441 reads
Machine learning: preventing unintended consequences





Too Long; Didn't Read
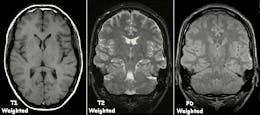
TGIF, I’m heading home from work and looking forward to the weekend. I find a seat on the train, bite into my sandwich and open Candy Crush. I haven’t played it since Monday. I have been stuck at level 76 and had given up.Company Mentioned




Avinash Royyuru
@roy100

L O A D I N G
. . . comments & more!
. . . comments & more!