1,387 reads
Modernizing Secrets Scanning: Part 1–the Problem
by Nikolai KhechumovApril 21st, 2023





Too Long; Didn't Read
A secret is a common name for any sensitive information your application may need for internal use. This data must not be stored inside the source code, even if you have a self-hosted VCS. Instead, the right way to handle secrets is to store them in a special system like [Hashicorp Vault].


Hi! My name is Nikolai Khechumov, and I’m part of Avito’s Application Security team. We build and maintain our AppSec Platform — a set of company-wide tools and processes, including:
- Per-push code scanning system with pre-receive/post-receive and PR checks with automatic vulnerability tracking and management;
- Flexible threat modeling templates for feature teams;
- A full-fledged security champions program
We will cover all of this in our future articles. Stay tuned!
Today I'd like to share some new approaches to secret search at the scanner level.
What ‘secrets’ are, and why search for them?
A secret is a common name for any sensitive information your application may need for internal use. For example, this may be the credentials for databases, external systems, private keys, passwords for service accounts, etc. This data must not be stored inside the source code, even if you have a self-hosted VCS.
Instead, the right way to handle secrets is to store them in a special system like Hashicorp Vault. Your application's secrets should then be delivered into the application's container.
There should also be security awareness and training programs for developers. Still, there is always a chance of a mistake: people tend to commit secrets (intentionally or not) no matter how well you teach them. So any AppSec team has to scan old and new code for secrets inside it.
Existing tools and the root of their problems
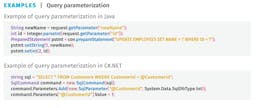
Security guys are, of course, familiar with tools like trufflehog or gitsecrets. They do a good job of finding “typed secrets” — those that have a recognizable format and can be found using basic regular expressions. For example, Slack's secrets start with xoxb.., cryptographic keys have header sequences like ===== BEGIN PRIVATE =====, etc.
At Avito, we have a lot of internal and external secrets without any recognizable format.
How should we find them? Claude Shannon whispers the sweet word “entropy” into our ears. Yes, we can calculate a value for any string, and existing tools also have this functionality. But entropy is very tricky: you have to be a janitor and play with threshold values. This noisy search method is pretty useless in large and old codebases like ours. It also has some funny side effects.
Let's look at several scenarios and understand the root cause of the problem.
Case 1


Assuming we have a string that definitely has ‘large’ entropy, let's put that string into a different context:


Oops. And now we have a clear false positive. Of course, we can start analyzing the context by adding new checks and regexes, but these measures will not always work: you will constantly stumble upon new uncovered situations.
Case 2


In this example, we just don't have enough data to reach entropy thresholds. And once again, we have a clear hint from the context - the ‘pwd’.
Case 3
The most striking example.


It's funny, but the trufflehog found 2 secrets here (marked red)


Let's go a little bit deeper here.
All secret scanning tools try to break up a file into small pieces and then analyze them. How do they do that? Yellow markings in the picture above show how exactly they split a file: primarily by spaces and line breaks. And this is the main problem.
Current secrets finders understand files only as a stream of bytes. They know nothing about the semantics of the content inside, so they cannot find language-specific constructions before analysis. But this ability is pretty challenging to implement, so are there any other cases when this knowledge can also be helpful?
Case 4
Another way to find secrets is to take your already known secrets from Vault/AD/etc. and try finding something similar inside the source code.
This approach may seem dangerous, and it is actually dangerous, so I encourage you to be very careful if you decide to try this technique.
So we won't cover comparing plaintext to plaintext (never do that!) - that's obvious. But how can we use a hashed secret as a reference? What should we hash inside our code to compare with the reference hash?
Original Secret: ?
Hashed Secret: a515942cd6d0004f33ad8f327be4343fde8e81ce8e64420cd465d075289cd268
Should we use a rolling hash window? If so, how wide should it be? Or should we continue dividing by spaces and line breaks? Then quotation marks will remain a part of strings, and the hashes will not match. Okay, let's also start breaking by quotation marks. But some passwords may include quotations legally. So that's not really the right direction.
So we have a set of questions to answer:
- How can we decrease the number of strings to be analyzed (exclude language keywords, punctuation, syntax, etc.)?
- How do we detect constructions that can contain a secret in any given language? E.g. string variables, strings in dictionaries, comments, etc.
Looks like we should go deeper and learn to represent a text as a code in a given language.
Language understanding
The obvious question is how tools understand languages and formats. Compilers and tools called SAST (Static Application Security Testing) often build a tree representation of code called an Abstract Syntax Tree. It has all the needed context about code: variables, their names, and values. We will talk about it a little later; for now, it is enough just to be aware of it as is. So we intend to build something similar that works fast and with maximum coverage of available languages.
Should we hack the internal machinery of a SAST?
No. It's not extendable; it covers only one language and is simply overkill. Furthermore, SAST tools don't work well with separate files without dependencies.
Are there any AST builders?
Yes, but no. We write our internal tooling in Python and could not find enough reliable libraries to build ASTs for other languages. Besides, the libraries we found are mostly abandoned and lack support even for their language.
Can we somehow reuse a native parser of a language X?
In theory, yes, but imagine a code-scanning service that depends on dozens of runtimes at the same time and yet again tries to hack their internal machinery to extract an AST. Sounds like nonsense.
What about Language Servers?
We use code editors like VSCode or VIM, and they understand languages thanks to language servers. The idea behind a Language Server is to have a standalone process that other tools can communicate with using the language protocol (LSP). At first glance, this looks like a win-win situation: just install all language servers you can find and use a friendly standardized protocol to query per-language smarts. Moreover, ‘Semantic tokens’ are now also a part of the standard.




But again, no. At least for now. This thing is not mature at the moment, and open-source language servers mostly don't support semantic tokens.
Nice but proprietary servers like Pylance cannot be run standalone because of license limitations.


Other open-source servers have lacked support for years


Some have performance issues.


And still, we have to run N servers for decent language support.
Right now, it seems that nothing helps us.
But in the next part, we'll find an elegant solution that has been under our noses all this time.
The featured image for this piece was generated with stable diffusion v2.1
Prompt: Illustrate a computer screen with the caution symbol.

L O A D I N G
. . . comments & more!
. . . comments & more!