




17,367 reads
Let the code speak!





Too Long; Didn't Read
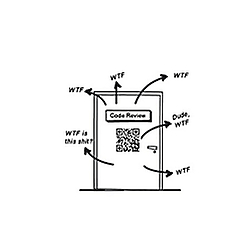
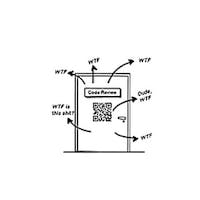
Have you ever seen code like this?People Mentioned

Companies Mentioned



The Code Gang
@the-code-gang

L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
TOPICS
THIS ARTICLE WAS FEATURED IN...



RELATED STORIES





You Don’t Need JavaScript Native Methods! #javascript
Apr 19, 2024


Events in C#: An Easy-to-Understand Guide #c-sharp
Apr 18, 2024

