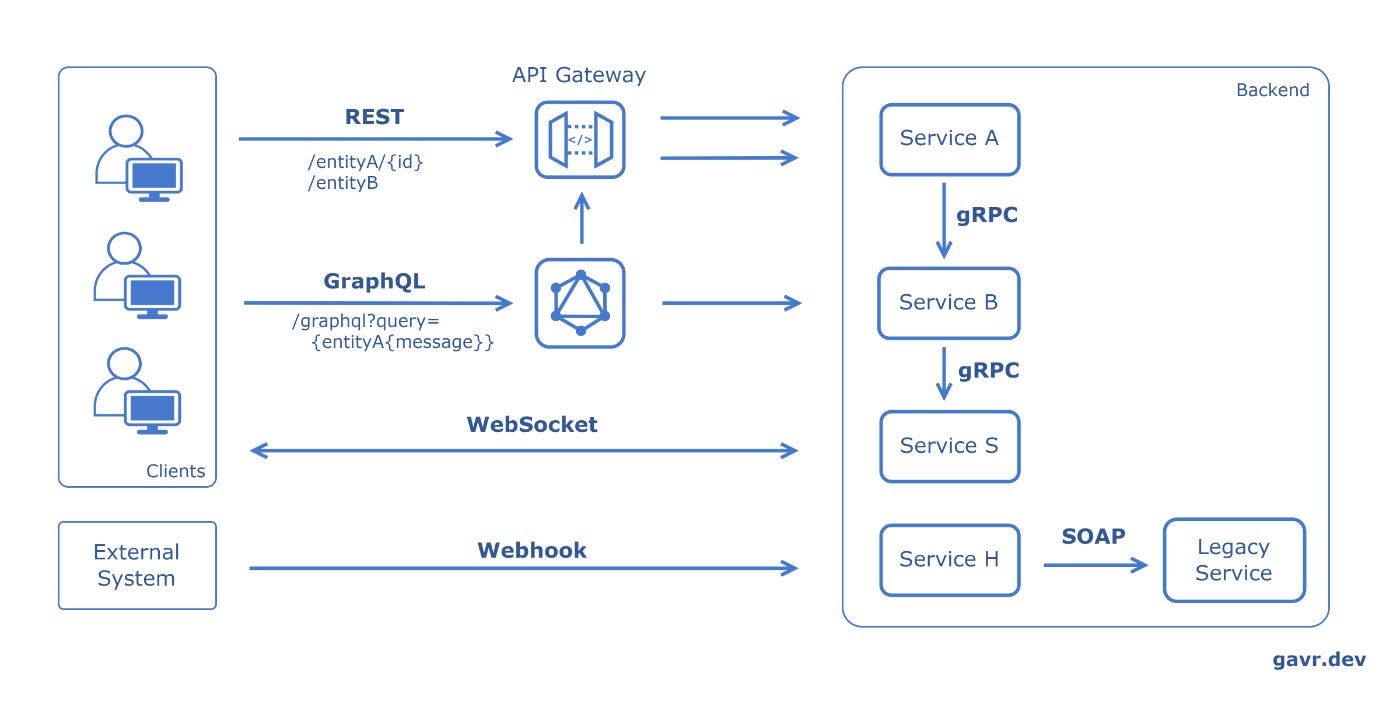
Ceci est la suite d'une série d'articles dans lesquels je couvre brièvement les principaux points d'un sujet spécifique de la conception d'architecture système. Le premier article peut être lu ici L'architecture API fait référence à l'ensemble de règles, de protocoles et d'outils qui dictent la manière dont les composants logiciels doivent interagir. L'architecture d'une API ne vise pas seulement à faciliter la communication ; il s'agit également de garantir que cette communication est efficace, sécurisée et évolutive. Une architecture API bien conçue peut améliorer considérablement les performances d'un système, tandis qu'une architecture mal conçue peut entraîner des goulots d'étranglement, des vulnérabilités de sécurité et des cauchemars de maintenance. Différents styles d'architecture API Les styles de conception d'API les plus courants : (Representational State Transfer) est le style le plus utilisé qui utilise des méthodes standards et des protocoles HTTP. Il est basé sur des principes tels que l'apatridie, l'architecture client-serveur et la mise en cache. Il est souvent utilisé entre les clients front-end et les services back-end. REST est un langage de requête pour les API. Contrairement à REST, qui expose un ensemble fixe de points de terminaison pour chaque ressource, GraphQL permet aux clients de demander exactement les données dont ils ont besoin, réduisant ainsi la récupération excessive. GraphQL est un protocole permettant une communication bidirectionnelle sur TCP. Les clients utilisent des sockets Web pour obtenir des mises à jour en temps réel des systèmes back-end. WebSocket est un mécanisme qui permet à un système d'informer un autre système d'événements spécifiques en temps réel. Il s'agit d'un rappel HTTP défini par l'utilisateur. Webhook est un protocole qu'un service peut utiliser pour demander une procédure/méthode à un service situé sur un autre ordinateur d'un réseau. Habituellement, il est conçu pour une communication à faible latence et à haut débit. RPC (gRPC) est un protocole d'échange d'informations structurées pour implémenter des services Web. Il s'appuie sur XML et est connu pour sa robustesse et ses fonctionnalités de sécurité, actuellement considérées comme un protocole hérité. SOAP Examinons chaque protocole séparément avec tous ses avantages, inconvénients et cas d'utilisation. REPOS est un style architectural qui utilise des conventions et des protocoles standards, ce qui le rend facile à comprendre et à mettre en œuvre. Sa nature apatride et son utilisation de méthodes HTTP standard en font un choix populaire pour créer des API Web. REST Alors que REST est depuis longtemps le standard de facto pour la création d'API, d'autres styles comme GraphQL ont émergé, offrant différents paradigmes pour interroger et manipuler les données. : XML, JSON, HTML, texte brut Format : HTTP/HTTPS Protocole de transport Concepts et caractéristiques clés : En REST, tout est une ressource. Une ressource est un objet avec un type, des données associées, des relations avec d'autres ressources et un ensemble de méthodes qui fonctionnent sur lui. Les ressources sont identifiées par leurs URI (généralement une URL). Ressource : les services REST mappent souvent directement aux opérations CRUD (Créer, Lire, Mettre à jour, Supprimer) sur les ressources. Opérations CRUD : les systèmes REST utilisent des méthodes HTTP standards : Méthodes HTTP GET : Récupérer une ressource. POST : créez une nouvelle ressource. PUT/PATCH : Mettre à jour une ressource existante. SUPPRIMER : Supprimer une ressource. : les API REST utilisent des codes d'état HTTP standard pour