Retrieval systems have existed for over a century, and we have all used them in some form either by searching for something on Google or querying ChatGPT with prompts. With the rise of large language models, it has become easier than ever to find answers to your questions but a problem arises when your question is outside the model's knowledge cut-off or domain.
The solution is to provide more context to the model, and the easiest form this takes is by including the relevant context within your prompt. Another common approach is to provide an external data source. This is where Retrieval Augmented Generation (RAG) comes in.
RAG is a technique that provides LLMs with relevant information from external sources such as the internet or a database. A RAG system has two parts to it: a retriever which retrieves relevant documents that will be used to augment a user's query and a generator that generates a response based off the augmented query. A high-level overview of a RAG system looks like this:
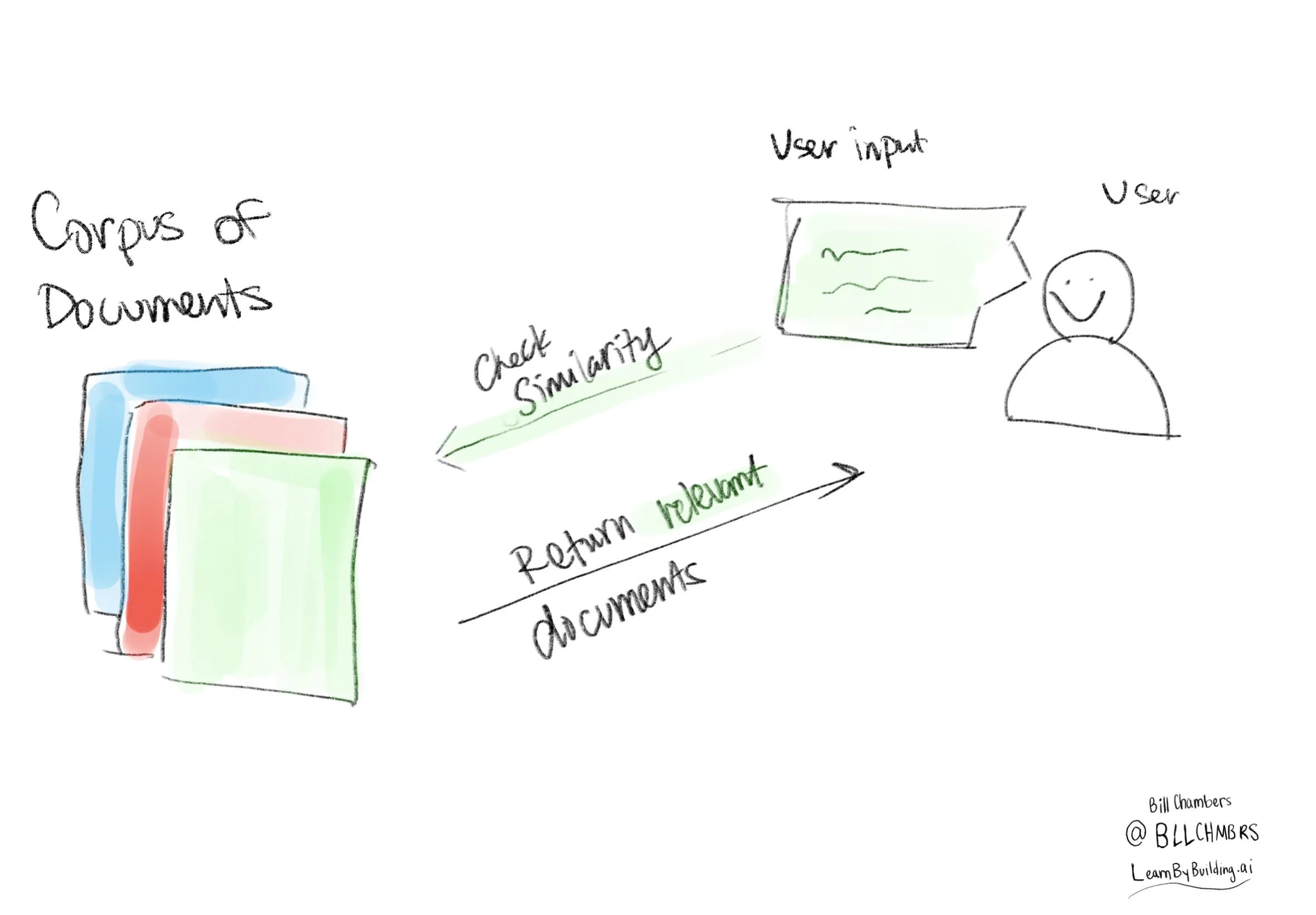{kind=link}
Context length is another thing to consider when building RAG systems. Research shows that performance degrades significantly as context grows:
