





1,044 reads
How to Use Model Playground for No-Code Model Building





Too Long; Didn't Read
We are now launching Model Playground, a model experimentation and building environment where you can train and benchmark models on your data without writing any code yourself. But, you are still completely in control. Just like if you train a model locally.People Mentioned

Companies Mentioned


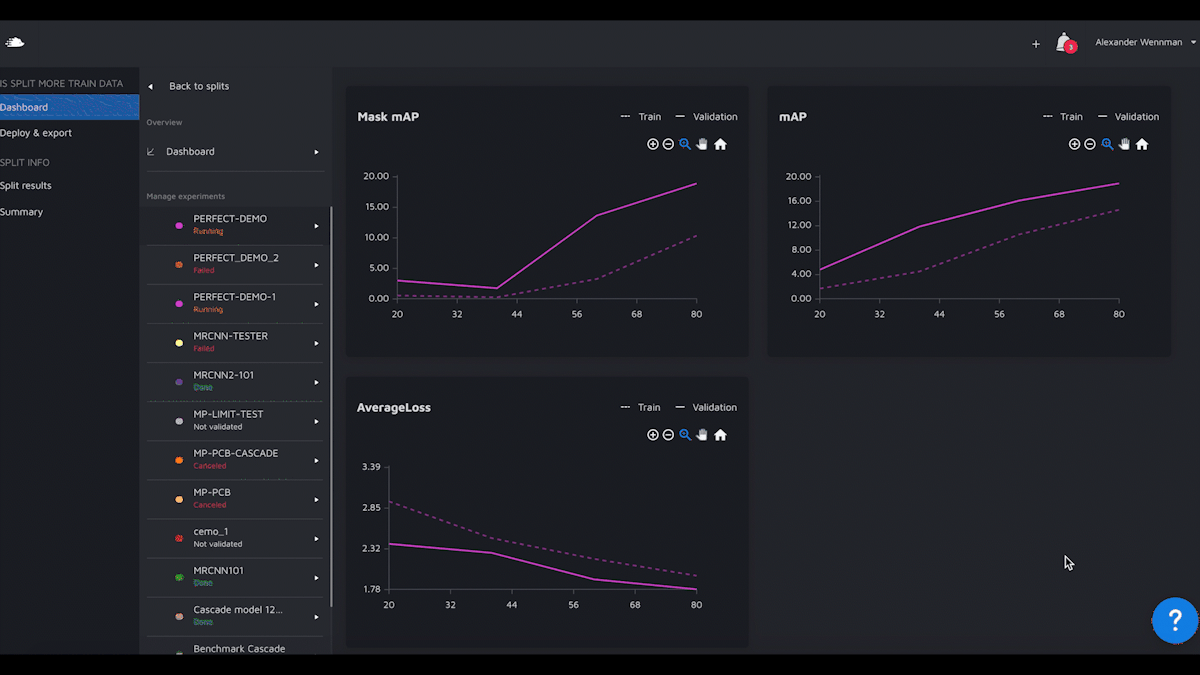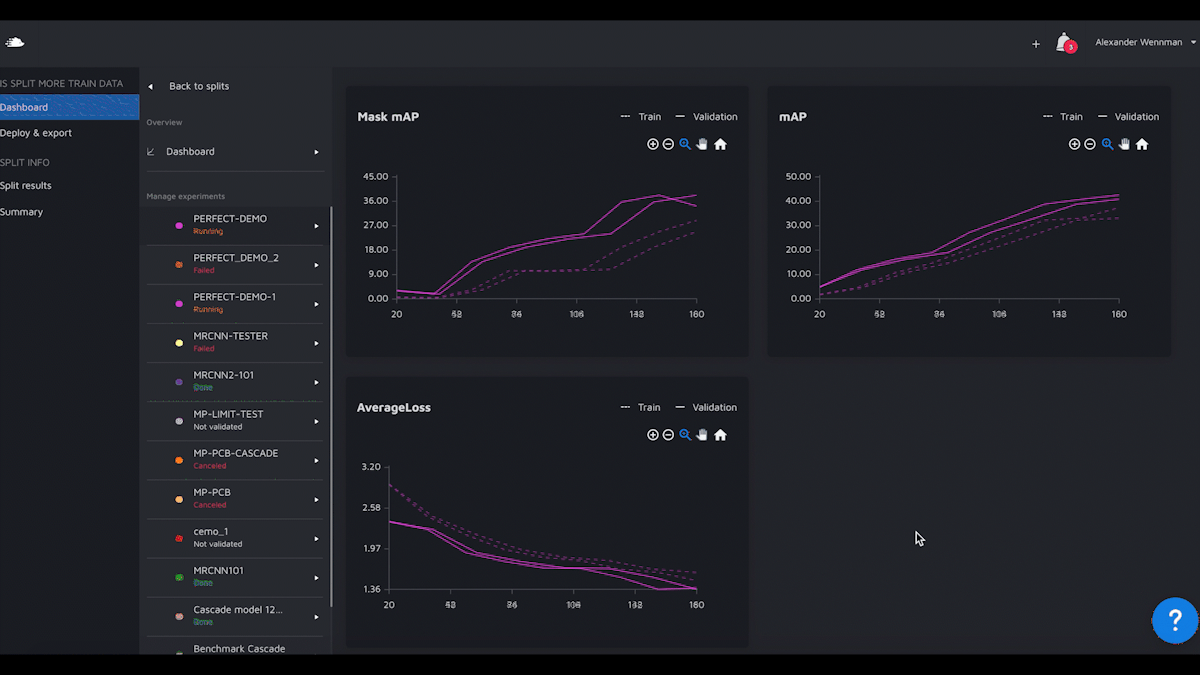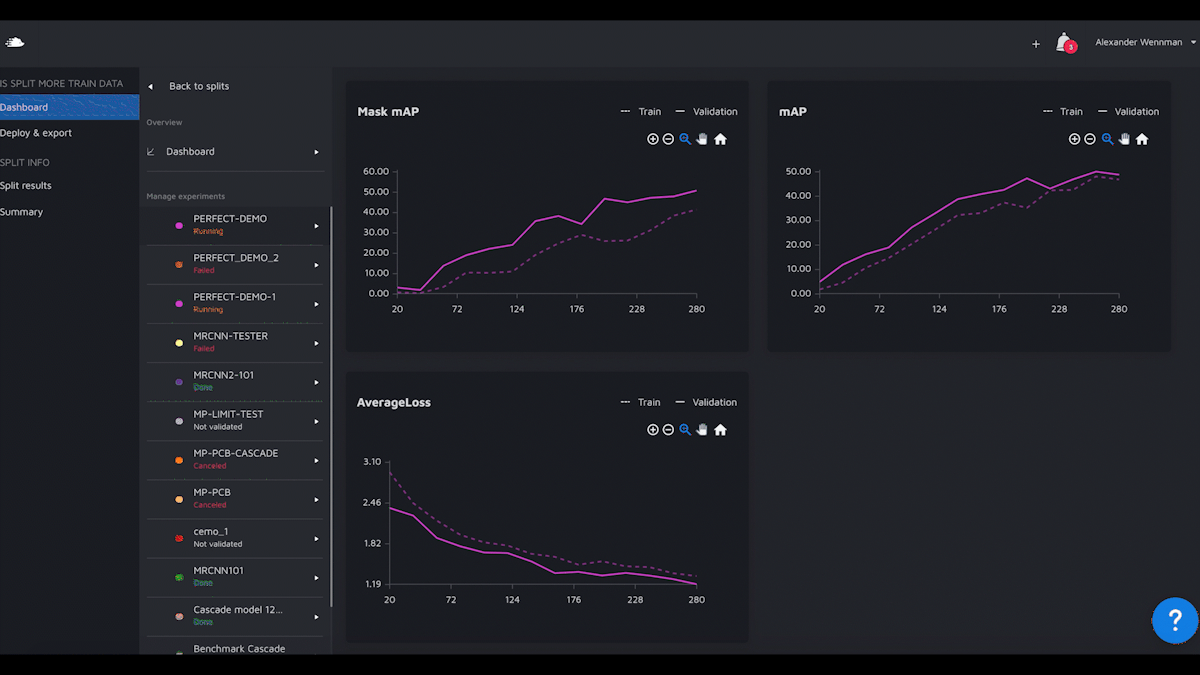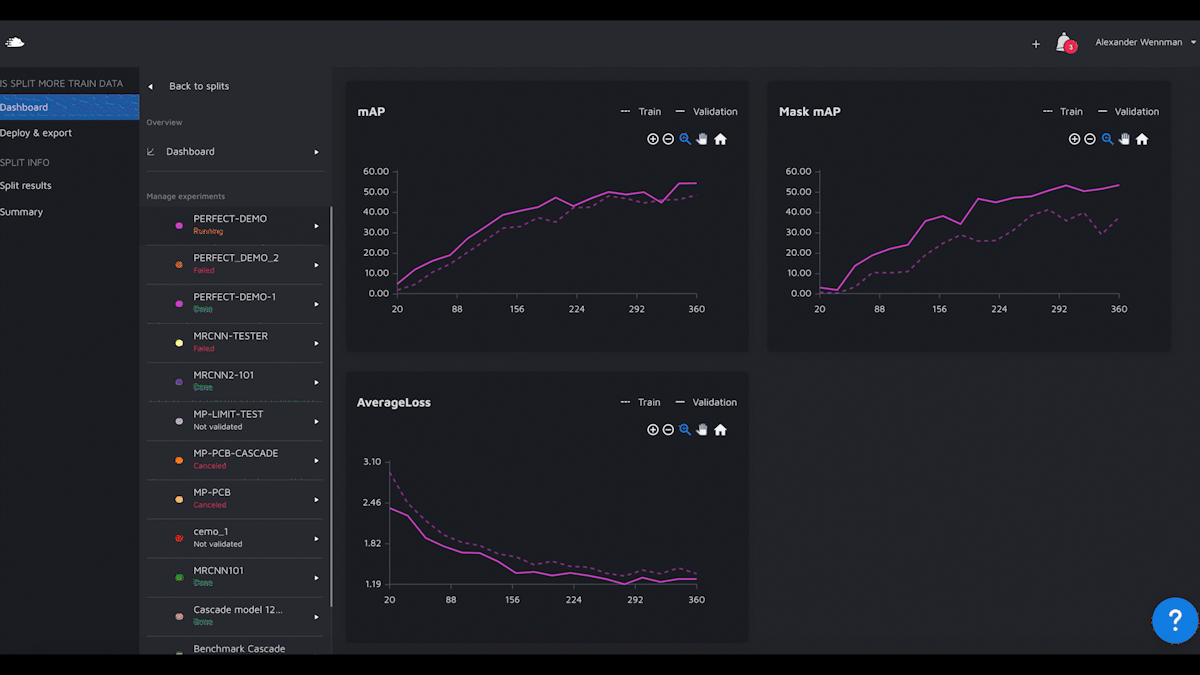


Hasty.ai
@hastyai
A single application for all your vision AI needs.

L O A D I N G
. . . comments & more!
. . . comments & more!
About Author

TOPICS
THIS ARTICLE WAS FEATURED IN...



RELATED STORIES



An Introduction to Automation in Vision AI #automation
Nov 25, 2019



XOCIETY Brings AAA Gaming To Web3 With Sui #gaming
Apr 24, 2024

