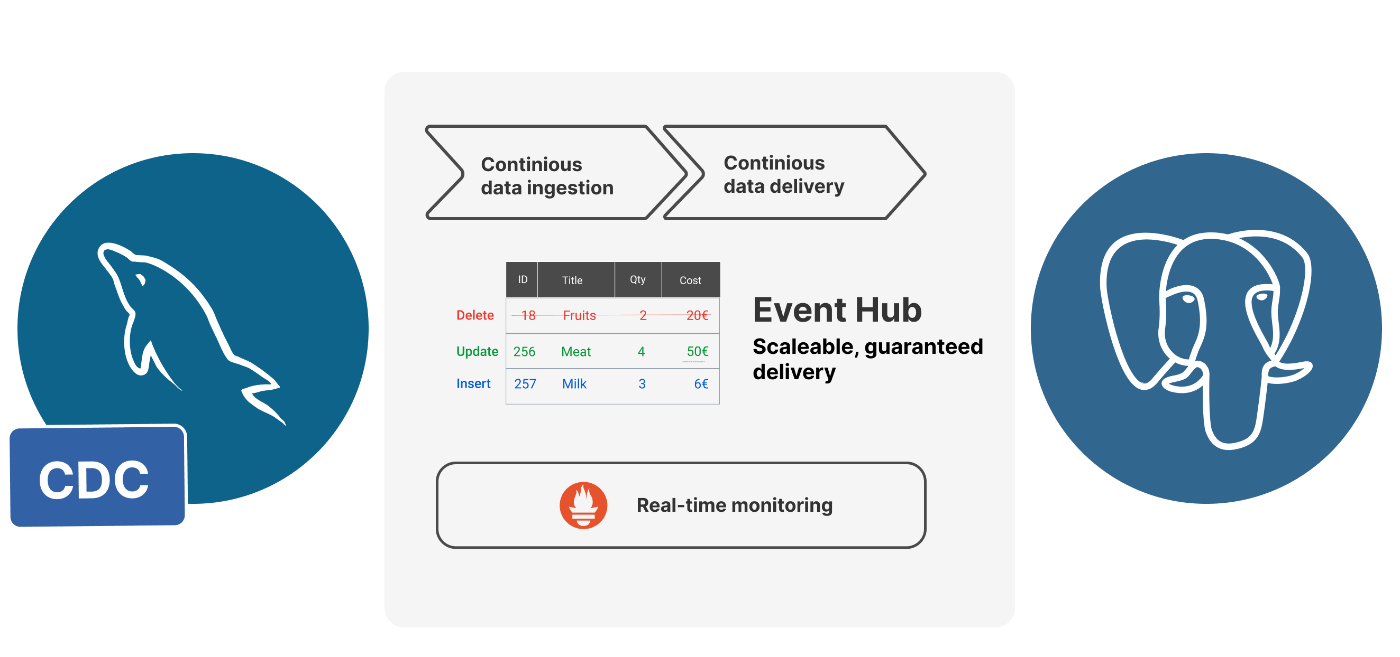
Streaming data from a MySQL database to a PostgreSQL database can be a useful way to move data between systems or to create a real-time replica of a database for reporting and analysis. One way to accomplish this is through the use of tools. Change Data Capture (CDC) CDC is a method of tracking changes made to a database and capturing them in a separate stream. This stream can then be used to replicate the changes to another database. DBConvert Streams helps to replicate your MySQL data to PostgreSQL in real-time. It captures data changes from a source MySQL database and applies them to a target PostgreSQL database. This can be done by setting up a source to read the binary log of a MySQL database and transform the changes to a format that can be consumed by target PostgreSQL database. [Database Streaming Examples and configurations GitHub repository](https://github.com/slotix/dbconvert-streams-public) To begin, let's clone the GitHub repository containing the MySQL to PostgreSQL streaming example. git clone git@github.com:slotix/dbconvert-streams-public.git && cd dbconvert-streams-public/examples/mysql2postgres/sales-db/ Docker Compose configuration. Since DBConvert Streams relies on multiple services, the most efficient way to start the containers is by using . Docker Compose The file from the repository is provided below. docker-compose.yml version: '3.9' services: dbs-api: container_name: api image: slotix/dbs-api entrypoint: - ./dbs-api - --nats=nats:4222 - --source=source-reader:8021 - --target=target-writer:8022 ports: - 8020:8020 depends_on: - nats volumes: - ./mysql2pg.json:/mysql2pg.json:ro dbs-source-reader: container_name: source-reader image: slotix/dbs-source-reader entrypoint: - ./dbs-source-reader - --nats=nats:4222 ports: - 8021:8021 depends_on: - dbs-api dbs-target-writer: container_name: target-writer image: slotix/dbs-target-writer entrypoint: - ./dbs-target-writer - --nats=nats:4222 - --prometheus=http://prometheus:9090 ports: - 8022:8022 depends_on: - dbs-source-reader nats: container_name: nats image: nats entrypoint: /nats-server command: "--jetstream -m 8222 --store_dir /data/nats-server" ports: - 4222:4222 - 8222:8222 prometheus: image: slotix/dbs-prometheus:latest container_name: prom user: root ports: - 9090:9090 mysql-source: container_name: mysql-source build: ./source environment: - MYSQL_ROOT_PASSWORD=123456 ports: - '3306:3306' postgres-target: container_name: postgres-target image: postgres:15-alpine environment: - POSTGRES_USER=postgres - POSTGRES_PASSWORD=postgres command: postgres ports: - '5432:5432' Docker-compose file for DBConvert Streams This docker-compose file is going to bring up multiple services and link them together so they can communicate with each other. With this setup, the replication process takes place between and databases, and it is controlled by , , and services. mysql-source postgres-target dbs-api dbs-source-reader dbs-target-writer nats DBConvert Streams services. service is the entry point of DBConvert Streams. It is where requests are sent with configuration settings for the source and target databases. It specifies the connection details to other components of the system such as , and . dbs-api source-reader target-writer service is responsible for monitoring and capturing changes in the source database, then sending batches of records to the Event Hub. dbs-source-reader service is used to receive changes from the Event Hub and apply them to the target database.. dbs-target-writer service is the core of the Event Hub, it provides communication between other DBS services. nats service is used for monitoring the metrics of DBS services. prometheus Database services. The structure of the tables that will be used in our example is depicted in the diagram below. The structure of MySQL source tables is adapted from the GitHub repository. jdaarevalo/docker_postgres_with_data Source and Target Databases. database image is based on , which includes all the necessary . This image also contains the which creates tables with the structures shown above. mysql-source slotix/dbs-mysql:8 settings to enable MySQL CDC replication initdb.sql script, database, on the other hand, is based on the official lightweight image. database will receive all changes made to the database. postgres-target postgres:15-alpine postgres-target mysql-source