indiquer le succès ou l'échec d'une requête API : Codes d'état 2xx - Reconnaissance et réussite 200 - D'accord 201 - Créé 202 - Accepté 3xx - Redirection 301 Déménagé Définitivement 302 - Trouvé 303 - Voir Autre 4xx - Erreur client 400 - Requête incorrecte 401 - Non autorisé 403 - Interdit 404 - Introuvable 405 - Méthode non autorisée 5xx - Erreur de serveur 500 - Erreur de serveur interne 501 - Non mis en œuvre 502 Mauvaise passerelle 503 Service Indisponible 504 portail expiré : Chaque requête d'un client vers un serveur doit contenir toutes les informations nécessaires à la compréhension et au traitement de la requête. Le serveur ne doit rien stocker sur l'état du client entre les requêtes. Stateless : REST est basé sur le modèle client-serveur. Le client est responsable de l'interface utilisateur et de l'expérience, tandis que le serveur est responsable du traitement des demandes, de la gestion de la logique métier et du stockage des données. Client-Serveur : les réponses du serveur peuvent être mises en cache par le client. Le serveur doit indiquer si une réponse peut être mise en cache ou non. Cacheable : un client ne peut généralement pas savoir s'il est connecté directement au serveur final ou à un intermédiaire. Les serveurs intermédiaires peuvent améliorer l'évolutivité du système en permettant l'équilibrage de charge et en fournissant des caches partagés. Système en couches Hypermedia As The Engine Of Application Stat est un principe de service Web REST qui permet aux clients d'interagir et de naviguer dans une application Web entièrement basée sur l'hypermédia fourni dynamiquement par le serveur dans ses réponses, favorisant ainsi le couplage lâche et la découvrabilité. HATEOAS : Cas d'utilisation : De nombreux services Web exposent leurs fonctionnalités via des API REST, permettant aux développeurs tiers d'intégrer et d'étendre leurs services. Services Web : les applications mobiles communiquent souvent avec des serveurs backend à l'aide d'API REST pour récupérer et envoyer des données. Applications mobiles : les SPA utilisent des API REST pour charger dynamiquement du contenu sans nécessiter une actualisation complète de la page. Applications à page unique (SPA) les systèmes au sein d'une organisation peuvent communiquer et partager des données à l'aide des API REST. Intégration entre les systèmes : Exemple Demande OBTENIR «/utilisateur/42» Réponse { "id": 42, "name": "Alex", "links": { "role": "/user/42/role" } } GraphQL offre une approche plus flexible, robuste et efficace pour créer des API, en particulier dans les systèmes complexes ou lorsque le frontend a besoin d'une grande flexibilité. Il transfère une partie de la responsabilité du serveur au client, permettant à ce dernier de spécifier ses besoins en matière de données. GraphQL Bien qu'il ne remplace pas REST dans tous les scénarios, il offre une alternative intéressante dans de nombreuses situations, en particulier à mesure que les applications deviennent de plus en plus mises en réseau et distribuées. : JSON Format : HTTP/HTTPS Protocole de transport Concepts et caractéristiques clés : il permet aux clients de demander les données dont ils ont besoin, permettant ainsi d'obtenir toutes les informations requises en une seule requête. Langage de requête pour les API : les API GraphQL sont organisées en termes de types et de champs, et non de points de terminaison. Il utilise un système de types fort pour définir les capacités d'une API. Tous les types exposés dans une API sont écrits dans un schéma à l'aide du langage de définition de schéma (SDL) GraphQL. Système de types : contrairement à REST, où vous pouvez avoir plusieurs points