
15,935 lectures
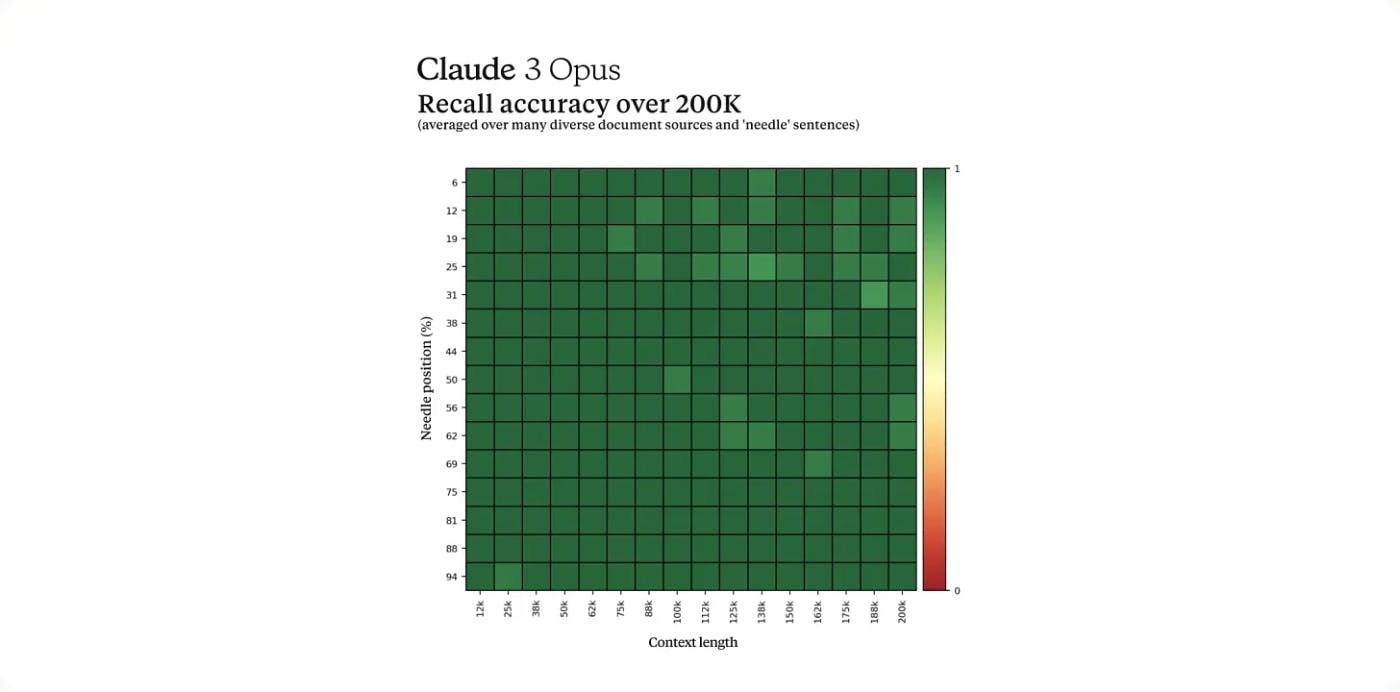
L’AGI se rapproche-t-elle ? Le modèle Claude 3 Opus d'Anthropic montre des lueurs de raisonnement métacognitif
by byaimodels44@aimodels44
byaimodels44@aimodels44
Among other things, launching AIModels.fyi ... Find the right AI model for your project - https://aimodels.fyi
2024/03/05


















Among other things, launching AIModels.fyi ... Find the right AI model for your project - https://aimodels.fyi
Story's Credibility


Among other things, launching AIModels.fyi ... Find the right AI model for your project - https://aimodels.fyi
Story's Credibility
About Author

Among other things, launching AIModels.fyi ... Find the right AI model for your project - https://aimodels.fyi
COMMENTAIRES