Both of these databases, and , are typically located on separate physical servers in a production environment. However, in this example, we will run them on the same machine within distinct containers for demonstration purposes. mysql-source postgres-target Execution. To start all services described above, execute the following command: docker-compose up --build -d This command will use the file to build and start the necessary containers in detached mode (-d option). The flag will force the rebuilding of the images before starting the containers. docker-compose.yml --build To check if the MySQL database inside the running container has all tables created successfully by the script on start, you can run the command: docker exec -it mysql-source mysql -uroot -p123456 source -e 'SHOW TABLES;' By running the above command, you can see a list of tables created in the database inside the container, which will confirm if the script has created all the tables successfully on start. source +------------------+ | Tables_in_source | +------------------+ | city | | country | | order_status | | product | | sale | | status_name | | store | | users | +------------------+ List of tables created on source Stream configuration This is the stream configuration file which is used to setup the database replication process. mysql2pg.json { "source": { "type": "mysql", "connection": "root:123456@tcp(mysql-source:3306)/source", "filter": { "tables": [ { "name": "product", "operations": ["insert"]}, { "name": "country", "operations": ["insert"]}, { "name": "city", "operations": ["insert"]}, { "name": "store", "operations": ["insert"]}, { "name": "users", "operations": ["insert"]}, { "name": "status_name", "operations": ["insert"]}, { "name": "sale", "operations": ["insert"]}, { "name": "order_status", "operations": ["insert"]} ] } }, "target": { "type": "postgresql", "connection": "postgres://postgres:postgres@postgres-target:5432/postgres" }, "limits": { "numberOfEvents": 0, "elapsedTime": 0 } } The field specifies the type of the source database as " " and the connection details to connect to the database, including username and password as well as the host and port. source mysql The field within the source field specifies that only certain tables and their corresponding operations (in this case " ") will be replicated. filter insert The field specifies the type of the target database as " " and the connection details to connect to the target database, including username and password as well as the host and port. target postgresql The field specifies that number of events and elapsed time are set to zero (0), which means that there are no limits in place for this replication process. limits It is also worth noting that according to this config, only insert operations will be captured on the tables specified in the filter field. Send configuration to DBConvert Streams API. docker run -t --rm \ --network sales-db_default \ curlimages/curl \ --request POST \ --url http://dbs-api:8020/api/v1/streams\?file=./mysql2pg.json This command runs a command to start a new container from the image. It specifies that the container should join the network named using option. docker run curlimages/curl sales-db_default --network This container will then run the command to make a HTTP POST request to the url . The URL contains an endpoint that is the dbs-api service which is running on port 8020 and is expecting a json file as a query parameter. This command creates a new stream on the dbs-api service with the configuration specified in the file. curl http://dbs-api:8020/api/v1/streams?file=./mysql2pg.json mysql2pg.json It's important to note that this command assumes that the network and the service are already created and running. It also assumes that the file is in the current working directory from which the command is run. sales-db_default dbs-api mysql2pg.json This is a JSON response indicating that the stream creation was successful. {"status":"success", "data":{ "id":"2KGlt8BCHLT0lXklrs5wqM6n7BQ", "source":{...}, "target":{...