de terminaison pour différentes ressources, dans GraphQL, vous exposez généralement un seul point de terminaison qui exprime l'ensemble complet des fonctionnalités du service. Point de terminaison unique : Côté serveur, les résolveurs rassemblent les données décrites dans une requête. Résolveurs : au-delà de la simple requête de données, GraphQL inclut une prise en charge intégrée des mises à jour en temps réel à l'aide d'abonnements. Mises à jour en temps réel avec abonnements : un serveur GraphQL peut être interrogé sur les types qu'il prend en charge. Cela crée un contrat solide entre le client et le serveur, permettant des outils et une meilleure validation. Introspective Cas d'utilisation : pour les applications (en particulier mobiles) avec une bande passante cruciale, vous souhaitez minimiser les données récupérées depuis le serveur. Frontends flexibles : une couche GraphQL peut être introduite pour agréger les données de ces services dans une API unifiée si vous disposez de plusieurs microservices. Agrégation de microservices : grâce à son système d'abonnement, GraphQL peut être un excellent choix pour les applications qui ont besoin de données en temps réel, comme les applications de chat, les mises à jour sportives en direct, etc. Applications en temps réel : avec REST, vous devez souvent versionner vos API une fois les modifications introduites. Avec GraphQL, les clients demandent uniquement les données requises, donc l'ajout de nouveaux champs ou types ne crée pas de modifications avec rupture. API sans version Exemple Demande GET "/graphql?query=user(id:42){ nom rôle { nom identifiant } }" Réponse { "data": { "user": { "id": 42, "name": "Alex", "role": { "id": 1, "name": "admin" } } } } WebSocket fournissent un canal de communication en duplex intégral sur une connexion unique de longue durée, permettant l'échange de données en temps réel entre un client et un serveur. Cela le rend idéal pour les applications Web interactives et hautes performances. Les WebSockets : Binaire Format : TCP Protocole de transport Concepts et caractéristiques clés : contrairement au modèle requête-réponse traditionnel, les WebSockets fournissent un canal de communication full-duplex qui reste ouvert, permettant l'échange de données en temps réel. Connexion persistante : les WebSockets démarrent sous la forme d'une requête HTTP, qui est ensuite mise à niveau vers une connexion WebSocket si le serveur la prend en charge. Cela se fait via l'en-tête « Upgrade ». Mise à niveau de la poignée de main : Une fois la connexion établie, les données sont transmises sous forme de trames. Des données textuelles et binaires peuvent être envoyées via ces trames. Trames : les WebSockets permettent une communication directe entre le client et le serveur sans avoir à ouvrir une nouvelle connexion pour chaque échange. Cela se traduit par un échange de données plus rapide. Faible latence : le client et le serveur peuvent s'envoyer des messages indépendamment. Bidirectionnel : après la connexion initiale, les trames de données nécessitent moins d'octets à envoyer, ce qui entraîne moins de surcharge et de meilleures performances que l'établissement répété de connexions HTTP. Moins de surcharge : WebSockets prend en charge les sous-protocoles et les extensions, permettant des protocoles standardisés et personnalisés en plus du protocole WebSocket de base. Protocoles et extensions Cas d'utilisation : jeux multijoueurs en temps réel dans lesquels les actions des joueurs doivent être immédiatement reflétées sur les autres joueurs. Jeux en ligne : applications comme Google Docs, où plusieurs utilisateurs peuvent modifier un document