
356 reads
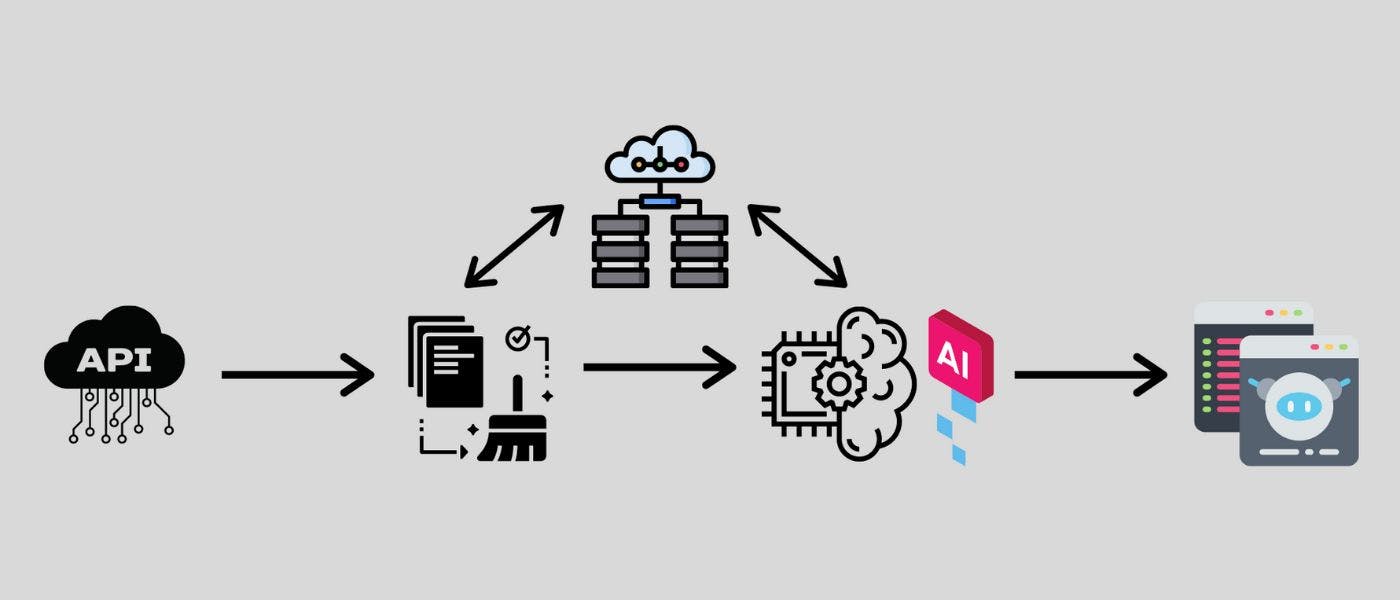
How To Use The Requests Python Library To Make An API Call And Save It As A Pandas Dataframe
by byNathan at StrataScratch@nathanrosidi
byNathan at StrataScratch@nathanrosidi
I like creating content and building tools for data scientists. www.stratascratch.com
April 25th, 2021





I like creating content and building tools for data scientists. www.stratascratch.com


I like creating content and building tools for data scientists. www.stratascratch.com
About Author

I like creating content and building tools for data scientists. www.stratascratch.com
Comments

