}, "limits":{} } } It contains the following fields: : This field indicates the status of the request, in this case " " status success : This field contains the details of the stream that was created. data : This field contains a unique identifier for the stream, in this case "2KGlt8BCHLT0lXklrs5wqM6n7BQ" id : This field contains the details of the source database, including the type, connection details, and filter settings. source : This field contains the details of the target database, including the type and connection details. target : This field contains the limits for the replication process, such as number of events and elapsed time. limits Note that the details of the source and target field are not given here for brevity, it is just shown as ... Check if tables on the target are created successfully. 💡DBConvert Streams creates tables with the same structure as the source on the target if they are missing. At this point, all tables specified in the filter should exist on the Postgres target database. To connect to the Docker container and check if tables exist, you can run the following command: postgres-target docker exec -it postgres-target psql -U postgres -d postgres -c '\dt' By running the above command, you can see a list of tables created in the database, which will confirm if DBConvert Streams has created all the tables successfully. postgres-target List of relations Schema | Name | Type | Owner --------+--------------+-------+---------- public | city | table | postgres public | country | table | postgres public | order_status | table | postgres public | product | table | postgres public | sale | table | postgres public | status_name | table | postgres public | store | table | postgres public | users | table | postgres (8 rows) Populate the source with sample data. Now that the and databases have identical table sets with the same structure, it is time to find out if the streaming of data works properly. This can be done by inserting data into the database and observing if the same data is replicated to the database. mysql-source postgres-target mysql-source postgres-target -- Set params SET @number_of_sales = '100'; SET @number_of_users = '100'; SET @number_of_products = '100'; SET @number_of_stores = '100'; SET @number_of_countries = '100'; SET @number_of_cities = '30'; SET @status_names = '5'; SET @start_date = '2023-01-01 00:00:00'; SET @end_date = '2023-02-01 00:00:00'; USE source; TRUNCATE TABLE city ; TRUNCATE TABLE product ; TRUNCATE TABLE country ; TRUNCATE TABLE status_name; TRUNCATE TABLE users; TRUNCATE TABLE order_status; TRUNCATE TABLE sale; TRUNCATE TABLE store; -- Filling of products INSERT INTO product WITH RECURSIVE t(id) AS ( SELECT 1 UNION ALL SELECT id + 1 FROM t WHERE id + 1 <= @number_of_products ) SELECT id, CONCAT_WS(' ','Product', id) FROM t; -- Filling of countries INSERT INTO country WITH RECURSIVE t(id) AS ( SELECT 1 UNION ALL SELECT id + 1 FROM t WHERE id + 1 <= @number_of_countries ) SELECT id, CONCAT('Country ', id) FROM t; -- Filling of cities INSERT INTO city WITH RECURSIVE t(id) AS ( SELECT 1 UNION ALL SELECT id + 1 FROM t WHERE id + 1 <= @number_of_cities ) SELECT id , CONCAT('City ', id) , FLOOR(RAND() * (@number_of_countries + 1)) FROM t; -- Filling of stores INSERT INTO store WITH RECURSIVE t(id) AS ( SELECT 1 UNION ALL SELECT id + 1 FROM t WHERE id + 1 <= @number_of_stores ) SELECT id , CONCAT('Store ', id) , FLOOR(RAND() * (@number_of_cities + 1)) FROM t; -- Filling of users INSERT INTO users WITH RECURSIVE t(id) AS ( SELECT 1 UNION ALL SELECT id + 1 FROM t WHERE id + 1 <= @number_of_users ) SELECT id , CONCAT('User ', id) FROM t; -- Filling of status_names INSERT INTO status_name WITH RECURSIVE t(status_name_id) AS ( SELECT 1 UNION ALL SELECT status_name_id + 1 FROM t WHERE status_name_id + 1 <= @status_names ) SELECT status_name_id , CONCAT('Status Name ', status_name_id) FROM t; -- Filling of sales INSERT INTO sale WITH RECURSIVE t(sale_id) AS ( SELECT 1 UNION ALL SELECT sale_id + 1 FROM t WHERE sale_id + 1 <= @number_of_sales ) SELECT UUID() AS sale_id , ROUND(RAND() * 10, 3) AS amount , DATE_ADD(@start_date, INTERVAL RAND() * 5 DAY) AS date_sale , FLOOR(RAND() * (@number_of_products + 1)) AS product_id , FLOOR(RAND() * (@number_of_users + 1)) AS user_id , FLOOR(RAND() * (@number_of_stores + 1)) AS store_id FROM t; -- Filling of order_status INSERT INTO order_status WITH RECURSIVE t(order_status_id) AS ( SELECT 1 UNION ALL SELECT order_status_id + 1 FROM t WHERE order_status_id + 1 <= @number_of_sales ) SELECT UUID() AS order_status_id , DATE_ADD(@start_date, INTERVAL RAND() * 5 DAY) AS update_at , FLOOR(RAND() * (@number_of_sales + 1)) AS sale_id , FLOOR(RAND() * (@status_names + 1)) AS