simultanément et voir les modifications de chacun en temps réel. Outils collaboratifs : Plateformes de négociation d'actions où les cours des actions doivent être mis à jour en temps réel. Applications financières : toute application où les utilisateurs doivent recevoir des notifications en temps réel, comme les plateformes de réseaux sociaux ou les applications de messagerie. Notifications : sites Web d'actualités ou plateformes de médias sociaux sur lesquels les nouvelles publications ou mises à jour sont diffusées en direct aux utilisateurs. Flux en direct Exemple Demande OBTENEZ « ws://site:8181 » Réponse HTTP/1.1 101 protocoles de commutation Webhook est un rappel HTTP défini par l'utilisateur déclenché par des événements d'application Web spécifiques, permettant des mises à jour de données en temps réel et des intégrations entre différents systèmes. Webhook : XML, JSON, texte brut Format : HTTP/HTTPS Protocole de transport Concepts et caractéristiques clés : les webhooks sont généralement utilisés pour indiquer qu'un événement s'est produit. Au lieu de demander des données à intervalles réguliers, les webhooks fournissent des données au fur et à mesure qu'elles se produisent, bouleversant ainsi le modèle traditionnel de demande-réponse. Piloté par les événements : les webhooks sont essentiellement un mécanisme de rappel défini par l'utilisateur. Lorsqu'un événement spécifique se produit, le site source effectue un rappel HTTP vers l'URI fourni par le site cible, qui entreprendra alors une action spécifique. Mécanisme de rappel : Lorsque le webhook est déclenché, le site source enverra des données (payload) au site cible. Ces données sont généralement au format JSON ou XML. Payload : les webhooks permettent aux applications d'obtenir des données en temps réel, ce qui les rend très réactives. Temps réel : les utilisateurs ou les développeurs peuvent généralement définir les événements spécifiques dont ils souhaitent être informés. Personnalisable : étant donné que les webhooks impliquent d'effectuer des rappels vers des points de terminaison HTTP définis par l'utilisateur, ils peuvent poser des problèmes de sécurité. Il est crucial de garantir que le point final est sécurisé, que les données sont validées et éventuellement cryptées. Sécurité Cas d'utilisation : déclenchement de builds et de déploiements lorsque le code est poussé ou qu'une pull request est fusionnée. Intégration et déploiement continus (CI/CD) : notifier les systèmes en aval lorsque le contenu est mis à jour, publié ou supprimé. Systèmes de gestion de contenu (CMS) : informer les plateformes de commerce électronique des résultats des transactions, tels que les paiements réussis, les transactions échouées ou les remboursements. Passerelles de paiement : recevoir des notifications sur les nouvelles publications, mentions ou autres événements pertinents sur les plateformes de médias sociaux. Intégrations de médias sociaux : les appareils ou les capteurs peuvent déclencher des webhooks pour informer d'autres systèmes ou services d'événements ou de lectures de données spécifiques. IoT (Internet des objets) Exemple Demande OBTENIR « » https://external-site/webhooks?url=http://site/service-h/api&name=name Réponse { "webhook_id": 12 } RPC et gRPC (Remote Procedure Call) est un protocole qui permet à un programme d'exécuter une procédure ou un sous-programme dans un autre espace d'adressage, permettant une communication et un échange de données transparents entre les systèmes distribués. RPC (Google RPC) est un framework open source moderne construit sur RPC qui utilise HTTP/2 pour le transport et les tampons de protocole comme langage de description