109,982 aflæsninger
Open-Source: The Next Step in AI Revolution
by byMinIO@minio
byMinIO@minio
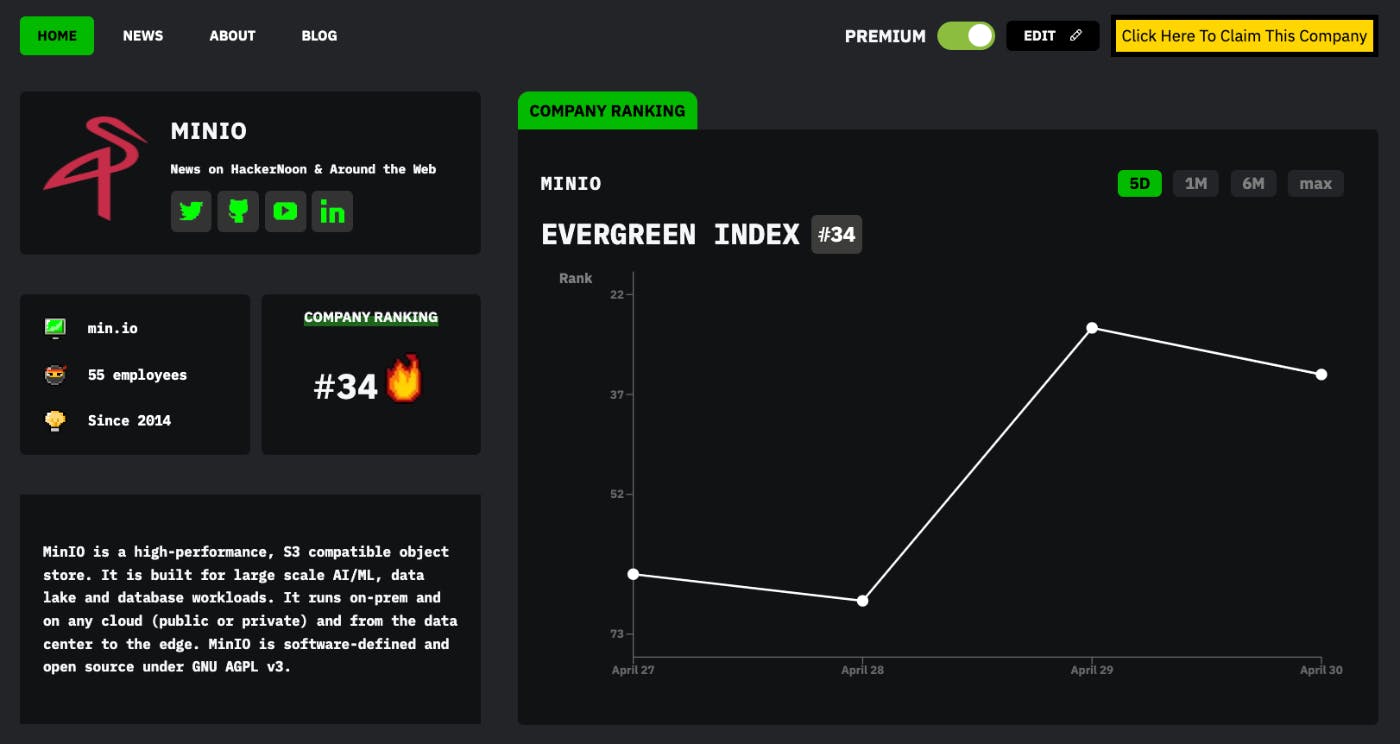
MinIO is a high-performance, cloud-native object store that runs anywhere (public cloud, private cloud, colo, onprem).
2024/01/25








































































MinIO is a high-performance, cloud-native object store that runs anywhere (public cloud, private cloud, colo, onprem).
Story's Credibility



MinIO is a high-performance, cloud-native object store that runs anywhere (public cloud, private cloud, colo, onprem).
Story's Credibility
About Author

MinIO is a high-performance, cloud-native object store that runs anywhere (public cloud, private cloud, colo, onprem).
KOMMENTARER