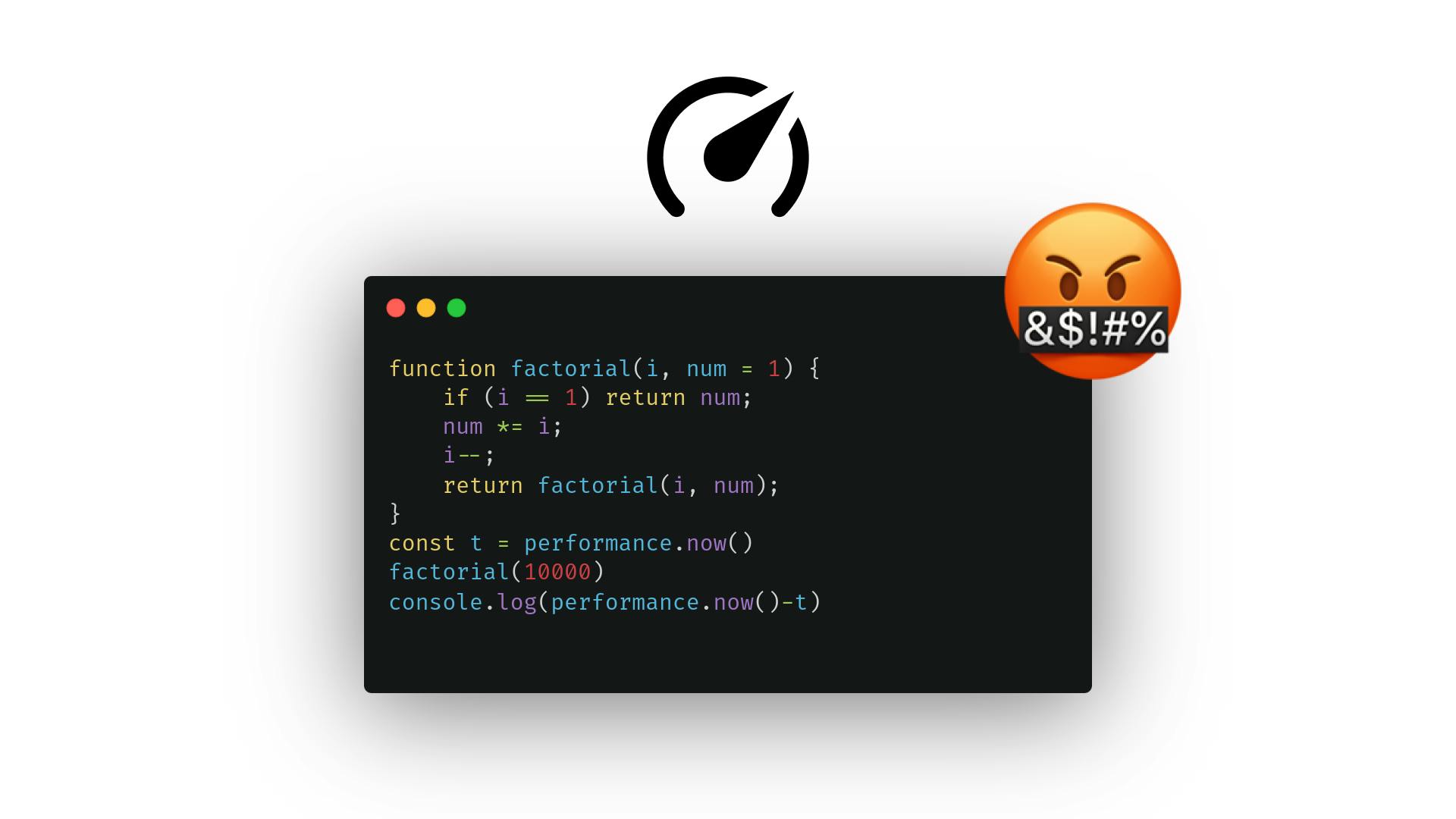
Nesnáším srovnávací kód, stejně jako každý člověk (což v tuto chvíli většina diváků tohoto pravděpodobně není ¯\ /¯). Je mnohem zábavnější předstírat, že vaše ukládání hodnoty do mezipaměti zvýšilo výkon o 1000 %, než testovat, co to udělalo. Bohužel, benchmarking v JavaScriptu je stále nezbytný, zvláště když se JavaScript používá ( ) v aplikacích citlivějších na výkon. Bohužel, kvůli mnoha svým klíčovým architektonickým rozhodnutím, JavaScript neusnadňuje benchmarking. (ツ) když by neměl? Co je špatného na JavaScriptu? Kompilátor JIT snižuje přesnost (?) Pro ty, kteří neznají kouzlo moderních skriptovacích jazyků, jako je JavaScript, může být jejich architektura docela složitá. Namísto pouhého spouštění kódu přes interpret, který okamžitě chrlí instrukce, využívá většina JavaScriptových enginů architekturu podobnější kompilovanému jazyku, jako je C – integrují . více vrstev „kompilátorů“ Každý z těchto kompilátorů nabízí jiný kompromis mezi dobou kompilace a výkonem za běhu, takže uživatel nemusí strávit výpočetní optimalizaci kódu, který se spouští jen zřídka, a zároveň využít výhod pokročilejšího kompilátoru v oblasti výkonu pro kód, který je spouštěn nejčastěji ( „horké stezky“). Existují také některé další komplikace, které vznikají při používání optimalizačních kompilátorů, které zahrnují ozdobná programovací slova jako „ “, ale ušetřím vás a vyhnu se zde o tom mluvit. monomorfismus funkcí Takže… proč je to důležité pro benchmarking? Jak jste možná uhodli, protože benchmarking měří kódu, kompilátor JIT může mít docela velký vliv. Menší části kódu, když jsou testovány, mohou po úplné optimalizaci často zaznamenat 10x+ zlepšení výkonu, což do výsledků vnáší spoustu chyb. výkon Například ve vašem nejzákladnějším nastavení srovnávání (z několika důvodů nepoužívejte nic jako níže): for (int i = 0; i<1000; i++) { console.time() // do some expensive work console.timeEnd() } ) (Nebojte se, budeme mluvit také o console.time Velká část vašeho kódu bude po několika pokusech uložena do mezipaměti, což výrazně zkrátí čas na operaci. Benchmarkové programy často dělají maximum pro to, aby toto ukládání do mezipaměti/optimalizace eliminovaly, protože také mohou programy testované později v procesu benchmarku vypadat relativně rychleji. Nakonec se však musíte zeptat, zda benchmarky bez optimalizací odpovídají výkonu v reálném světě. Jistě, v určitých případech, jako jsou málo navštěvované webové stránky, je optimalizace nepravděpodobná, ale v prostředích, jako jsou servery, kde