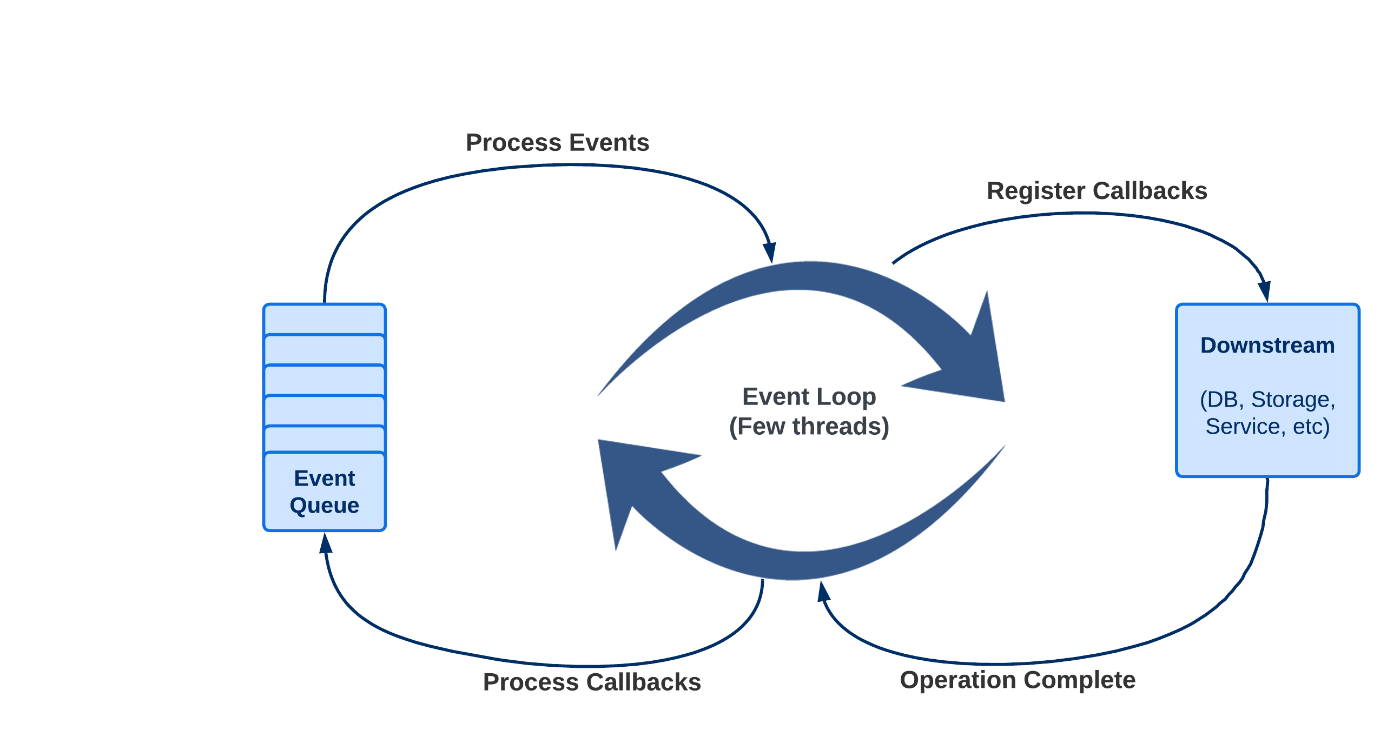
Spring 是一个反应式、非阻塞的 Web 框架,用于在 Java 中构建现代的、可扩展的 Web 应用程序。它是 Spring Framework 的一部分,它使用 Reactor 库在 Java 中实现反应式编程。 WebFlux 使用 WebFlux,您可以构建高性能、可扩展的 Web 应用程序,这些应用程序可以处理大量并发请求和数据流。它支持广泛的用例,从简单的 REST API 到实时数据流和服务器发送的事件。 Spring WebFlux 提供了一种基于反应流的编程模型,它允许您将异步和非阻塞操作组合到数据处理阶段的管道中。它还为构建反应式 Web 应用程序提供了一组丰富的功能和工具,包括对反应式数据访问、反应式安全和反应式测试的支持。 来自 : 官方 Spring 文档 术语“反应式”指的是围绕对变化做出反应而构建的编程模型——网络组件对 I/O 事件做出反应,UI 控制器对鼠标事件做出反应,等等。从这个意义上说,非阻塞是反应性的,因为我们现在处于操作完成或数据可用时对通知做出反应的模式,而不是被阻塞。 线程模型 反应式编程的核心特征之一是它的线程模型,它不同于许多同步 Web 框架中使用的传统的每个请求线程模型。 在传统模型中,创建一个新线程来处理每个传入的请求,并且该线程被阻塞,直到请求被处理。在处理大量请求时,这可能会导致可伸缩性问题,因为处理请求所需的线程数量可能会变得非常大,并且线程上下文切换可能成为瓶颈。 相比之下,WebFlux 采用非阻塞、事件驱动的模型,少量的线程可以处理大量的请求。当请求进入时,它由一个可用线程处理,然后将实际处理委托给一组异步任务。这些任务以非阻塞方式执行,允许线程在后台执行任务的同时继续处理其他请求。 在 Spring WebFlux(以及一般的非阻塞服务器)中,假定应用程序不会阻塞。因此,非阻塞服务器使用一个小的、固定大小的线程池(事件循环工作者)来处理请求。 经典 Servlet 容器的简化线程模型如下所示: 虽然 WebFlux 请求处理略有不同: 在引擎盖下 让我们继续看看闪亮的理论背后是什么。 我们需要一个由 生成的非常简约的应用程序。该代码在 中可用。 Spring Initializr GitHub 存储库 所有与线程相关的主题都非常依赖 CPU。通常,处理请求的处理线程数与 数有关 出于教育目的,您可以在运行 Docker 容器时通过限制 CPU 轻松地操纵池中的线程数: CPU 核心 。 docker run --cpus=1 -d --rm --name webflux-threading -p 8081:8080 local/webflux-threading 如果您仍然在池中看到多个线程 - 没关系。 WebFlux 可能设置了 。 默认值 我们的应用程序是一个简单的算命先生。通过调用 端点,您将获得 5 条带有 记录。每个调整都是一个整数,代表给你的业力。是的,我们非常慷慨,因为该应用程序只生成正数。没有坏运气了! /karma balanceAdjustment 默认处理 让我们从一个非常基本的例子开始。下一个控制器方法返回一个包含 5 个业力元素的 Flux。 @GetMapping("/karma") public Flux<Karma> karma() { return prepareKarma() .map(Karma::new) .log(); } private Flux<Integer> prepareKarma() { Random random = new Random(); return Flux.fromStream( Stream.generate(() -> random.nextInt(10)) .limit(5)); } 方法在这里很重要。它观察所有 Reactive Streams 信号并将它们跟踪到 INFO 级别下的日志中。 log curl 上的日志输出如下: localhost:8081/karma 正如我们所见,处理发生在 IO 线程池上。线程名称 代表 。任务在提交它们的线程上立即执行。 Reactor 没有看到任何将它们安排在另一个池上的说明。 