
112 Lesungen
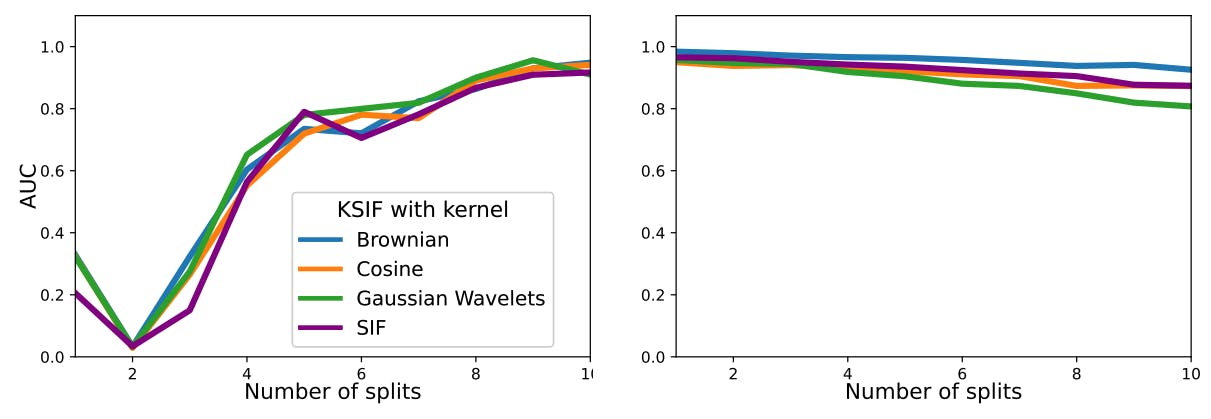
Dekodierung der Split-Window-Empfindlichkeit in Signaturisolationswäldern
by byComputational Technology for All@computational
byComputational Technology for All@computational
Computational: We take random inputs, follow complex steps, and hope the output makes sense. And then blog about it.
2024/11/20


















Computational: We take random inputs, follow complex steps, and hope the output makes sense. And then blog about it.
Story's Credibility


Computational: We take random inputs, follow complex steps, and hope the output makes sense. And then blog about it.
Story's Credibility
About Author

Computational: We take random inputs, follow complex steps, and hope the output makes sense. And then blog about it.
KOMMENTARE