d'interface, fournissant des fonctionnalités telles que l'authentification, l'équilibrage de charge, etc. pour faciliter une communication efficace et robuste. entre les microservices. gRPC RPC : JSON, XML, Protobuf, Thrift, FlatBuffers Format : Divers Protocole de transport Concepts et caractéristiques clés : RPC permet à un programme de provoquer l'exécution d'une procédure (sous-programme) dans un autre espace d'adressage (généralement sur un autre ordinateur sur un réseau partagé). C'est comme appeler une fonction exécutée sur une machine différente de celle de l'appelant. Définition : Dans le contexte de RPC, les stubs sont des morceaux de code générés par des outils qui permettent aux appels de procédures locales et distantes d'apparaître de la même manière. Le client dispose d'un stub qui ressemble à la procédure distante et le serveur possède un stub qui décompresse les arguments, appelle la procédure réelle, puis regroupe les résultats à renvoyer. Stubs : les appels RPC traditionnels sont bloquants, ce qui signifie que le client envoie une requête au serveur et est bloqué en attendant une réponse du serveur. Synchrone par défaut : de nombreux systèmes RPC permettent à différentes implémentations client et serveur de communiquer quelle que soit la langue dans laquelle elles sont écrites. Langue neutre : RPC nécessite souvent que le client et le serveur connaissent la procédure appelée, ses paramètres et son type de retour. Couplage serré Cas d'utilisation : RPC est couramment utilisé dans les systèmes distribués où des parties d'un système sont réparties sur différentes machines ou réseaux mais doivent communiquer comme si elles étaient locales. Systèmes distribués : NFS (Network File System) est un exemple de RPC effectuant des opérations sur les fichiers à distance. Systèmes de fichiers réseau Exemple Demande { "method": "addUser", "params": [ "Alex" ] } Réponse { "id": 42, "name": "Alex", "error": null } gRPC : Protobuf Format : HTTP/2 Protocole de transport Concepts et caractéristiques clés : gRPC est un framework RPC open source développé par Google. Il utilise HTTP/2 pour le transport, Protocol Buffers (Protobuf) comme langage de description d'interface et fournit des fonctionnalités d'authentification, d'équilibrage de charge, etc. Définition : il s'agit d'un mécanisme extensible, indépendant du langage et de la plate-forme, permettant de sérialiser des données structurées. Avec gRPC, vous définissez les méthodes de service et les types de messages à l'aide de Protobuf. Tampons de protocole : gRPC est conçu pour une communication à faible latence et à haut débit. HTTP/2 permet de multiplexer plusieurs appels sur une seule connexion et réduit les frais généraux. Performances : gRPC prend en charge les requêtes et les réponses en streaming, permettant des cas d'utilisation plus complexes comme des connexions de longue durée, des mises à jour en temps réel, etc. Streaming : gRPC permet aux clients de spécifier combien de temps ils attendront la fin d'un RPC. Le serveur peut vérifier cela et décider s'il doit terminer l'opération ou l'abandonner si cela prend trop de temps. Délais/Délai d'attente : gRPC est conçu pour prendre en charge l'authentification enfichable, l'équilibrage de charge, les tentatives, etc. Enfichable : comme RPC, gRPC est indépendant du langage. Cependant, avec Protobuf et les outils gRPC, générer du code client et serveur dans plusieurs langues est simple. Neutre en termes de langage Cas d'utilisation : gRPC est couramment utilisé dans les architectures de microservices en raison de ses caractéristiques de performances et de sa capacité à définir facilement des contrats