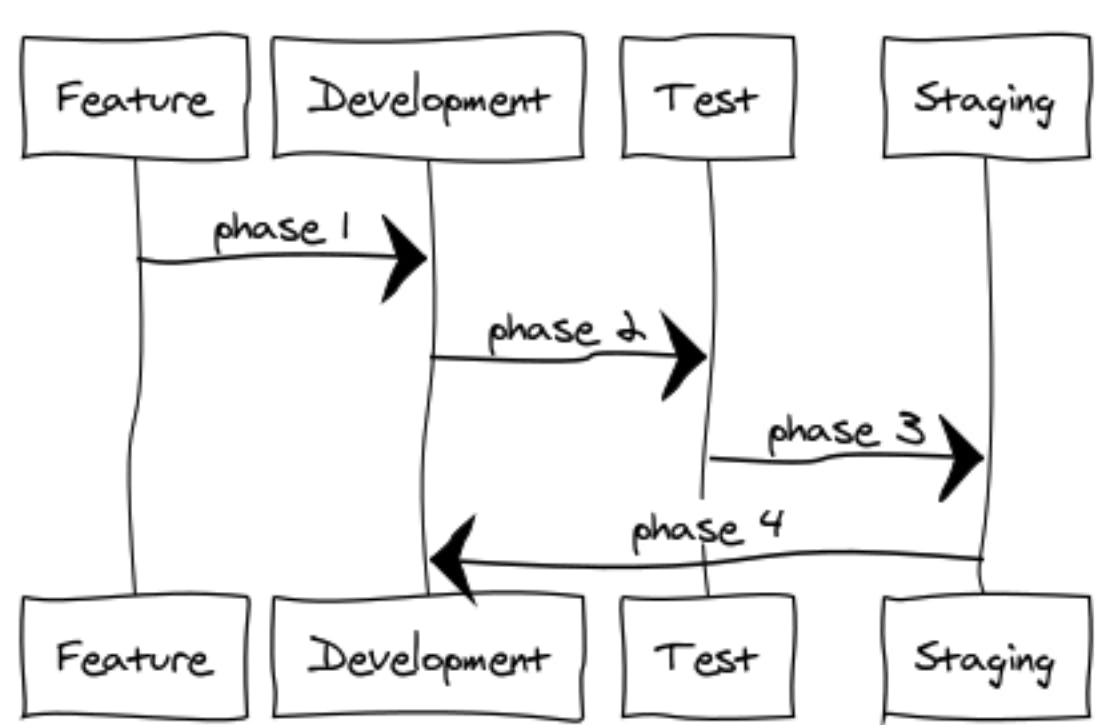
In this post, I will give you the recipe we at use to keep dependencies fresh across 45+ microservices. Globality Our Services We have 45+ internal micro-services, 99% of them are written in . We have an internal framework called which allows for fast convention-over-configuration wiring of components and services. Python microcosm, You can check out all of the microcosm-related projects in this Github link The problem If you worked on a medium+ project, whether a monolithic one OR a micro-service you know, that over time, dependencies go stale. You stop upgrading versions of your dependencies because the process is too complicated and too error-prone. The solution In this diagram above, you can see all of the phases **each project** goes through during the branching cycle. The process is 100% automated and driven by CI and internal scripts. So, let’s go through each of the processes phase 1 branch is being built on the CI after every merge of the feature branch. develop In this phase, we unlock all of the dependencies. Essentially putting in the file. This forces the build to use all fresh dependencies, upgrading all the minor/major versions of services. . requirements.txt In our we use . This means we always have only a **minimum** version. setup.py >= What we find? In that phase, we normally find a dependency that is completely broken, can’t install, crashes, etc… We also usually find that one of our services is broken, which is then being investigated. Normally, if we need to make a code change, it’s during this phase and it’s usually minimal since it’s done incrementally. Phase 2 branch is the base, we check out a branch. develop release/2017.xx.yy During this time, we unlock all of the dependencies (same as phase one). Once it’s unlocked and all dependencies are installed, we the dependencies into a file, and we **commit it** back to the repository. freeze requirements.txt Here’s an example from one of our projects. (I removed internal library names for sanity). Since we use containers (with custom in house layering solution), we ensure that what we test on is the same version that will go forward to staging (and eventually production). docker Once dependencies are locked, they are not reopened on that branch Phase 3 During phase 3, we tag the branch to it’s own tag. That tag is automatically being deployed to staging using the CI. release/2017.xx.yy During this process we only verify that pip is intact, we don’t install dependencies. If all the requirements are not met (meaning we need to install something), the build will fail and alert the engineers. Phase 4 During phase 4, we merge the tag back into develop and the process continues. Keep it fresh keeping your dependencies fresh makes sure you are on top of security fixes and security holes that all of your dependencies use. It makes sure that all of your projects are using the latest of your internal libraries. Automating this process like we did takes the stress out of it. As an engineer you don’t need to think about it, everything is automated on the CI. From the QA perspective, you know that if something works on one environment, it will work on the other. If something is broken it’s not in the underlying infrastructure, it’s in application code. You don’t need to worry that got upgraded under your feet. cryptography Rock on!