


























Floki의 Valhalla가 인도 스리랑카 투어의 보조 후원자로 합류


Jan 20, 1970
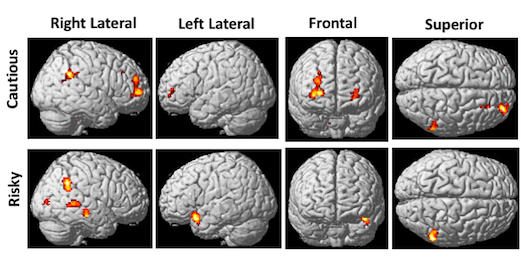
theorizing the human mind, based on the electrical and chemical signals of neurons. https://bitly.cx/uLMc

theorizing the human mind, based on the electrical and chemical signals of neurons. https://bitly.cx/uLMc
theorizing the human mind, based on the electrical and chemical signals of neurons. https://bitly.cx/uLMc






