
104 lectures
Découvrir les projections de l'énergie solaire : analyse du modèle bayésien au fil des saisons
by byQuantification Theory Research Publication@quantification
byQuantification Theory Research Publication@quantification
The publication about the quantity of something. The theory about why that quantity is what is. And research!
2024/02/02


















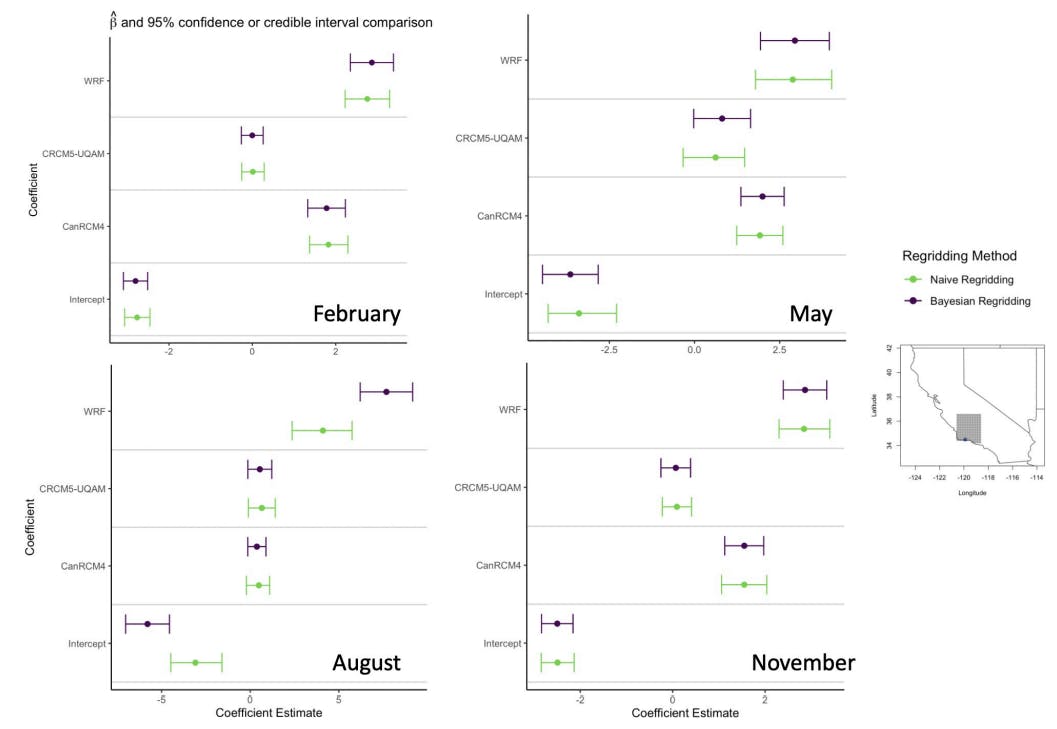
The publication about the quantity of something. The theory about why that quantity is what is. And research!


The publication about the quantity of something. The theory about why that quantity is what is. And research!
About Author

The publication about the quantity of something. The theory about why that quantity is what is. And research!
COMMENTAIRES












