
75,860 reads
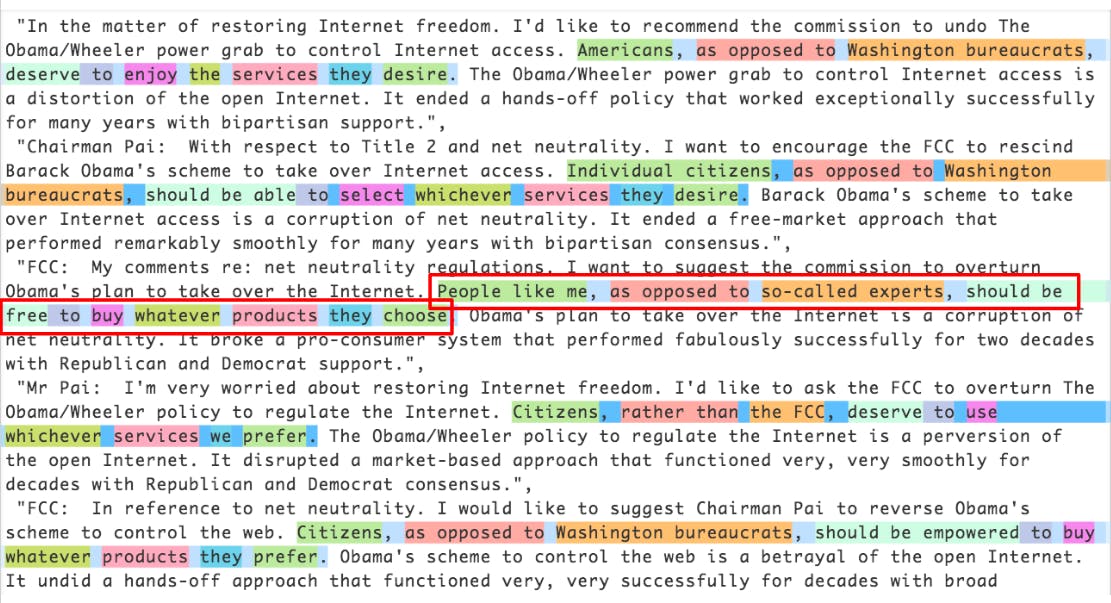
More than a Million Pro-Repeal Net Neutrality Comments were Likely Faked
by
November 22nd, 2017





Audio Presented by



About Author

Machine Learning Engineer
Comments

TOPICS
THIS ARTICLE WAS FEATURED IN


Arweave


ViewBlock

Related Stories



Ajit Pai is Lying
Dec 16, 2017





Ajit Pai is Lying
Dec 16, 2017