de service. Microservices : compte tenu de sa prise en charge du streaming, gRPC convient aux applications en temps réel dans lesquelles les serveurs envoient des données aux clients en temps réel. Applications en temps réel : les avantages en termes de performances et les capacités de streaming de gRPC en font un bon choix pour les clients mobiles communiquant avec les services backend. Clients mobiles Exemple message User { int id = 1 string name = 2 } service UserService { rpc AddUser(User) returns (User); } SAVON , qui signifie Simple Object Access Protocol, est un protocole d'échange d'informations structurées pour implémenter des services Web dans les réseaux informatiques. Il s'agit d'un protocole basé sur XML qui permet aux programmes exécutés sur des systèmes d'exploitation disparates de communiquer entre eux. SOAP : XML Format : HTTP/HTTPS, JMS, SMTP, etc. Protocole de transport Concepts et caractéristiques clés : les messages SOAP sont formatés en XML et contiennent les éléments suivants : Basé sur XML : élément racine d'un message SOAP qui définit le document XML comme un message SOAP. Enveloppe : contient tous les attributs facultatifs du message utilisés dans le traitement du message, soit à un point intermédiaire, soit au point final ultime. En-tête : contient les données XML comprenant le message envoyé. Corps : Un élément Fault facultatif qui fournit des informations sur les erreurs lors du traitement du message. Fault : SOAP peut être utilisé avec n'importe quel modèle de programmation et n'est pas lié à un modèle spécifique. Neutralité : Il peut fonctionner sur n’importe quel système d’exploitation et dans n’importe quelle langue. Indépendance : Chaque requête d'un client vers un serveur doit contenir toutes les informations nécessaires à la compréhension et au traitement de la requête. Stateless : l'élément Fault dans un message SOAP est utilisé pour le rapport d'erreurs. Gestion des erreurs intégrée : fonctionne sur la base de normes bien définies, y compris la spécification SOAP elle-même, ainsi que des normes associées telles que WS-ReliableMessaging pour garantir la livraison des messages, WS-Security pour la sécurité des messages, etc. Standardisé Cas d'utilisation : SOAP est souvent utilisé dans les environnements d'entreprise en raison de sa robustesse, de son extensibilité et de sa capacité à traverser les pare-feu et les proxys. Applications d'entreprise : De nombreux services Web, notamment les plus anciens, utilisent SOAP. Cela inclut les services proposés par de grandes entreprises comme Microsoft et IBM. Services Web : la sécurité et l'extensibilité intégrées de SOAP en font un bon choix pour les transactions financières, où l'intégrité et la sécurité des données sont primordiales. Transactions financières : les entreprises de télécommunications peuvent utiliser SOAP pour des processus tels que la facturation, où différents systèmes doivent communiquer de manière fiable. Télécommunications Exemple Demande <?xml version="1.0"?> <soap:Envelope> <soap:Body> <m:AddUserRequest> <m:Name>Alex</m:Name> </m:AddUserRequest> </soap:Body> </soap:Envelope> Réponse <?xml version="1.0"?> <soap:Envelope> <soap:Body> <m:AddUserResponse> <m:Id>42</m:Id> <m:Name>Alex</m:Name> </m:AddUserResponse> </soap:Body> </soap:Envelope> Conclusion Le paysage des styles d'architecture d'API est diversifié, offrant diverses approches telles que REST, SOAP, RPC, etc., chacune avec des atouts et des cas d'utilisation uniques, permettant aux développeurs de choisir le paradigme le plus approprié pour créer des intégrations évolutives, efficaces et robustes entre différents logiciels. composants et systèmes.