je nejdůležitější výkon, by se optimalizace měla očekávat. Pokud spouštíte kus kódu jako middleware pro tisíce požadavků za sekundu, raději doufejte, že ho V8 optimalizuje. V zásadě tedy i v rámci jednoho enginu existují 2–4 různé způsoby, jak spustit kód s různou úrovní výkonu. Oh, také je v určitých případech neuvěřitelně obtížné zajistit, aby byly povoleny určité úrovně optimalizace. Bavte se :). Motory dělají, co mohou, aby vám zabránily v přesném načasování Znáte otisky prstů? Technika, která umožnila ? Ano, JavaScriptové enginy dělaly maximum, aby to zmírnily. Tato snaha spolu s krokem k zabránění vedla k tomu, že JavaScriptové motory záměrně znepřesnily načasování, takže hackeři nemohou získat přesná měření aktuálního výkonu počítačů nebo toho, jak drahá je určitá operace. použití Do Not Track pro podporu sledování útokům na časování Bohužel to znamená, že bez ladění mají benchmarky stejný problém. Příklad v předchozí části bude nepřesný, protože se měří pouze v milisekundách. Nyní to přepněte na . Velký. performance.now() Nyní máme časová razítka v mikrosekundách! // Bad console.time(); // work console.timeEnd(); // Better? const t = performance.now(); // work console.log(performance.now() - t); Kromě... všechny jsou v krocích po 100 μs. Nyní , abychom zmírnili riziko útoků načasování. Jejda, stále můžeme zvyšovat pouze 5μs. 5μs je pravděpodobně dostatečná přesnost pro mnoho případů použití, ale budete muset hledat jinde, co vyžaduje větší granularitu. Pokud vím, žádný prohlížeč neumožňuje podrobnější časovače. Node.js ano, ale to má samozřejmě své vlastní problémy. přidáme několik hlaviček I když se rozhodnete spustit svůj kód přes prohlížeč a nechat kompilátor, aby udělal svou věc, je jasné, že budete mít stále více bolesti hlavy, pokud chcete přesné načasování. Jo, a ne všechny prohlížeče jsou si rovny. Každé prostředí je jiné Miluji za to, co udělal, aby posunul JavaScript na straně serveru vpřed, ale sakra, dělá to srovnávání JavaScriptu pro servery mnohem těžší. Před několika lety byla jedinými prostředími JavaScriptu na straně serveru, o která se lidé zajímali, byly Node.js a , které obě používaly V8 JavaScript engine (stejný v Chrome). Bun místo toho používá JavaScriptCore, engine v Safari, který má úplně jiné výkonnostní charakteristiky. Bun Deno Tento problém více prostředí JavaScriptu s vlastními výkonnostními charakteristikami je v JavaScriptu na straně serveru relativně nový, ale klienty sužuje již dlouhou dobu. 3 různé běžně používané JavaScriptové enginy, V8, JSC a SpiderMonkey