status_name_id FROM t; fill_tables.sql script This script above starts by truncating all the tables in the database to clear any previous data, and then it inserts sample data into the tables. Each table is filled with sample data using a different set of parameters set at the top of the script. source To execute this SQL script, you can run the following command: docker exec -i \ mysql-source \ mysql -uroot -p123456 -D source < $PWD/fill_tables.sql Comparing number of records in source and target databases. Let's compare the number of rows in the tables of the source and target databases. docker exec -it mysql-source mysql -uroot -p123456 -D source -e "SELECT (SELECT COUNT(*) FROM product) as 'product_count',(SELECT COUNT(*) FROM country) as 'country_count',(SELECT COUNT(*) FROM city) as 'city_count',(SELECT COUNT(*) FROM store) as 'store_count',(SELECT COUNT(*) FROM users) as 'users_count',(SELECT COUNT(*) FROM status_name) as 'status_name_count',(SELECT COUNT(*) FROM sale) as 'sale_count',(SELECT COUNT(*) FROM order_status) as 'order_status_count';" How many records are in each table of mysql-source db? docker exec -it postgres-target psql -U postgres -d postgres -c "SELECT (SELECT COUNT(*) FROM product) as product_count,(SELECT COUNT(*) FROM country) as country_count,(SELECT COUNT(*) FROM city) as city_count,(SELECT COUNT(*) FROM store) as store_count,(SELECT COUNT(*) FROM users) as users_count,(SELECT COUNT(*) FROM status_name) as status_name_count,(SELECT COUNT(*) FROM sale) as sale_count,(SELECT COUNT(*) FROM order_status) as order_status_count;" how many records are in each table of postgres-target db? As you can see from the resulting output, all tables in both the source and target databases have an identical number of records in each table. Check statistics. The following command sends a GET request to the DBConvert API endpoint which retrieves the statistics of the current data stream. The command is used to format the JSON output for better readability. /api/v1/streams/stat jq docker run -t --rm \ --network sales-db_default \ curlimages/curl \ --request GET \ --url http://dbs-api:8020/api/v1/streams/stat | jq { "streamID": "2KHTjpsZAUCb8y1BZny3YKoX5qO", "source": { "counter": 635, "elapsed": "0s", "started": "2023-01-13T17:24:50.089257721Z", "status": "RUNNING" }, "target": { "counter": 635, "elapsed": "0s", "started": "2023-01-13T17:24:50.089649312Z", "status": "RUNNING" } } The above output shows the statistics of the current data stream. The "source" field shows the statistics of the source database, and the "target" field shows the statistics of the target database. The "counter" field shows the number of events that have been processed by the stream, the "elapsed" field shows the time elapsed since the stream started, the "started" field shows the date and time when the stream was started, and "status" field shows the status of the current stream. Prometheus metrics. Prometheus is a monitoring system that scrapes metrics data from various sources and stores them in a time-series database. DBConvert Streams collects its internal metrics in Prometheus format, allowing you to explore and visualize live data in dashboards. To view the collected metrics, visit in a web browser to access the Prometheus UI. http://127.0.0.1:9090 Conclusion Change Data Capture (CDC) systems like can be used to stream data from a MySQL database to a PostgreSQL database in real time, allowing you to keep the two systems in sync and take advantage of the unique features and capabilities of each database. DBConvert Streams This guide provided information on streaming data in one direction, from MySQL Binlog to PostgreSQL. contains more examples of configuring data streams, including from PostgreSQL Wals to MySQL and other configurations. These examples can serve as a starting point for setting up your own data stream tailored to your specific needs and use case. The DBConvert Streams Github repository Getting your feedback about DBConvert Streams is essential for the development team to improve the software and make it more useful for the community. By sharing your ideas, reporting bugs, and requesting new features, you can actively participate in the development of the software and help to make it more robust and useful for everyone. Your participation is valued and appreciated by the development team and the community. Also Published Here