
104 leituras
Descobrindo as projeções de energia solar: análise do modelo bayesiano entre as estações
by byQuantification Theory Research Publication@quantification
byQuantification Theory Research Publication@quantification
The publication about the quantity of something. The theory about why that quantity is what is. And research!
2024/02/02


















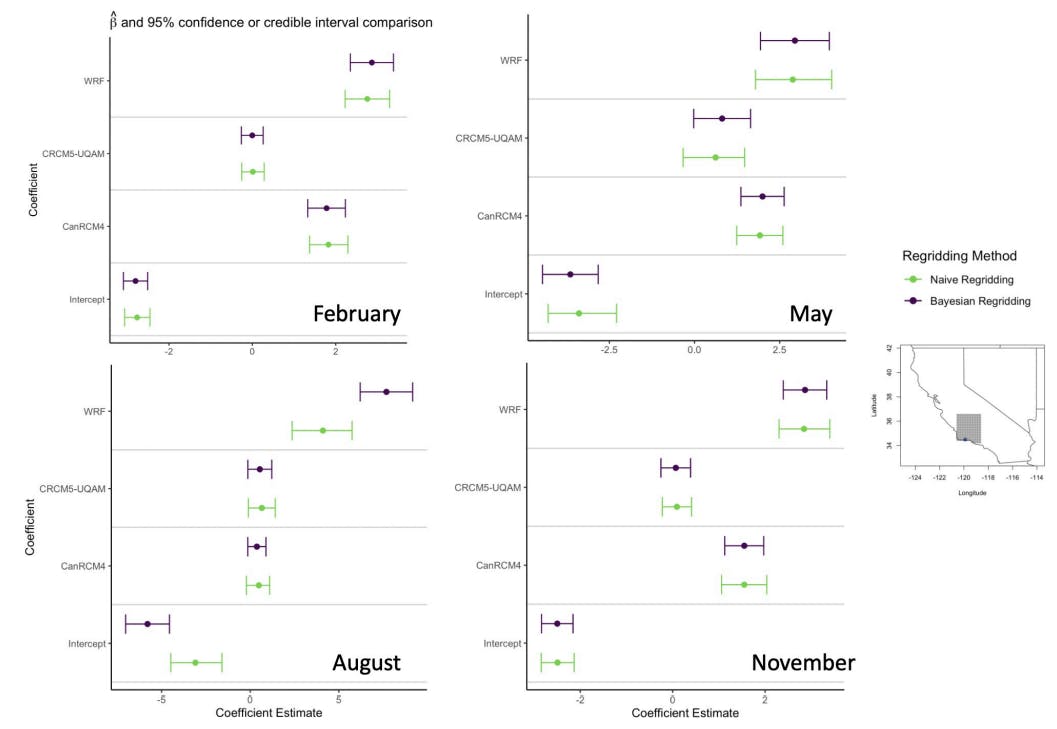
The publication about the quantity of something. The theory about why that quantity is what is. And research!


The publication about the quantity of something. The theory about why that quantity is what is. And research!
About Author

The publication about the quantity of something. The theory about why that quantity is what is. And research!
COMENTARIOS












