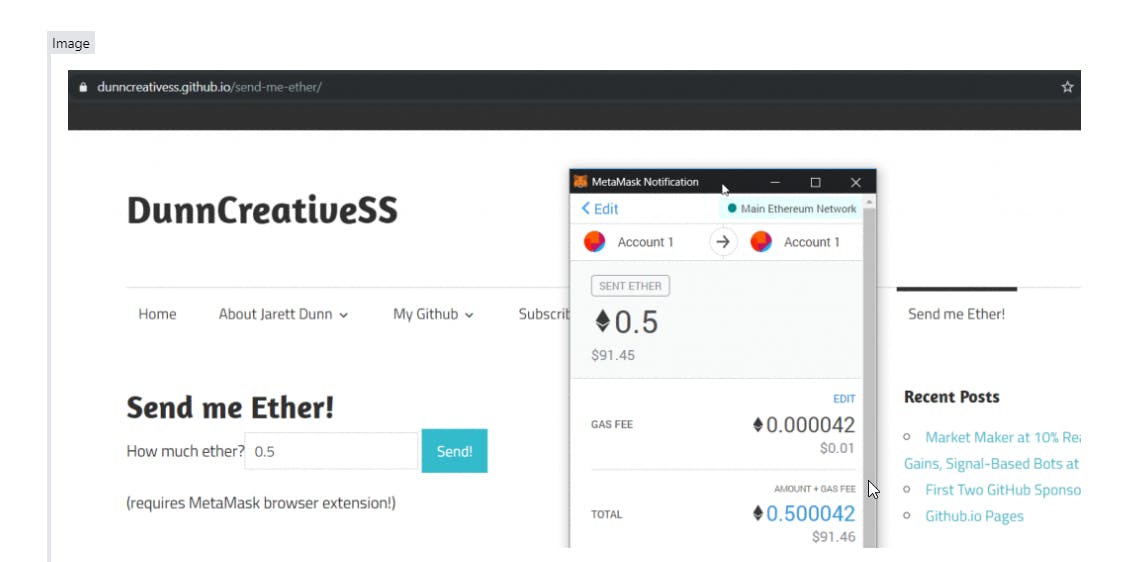
"What If ... I didn't Do It?"


Jan 19, 1970

DataStax, an IBM company, provides integrated AI dev platforms that let you harness data in your app without building a complex tool stack.
DataStax, an IBM company, provides integrated AI dev platforms that let you harness data in your app without building a complex tool stack.

DataStax, an IBM company, provides integrated AI dev platforms that let you harness data in your app without building a complex tool stack.
DataStax, an IBM company, provides integrated AI dev platforms that let you harness data in your app without building a complex tool stack.