pro Chrome, Safari a Firefox, všechny mohou pracovat výrazně rychleji nebo pomaleji na ekvivalentním kusu kódu. Jedním z příkladů těchto rozdílů je optimalizace Tail Call Optimization (TCO). TCO optimalizuje funkce, které se opakují na konci jejich těla, jako je tento: function factorial(i, num = 1) { if (i == 1) return num; num *= i; i--; return factorial(i, num); } Zkuste porovnat v Bun. Nyní zkuste to samé v Node.js nebo Deno. Měli byste dostat chybu podobnou této: factorial(100000) function factorial(i, num = 1) { ^ RangeError: Maximum call stack size exceeded Ve V8 (a rozšířením Node.js a Deno) pokaždé, když se na konci zavolá, engine vytvoří zcela nový kontext funkce pro spuštění vnořené funkce, která je nakonec omezena zásobníkem volání. Ale proč se to neděje v Bunu? JavaScriptCore, který Bun používá, implementuje TCO, které optimalizuje tyto typy funkcí tím, že je přemění na smyčku for podobně jako: factorial() function factorial(i, num = 1) { while (i != 1) { num *= i; i--; } return i; } Nejenže se výše uvedený návrh vyhýbá limitům zásobníku volání, ale je také mnohem rychlejší, protože nevyžaduje žádné nové kontexty funkcí, což znamená, že funkce jako výše budou testovány velmi odlišně pod různými motory. Tyto rozdíly v podstatě znamenají, že byste měli porovnávat všechny motory, u kterých očekáváte spouštění kódu, abyste zajistili, že kód, který je rychlý v jednom, nebude pomalý v jiném. Pokud také vyvíjíte knihovnu, u které očekáváte použití na mnoha platformách, nezapomeňte zahrnout esoteričtější nástroje jako ; mají výrazně odlišné výkonové charakteristiky. Hermes Čestná uznání Popelář a jeho tendence vše náhodně pozastavovat. Schopnost kompilátoru JIT odstranit veškerý váš kód, protože to „není nutné“. Strašně široké grafy plamenů ve většině vývojářských nástrojů JavaScriptu. Myslím, že chápete pointu. Takže… Jaké je řešení? Přál bych si, abych mohl ukázat na balíček npm, který řeší všechny tyto problémy, ale ve skutečnosti žádný neexistuje. Na serveru to máte o něco jednodušší. Pomocí můžete ručně ovládat úrovně optimalizace, ovládat sběrač odpadu a získat přesné načasování. Samozřejmě k tomu budete potřebovat nějaké Bash-fu, abyste vytvořili dobře navržený benchmark pipeline, protože bohužel d8 není dobře integrován (nebo vůbec integrován) s Node.js. d8 Můžete také povolit určité příznaky v Node.js, abyste získali podobné výsledky, ale přijdete o funkce, jako je povolení konkrétních úrovní optimalizace. v8 --sparkplug --always-sparkplug --no-opt [file] Příklad D8 s povolenou specifickou