





74,950 reads
More than a Million Pro-Repeal Net Neutrality Comments were Likely Faked





Too Long; Didn't Read
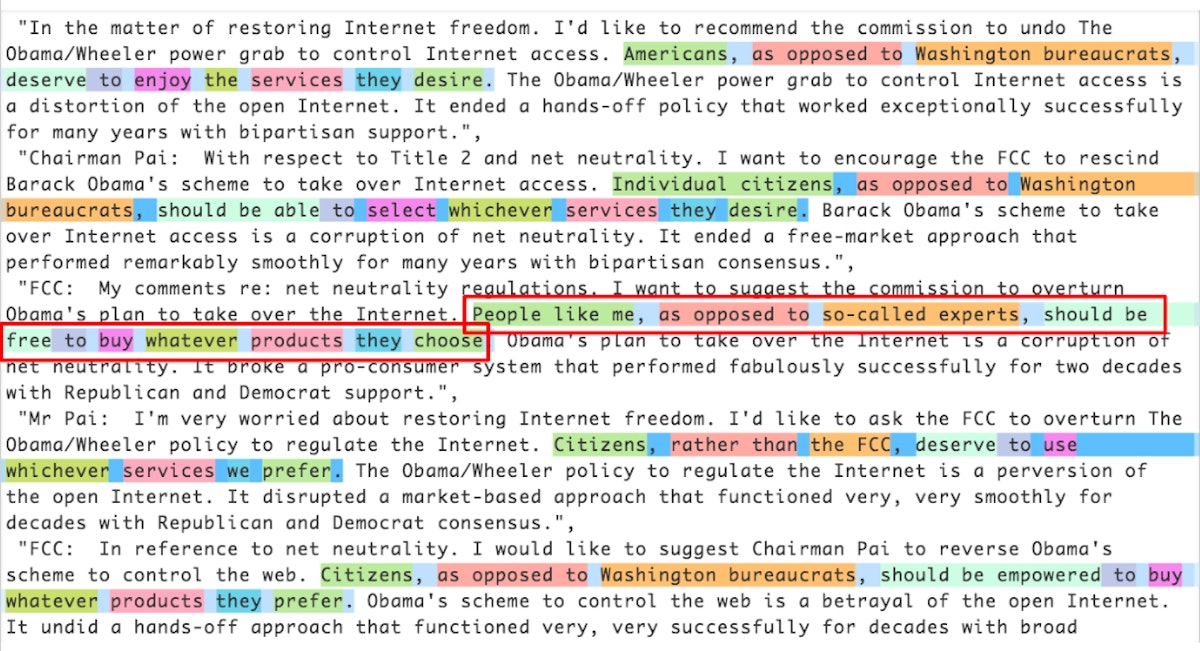
<em>[Update on 11–29–2017: I’ve posted multiple </em><a href="https://www.kaggle.com/jeffkao/proc_17_108_unique_comments_text_dupe_count" target="_blank"><em>datasets</em></a><em> and my </em><a href="https://github.com/j2kao/fcc_nn_research" target="_blank"><em>code</em></a><em> containing enough for you to reproduce the analysis. Please share with the rest of us what else you find — *gets on soapbox* — a free internet will always be filled with competing narratives, but well-researched, reproducible data analyses can establish a ground truth and help cut through all of that. Look forward to seeing your analyses & there will be more data to come!]</em>People Mentioned

Companies Mentioned



Jeff Kao
@jeffykao

L O A D I N G
. . . comments & more!
. . . comments & more!












