

























Claude Sonnet 3.5 系统提示泄漏:法医分析


Jan 20, 1970

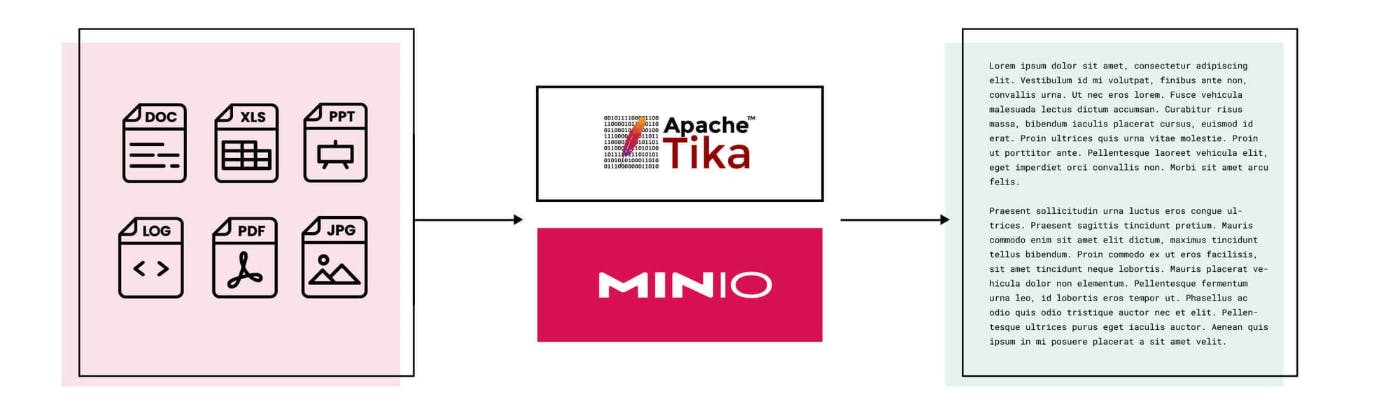
MinIO is a high-performance, cloud-native object store that runs anywhere (public cloud, private cloud, colo, onprem).


MinIO is a high-performance, cloud-native object store that runs anywhere (public cloud, private cloud, colo, onprem).
MinIO is a high-performance, cloud-native object store that runs anywhere (public cloud, private cloud, colo, onprem).

Jan 20, 1970
Jan 20, 1970
Jan 20, 1970
Jan 20, 1970
Jan 20, 1970
Jan 20, 1970




