
1,136 reads
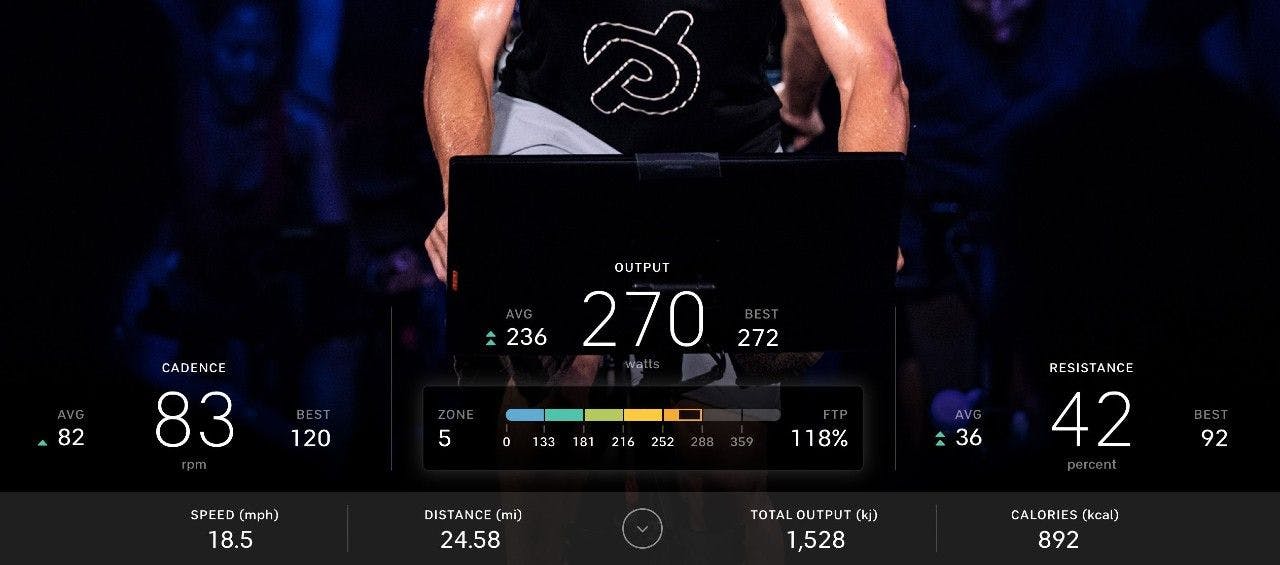
I Used Python To Analyze My Peloton Workout Stats With Real-Time Updates
by
January 17th, 2021








About Author

Solutions Architect @ Coda
Comments

TOPICS
THIS ARTICLE WAS FEATURED IN





Related Stories












10 Threats to an Open API Ecosystem
Jul 18, 2022