






















About Author

A data science writer with five years of experience.
KOMMENTAAR

HANG TAGS



Related Stories
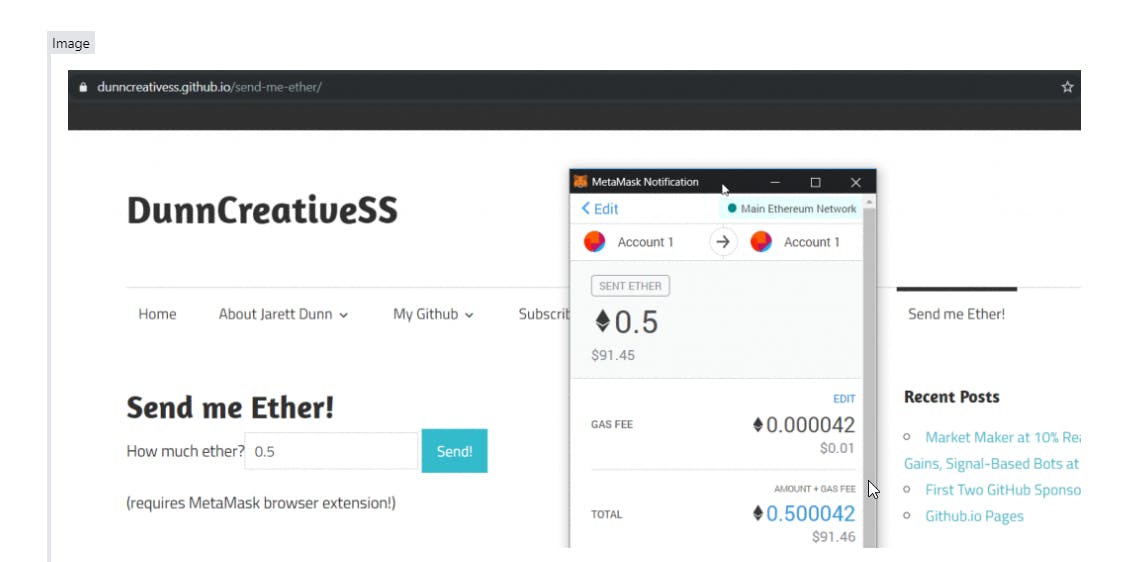




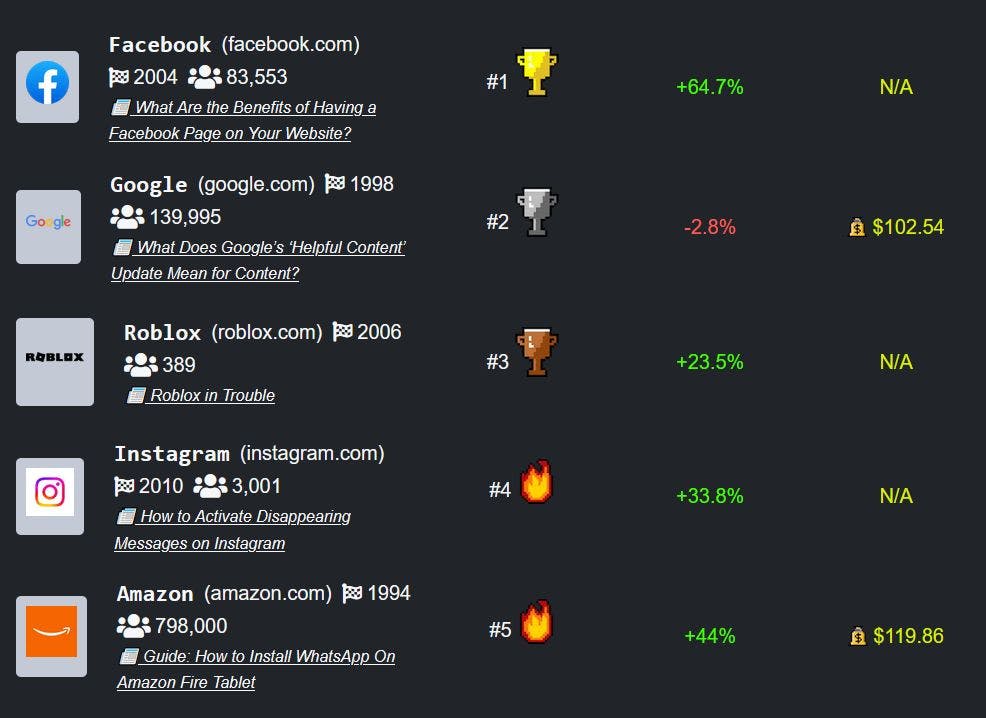



Thrilled to be Recognized as Startup of the Year in New York City
@blairsilverberg
Jan 20, 1970
A data science writer with five years of experience.
@blairsilverberg
Jan 20, 1970
@blairsilverberg
Jan 20, 1970