kompilační vrstvou (zapalovací svíčka). D8 ve výchozím nastavení obsahuje větší kontrolu nad GC a více informací o ladění obecně. Můžete získat nějaké podobné funkce na JavaScriptCore??? Upřímně řečeno, CLI JavaScriptCore jsem moc nepoužíval a je nedostatečně zdokumentováno. Můžete povolit konkrétní úrovně pomocí , ale nejsem si jistý, kolik informací o ladění můžete načíst. Bun také obsahuje některé užitečné , ale jsou omezeny podobně jako Node.js. silně jejich příznaků příkazového řádku nástroje pro srovnávání Bohužel to vše vyžaduje základní motor/testovací verzi motoru, kterou může být docela těžké sehnat. Zjistil jsem, že nejjednodušší způsob, jak spravovat motory, je spárovaný s , protože společně výrazně usnadňují správu motorů a spouštění kódu na nich. Samozřejmě je stále potřeba spousta ruční práce, protože tyto nástroje pouze spravují běh kódu napříč různými motory – srovnávací kód si stále musíte napsat sami. esvu eshost-cli Pokud se jen snažíte co nejpřesněji srovnávat motor s výchozími možnostmi na serveru, existují běžně dostupné nástroje Node.js, jako je , které pomáhají zlepšit přesnost časování a chyby související s GC. Mnoho z těchto nástrojů, jako je Mitata, lze také použít v mnoha motorech; Samozřejmě, stále budete muset nastavit potrubí jako výše. mitata V prohlížeči je vše mnohem obtížnější. Neznám žádné řešení přesnějšího časování a ovládání motoru je daleko omezenější. Nejvíce informací, které můžete získat v souvislosti s výkonem JavaScriptu za běhu v prohlížeči, pocházejí z , které nabízejí základní nástroje pro simulaci grafu plamene a zpomalení CPU. devtools Chrome Závěr Mnoho ze stejných rozhodnutí o návrhu, která učinila JavaScript (relativně) výkonným a přenosným, činí srovnávání výrazně obtížnějším, než je tomu v jiných jazycích. Existuje mnohem více cílů k porovnání a vy máte mnohem menší kontrolu nad každým cílem. Doufejme, že řešení jednoho dne mnohé z těchto problémů zjednoduší. Možná bych nakonec vytvořil nástroj pro zjednodušení benchmarkingu mezi jednotlivými stroji a kompilací, ale prozatím vytvoření kanálu k vyřešení všech těchto problémů zabere docela dost práce. Samozřejmě je důležité si uvědomit, že tyto problémy se netýkají každého – pokud váš kód běží pouze v jednom prostředí, neztrácejte čas srovnáváním jiných prostředí. Ať už se rozhodnete srovnávat jakkoli, doufám, že vám tento článek ukázal některé problémy, které se vyskytují při srovnávání JavaScriptu. Dejte mi vědět, jestli by vám pomohl návod na implementaci některých věcí, které popisuji výše.