
385 পড়া
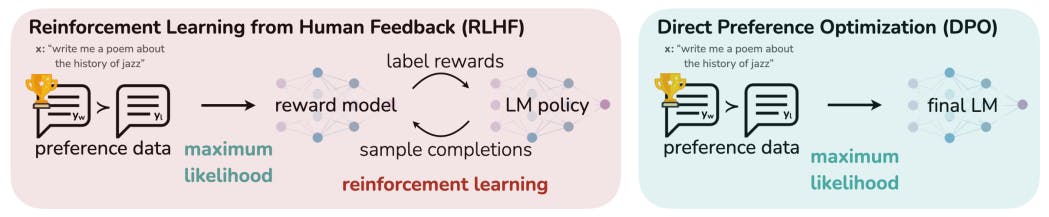
সরাসরি পছন্দ অপ্টিমাইজেশান: আপনার ভাষা মডেল গোপনে একটি পুরস্কার মডেল
by byWritings, Papers and Blogs on Text Models@textmodels
byWritings, Papers and Blogs on Text Models@textmodels
We publish the best academic papers on rule-based techniques, LLMs, & the generation of text that resembles human text.
2024/08/25


















We publish the best academic papers on rule-based techniques, LLMs, & the generation of text that resembles human text.
Story's Credibility


We publish the best academic papers on rule-based techniques, LLMs, & the generation of text that resembles human text.
Story's Credibility
About Author

We publish the best academic papers on rule-based techniques, LLMs, & the generation of text that resembles human text.
মন্তব্য