ctor-http-nio-2 reactor-http-nio-2 延迟和并行处理 下一个操作将延迟每个元素发射 100 毫秒(又名数据库模拟) @GetMapping("/delayedKarma") public Flux<Karma> delayedKarma() { return karma() .delayElements(Duration.ofMillis(100)); } 我们不需要在这里添加 方法,因为它已经在原始的 调用中声明过。 log karma() 在日志中我们可以看到下图: 这次在 IO 线程 上只接收到第一个元素。其余 4 个的处理专用于 线程池。 reactor-http-nio-4 parallel 的 Javadoc 证实了这一点: delayElements 信号被延迟并在并行默认调度程序上继续 您可以通过在调用链中的任何位置指定 来毫不延迟地实现相同的效果。 .subscribeOn(Schedulers.parallel()) 使用 调度器可以通过允许多个任务在不同线程上同时执行来提高性能和可扩展性,从而可以更好地利用 CPU 资源并处理大量并发请求。 parallel 但是,它也会增加代码复杂性和内存使用量,如果超过最大工作线程数,则可能导致线程池耗尽。因此,使用 线程池的决定应根据应用程序的具体要求和权衡取舍。 parallel 子链 现在让我们来看一个更复杂的例子。代码仍然非常简单明了,但输出更有趣。 我们将使用 让算命先生更加 。对于每个 Karma 实例,它会将原始调整乘以 10 并生成相反的调整,从而有效地创建一个平衡交易来补偿原始交易。 flatMap 公平 @GetMapping("/fairKarma") public Flux<Karma> fairKarma() { return delayedKarma() .flatMap(this::makeFair); } private Flux<Karma> makeFair(Karma original) { return Flux.just(new Karma(original.balanceAdjustment() * 10), new Karma(original.balanceAdjustment() * -10)) .subscribeOn(Schedulers.boundedElastic()) .log(); } 如您所见, Flux 应该订阅了一个 线程池。让我们检查一下前两个 Karmas 的日志中的内容: makeFair's boundedElastic Reactor 在 IO 线程上订阅 的第一个元素 balanceAdjustment=9 然后 池通过在 线程上发出 和 调整来处理 Karma 公平性 boundedElastic boundedElastic-1 90 -90 第一个之后的元素在并行线程池上订阅(因为我们在链中仍然有 ) delayedElements 什么是有 boundedElastic 调度程序? 它是一个线程池,可以根据工作负载动态调整工作线程的数量。它针对 I/O 密集型任务(例如数据库查询和网络请求)进行了优化,旨在处理大量短期任务,而不会创建太多线程或浪费资源。 默认情况下, 线程池的最大大小 可用处理器数乘以 10,但您可以根据需要将其配置为使用不同的最大大小 boundedElastic 为 通过使用像 这样的异步线程池,您可以将任务卸载到单独的线程并释放主线程来处理其他请求。线程池的有界特性可以防止线程饥饿和过度使用资源,而池的弹性允许它根据工作负载动态调整工作线程的数量。 boundedElastic 其他类型的线程池 开箱即用的 类提供了另外两种类型的池,例如: Scheduler :这是一个单线程、序列化的执行上下文,专为同步执行而设计。当您需要确保任务按顺序执行并且没有两个任务同时执行时,它很有用。 single :这是一个简单的、无操作的调度程序实现,它立即在调用线程上执行任务而无需任何线程切换。 immediate 结论 Spring WebFlux 中的线程模型被设计为非阻塞和异步的,允许以最少的资源使用高效地处理大量请求。 WebFlux 不依赖于每个连接的专用线程,而是使用少量事件循环线程来处理传入请求并将工作分配给来自各种线程池的工作线程。 但是,为您的用例选择正确的线程池以避免线程饥饿并确保有效使用系统资源非常重要。