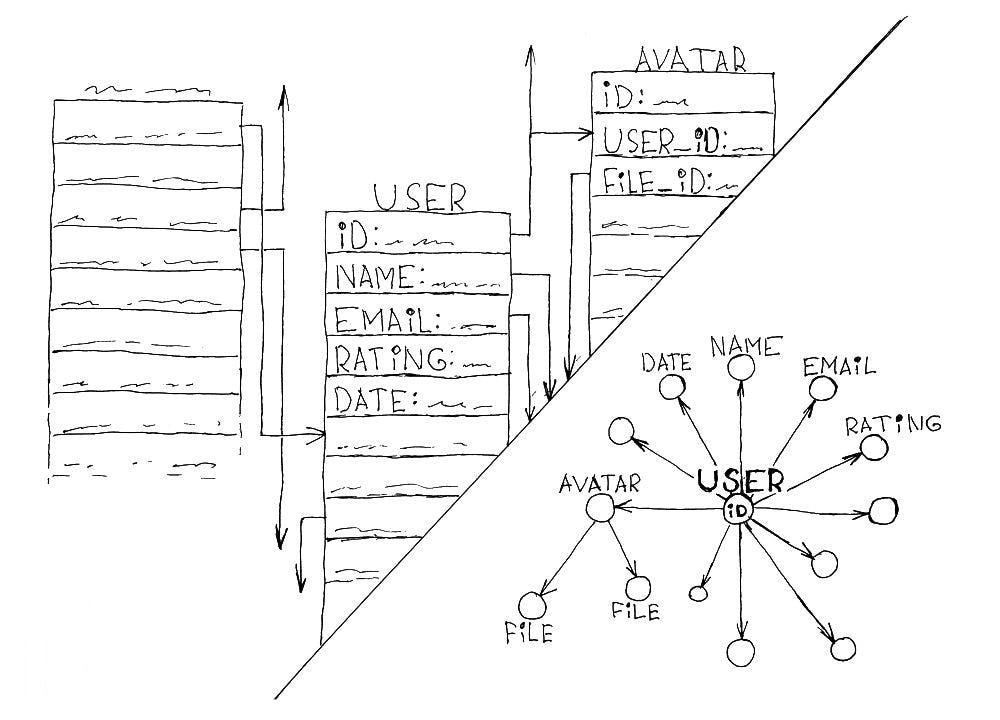
The article was translated by Deep Foundation’s co-founder Konstantin Dyachenko. In data science, code is dependent on data and models, and therefore on the abstractions used in them, so refactoring is inevitable today. Why? Usually, refactoring means changes in your code needed in order to use data in a new way. We'll talk about the most common and least favorite type of refactoring that causes the snowball effect. It occurs when data models, table structures, and business logic are changed. The Deep's philosophy describes everything using the concept of a Link. Any object is a Link, any relationship is a Link. The relationship always has and fields specified. In an independent object, and fields are not specified. This also distinguishes Deep's philosophy from graph databases, where edge cannot serve as an object of relationships. from to from to What can be changed depending on data models? Fields renaming. Changing of one to one/many relationships Adding abstractions Deprecating abstractions You can always try to patch up backward compatibility issues by adding new adapters and layers. But this fight against symptoms will only postpone the consequences of the real problem. With every change in business logic, the onion effect will only grow. And there will be more abstractions that are intertwined with each other. Many programmers will argue - this is a matter of clean code culture. We disagree. The culture of clean code is only about its implementation. The problem is not how we write the code, no matter how much we want to believe it. The problem is that it is, in principle, dependent on abstractions of business logic. Programmers are trying to fix the consequences of this problem, and it does not reduce the complexity of the code, but only multiplies it. At the same time, programmers surround themselves with imaginary feelings of comfort and control over the situation. Deep.Case aims to defeat this enemy. Data models can evolve without refactoring at all. How? In order to explain, we'll have to dig to the root causes of problems. Renaming of fields There are many types of code architecture. You can use GraphQL and schema generators, or you can map APIs and data abstractions through the ORM/ODM yourself, forwarding table rules to your code. You can have functional API and REST API from the server. But, probably, in any case, the way of working with these APIs will be defined either at the API level or at the level of column names in tables. Thus, we compensate for the induced changes by paying developers to update the database, generators, resolvers, and APIs. The problem here is the separation of the implementation of the functionality and its integration into the business logic. This one layer of abstraction is multiplied by the intersection of the business logic rules, and the number of ways columns are connected, ultimately making the price of each wave of refactoring highly dependent on the age of the project. It was not possible to accurately calculate the dependency factor, but this price always turns out to be multiple times greater than the cost of only the field modification and behavior changes in the business scenario. Here, you must also always take user permissions and any other business rules into account. This increases the cost of such waves of refactoring in multiples of the number of business rules. Deep.Case allows you to completely forget about this problem! Changing one to one/many relationships No matter how we indulge ourselves in the illusion of being able to predict everything, this is obviously not the case. Even the most ideal model will change. What we considered a single connection would become multiple. What we considered to be multiple will begin to be referenced from several places. Models conceived for use in some places become necessary to be applied in many others. Every such change today requires developer involvement, again and again. With data is divided into: Deep.Case links used as nodes (objects|points) answering the question, such as payment, volume, need, moment, and other WHAT links used as relationships (links) answering the question, such as X wants Y, W watched Z, T owns R, T answers P HOW IS RELATED Custom tables supplied by data models, accessible from a node of the corresponding type. The purpose of such tables is storage of custom non-referenced data that is more convenient to describe by a separate table. Links describing relationships are not initially limited by the system as one or many. Rules for creating links of each type can be described at the model level, and subsequently easily changed. This means that for a transition from to , it is enough to allow the creation of multiple links of a certain type. one many It is recommended that all handlers and client interfaces assume the iterability of each subset. It is very cheap to take this into account in initial development. Even if we think that there is only one instance of this type of link, we must assume that there can be many of them. Adding new levels of abstraction For example, when you need to create a new type of link and new entities. With Deep.Case, you no longer need to go through a full cycle of changing data structures, ORM/ODM models, or take into account how the code reflects the required abstractions, and its inflexibility slows down changes in business logic. Just create a new type of link and describe under what circumstances this link can be created and changed in the surrounding space. It will immediately become available through a single GraphQL/REST API without damaging the old abstractions and links, and therefore the dependent code. You no longer need a backend developer for this kind of change. Deprecation of old levels of abstraction Since there is no longer a self-written API resolver layer, the deprecation of old abstractions is reduced to a recommendation not to use certain links . But since some subset of interfaces and handlers can be tied to their existence, their existence can simply be maintained at the database level. Even if the package that supplies the data model wants to switch to a different type of links, nothing prevents, while creating new links, from maintaining mirror structures that are based on these links. in the new code Support associative technologies We create a development environment (boxed CE / EE version and SaaS version), which allows you to use data storage for solving your business problems with the ability to adapt to any business changes using an associative approach. We will create a distributed network of server clusters in a single associative space including so as not to think about regional legislation when creating a project. We create a culture of publishing reusable data models with their behavior. Join our community on . Sign up for early access on our Waitlist or support us on . Discord Patreon , you can find links to drafts of future articles in development, links to code sources, plans for project and product management, and invest presentations. On our site