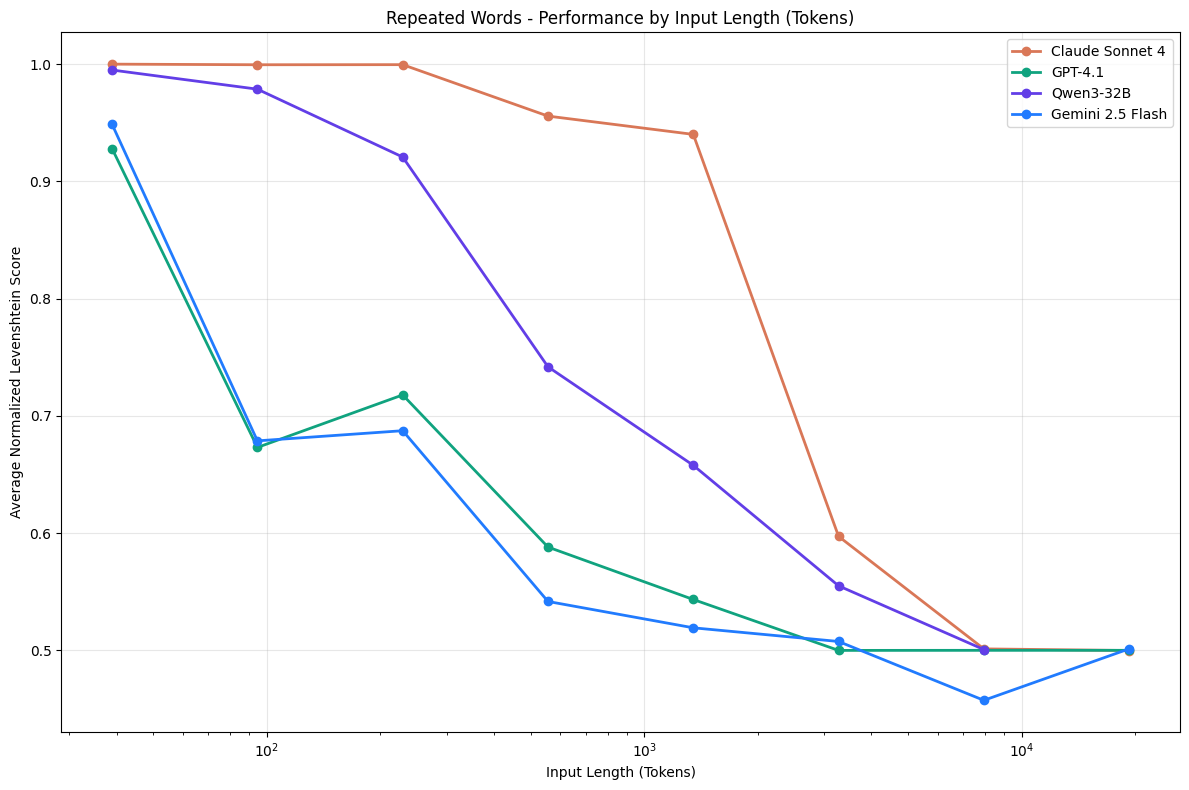{kind=link}
A popular benchmark that tests this in LLMs is the Needle in a Haystack (NIAH) benchmark. A simple retrieval test where a known sentence (the needle) is placed in a large document of unrelated text (the haystack). Interestingly, despite research showing performance drops as context grows, all the popular models with million context windows achieve near-perfect scores on the test. This is because NIAH tests direct lexical matching which in most cases, does not represent semantically oriented tasks.
A solution then is to periodically create summary instances of your context, so you can prune any corrupted or redundant tokens and prioritize relevance when designing your retrieval systems. When designing these systems, especially with large context or frequent summarization, consider scalability (both horizontal and vertical) from the start.
If you're interested in reading more on context rot, check that out here.
updates under the fold
I built a local RAG system that lets you chat with PDFs and get cited answers.
Until next time,
Victor.