamental principle in Object Oriented Programming to build Software Applications that can change more easily and quickly. Interface is mostly viewed as a useful feature to write more maintainable code. However, the concept of Interface came around to solve a different problem: missing binary encapsulation in C++.


Program to Interface is a fundamental principle in Object Oriented Programming to build Software Applications that can change more easily and quickly. A lot of other principles and Design Patterns are based on the Program to Interface principle. Interface is mostly viewed as a useful feature for writing more maintainable code.
However, the concept of Interface came around to solve a different problem. Author Don Box has explained this in his book Essential COM in great detail. We will try to understand the gist of it in this post.
The explanation is in the context of C++. I am not a C++ programmer. I have covered high level explanation of the concepts here. If you are interested in details, I would recommend to refer to the first chapter of the book Essential COM
What lead to Interface
Before we go further, it is better to quickly refresh the role of a Compiler and a Linker in C++ as shown in Figure 1. Compiler converts C++ source code to assembly code, and the Linker then combines all assembly code and external libraries in to one executable or library file output.

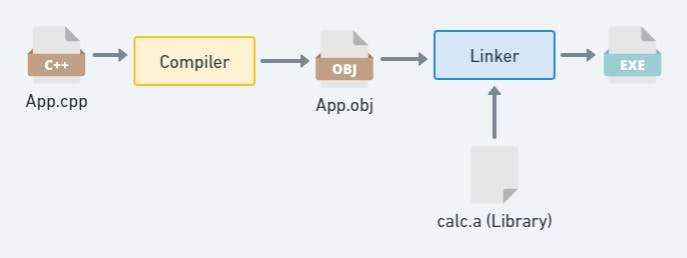
It is common to abstract out common logic or functionality into libraries. This makes the system modular and allows easy reuse.
Let's say there is a library named calclib implementing functions of a Calculator. Following is a subset of the functions:
// calc.h /////////////////////////////
class Calculator {
float pi;
public:
Calculator();
~Calculator(void);
float add(float a, float b); //add two numbers
} ;
This library is then used in CalcApp application by including the calc.h file in source code of CalcApp and providing calclib to the Linker which will generate CalcApp executable containing the calclib as shown in Figure 2.


This is called Static Linking. If there is any update to calclib, the CalcApp application has to be re-compiled and distributed again. Any change requires lot of effort and time. This can be a problem for libraries that are used in many applications.
This problem was solved with Dynamic Link Library (DLL). Such libraries are loaded at run time and the actual wiring of method calls (at binary level) happens when the Application is run. While building the application, the Linker would insert stubs in the application executable to make this possible. DLL makes it possible to just distribute new version of the library and the application will start working with updated version.


Let's say calclib 2.0 adds new feature of keeping last result in memory and allowing to retrieve it.
// calc.h /////////////////////////////
class Calculator {
float pi;
float lastResult; //added in v2.0
public:
Calculator();
~Calculator(void);
float add(float a, float b); //add two numbers
float getLastResult(); //added in v2.0
} ;
add method saves the result in lastResult
public float add(float a, float b) {
lastResult = a + b;
return lastResult;
}
There three changes to Calculator class in v2.0:
-
A new private member variable
lastResult -
A new public method
getLastResult -
Minor change to
addmethod implementation. Change does not alter the expected behavior for the client.
In theory, this should just work because none of these changes break anything for the client. But it doesn't! Here is why it doesn't work:
-
When an object of
Calculatorclass is created, memory is allocated based on its private members as shown in Figure 4.


-
When CalcApp was compiled with calclib 1.0, the Compiler would have generated code to allocate 4 bytes for one private member when compiling following code:
Calculator *c = new Calculator();
- Now when CalcApp runs with calclib 2.0, the Calculator object would have been allocated 4 bytes for one private member according to calclib 1.0 implementation. But the
addmethod in v2.0 tries to accesslastResultfor which no memory is allocated. So that causes an error.
That means making changes to a Class implementation that are private and have no impact on the publicly exposed functionality can also break the System. This is contrary to the principle of Encapsulation in Object Oriented Programming.
Don Box writes C++ supports syntactic encapsulation but
has no notion of binary encapsulation.
Root cause of the problem is that the memory allocation for an Object is determined by the Compiler at the time of compilation, and it is hard-wired in the binary output based on size of object at compile time, but with DLL the size of object can change resulting in errors when application is run with different version than it was compiled with.
The solution: separate the interface from the implementation and delegate responsibility of creating objects to the implementation. Let client refer only the interface as shown in Figure 5.

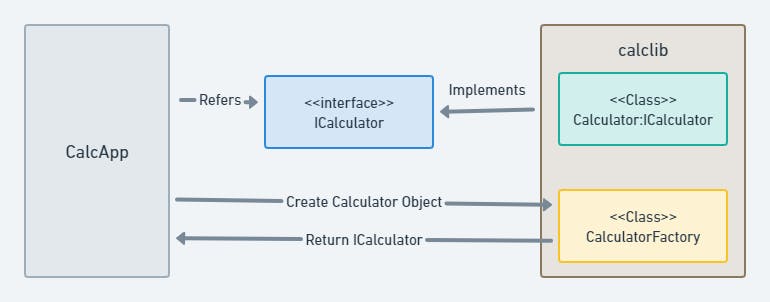
How Interface solves the problem?
-
Interface has only public method declaration. No private members or method implementation.
-
Factory is used to create an instance of the implementation so the implementation can change without breaking its clients e.g., adding a new private member variable in calclib 2.0 will not break clients compiled with earlier version because Factory in v2.0 will allocate appropriate memory.
This allows both the client and the library to change independently. Change in public method signature will break the clients. That's why an Interface is not modified once in use, but it is versioned to keep backward compatibility.
Interface in C++
Newer programming languages like Java, C#, etc. have explicit support for Interface. C++ has no built-in support for Interface, so Abstract class with only pure virtual functions are used to define an Interface.
Java (JVM languages) and C#
Dynamic loading of libraries is common in all newer programming languages like Java, C#, etc. But they do not face the problem we just discussed. Why? Two reasons:
-
All these languages are compiled to an intermediate code (Bytecode, IL Code) and this intermediate code is converted to machine code by the Runtime (JVM, CLR) when the application is run - Just-in-time compilation (JIT). Therefore, practically the linking process (or equivalent to that) happens on every execution. Any changes to a library will be picked up by the Runtime during execution.
-
The memory management is handled by the Runtime (JVM, CLR). The runtime can allocate appropriate memory depending on the latest implementation.
Hope you found this interesting. Please share your feedback in the comments.

L O A D I N G
. . . comments & more!
. . . comments & more!











