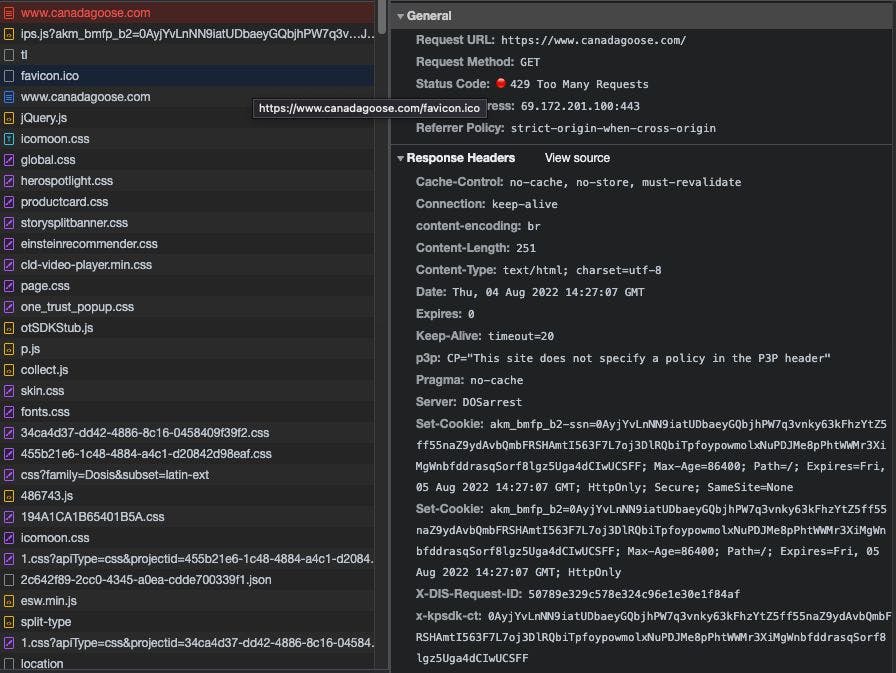
How to Scrape Kasada With Playwright, Undetected Chromedriver, and Other Tools Scraping Kasada-Protected Website During the past weeks, I’ve chatted with of about his recent discoveries about Kasada anti-bot software, . Dimitar Krastev Crawlio summarized in this Linkedin post These notes integrate what we noticed in our previous articles, like our or . Anti-Detect Anti-Bot matrix our latest post about the Bright Data Web Unblocker In this post, we’ll recap how we can scrape Kasada-protected websites using free and commercial tools. All the code can be found in our GitHub repository below. GitHub Free Readers repository What Is Kasada and How Does It Work? is one of the newest players in the anti-bot solutions market and has some peculiar features that make it different. Kasada You cannot identify a Kasada-protected website from Wappalyzer (probably the userbase is not so wide), but the typical behavior when browsing them is the following. First of all, Kasada doesn’t throw any challenge in the form of Captchas, but the very first request to the website returns a 429 error. If this challenge is solved correctly, then the page reloads and you are redirected to the original website. This is basically what they call on their website the Zero-Trust philosophy. Kasada assumes all requests are guilty until proven innocent by inspecting traffic for automation with a process that’s invisible to humans. And again: Automated threats are detected on the first request, without ever letting requests into your infrastructure, including new bots never seen before. To bypass these anti-bots, there are usually two ways: Reverse engineering the JS challenges, deobfuscating the code. Make our scrapers indistinguishable from humans browsing the web. Since the first option, while it’s great for understanding what’s happening under the hood, is time-consuming and does work only until the code is not changed, and always from their website, it seems that this happens frequently. Kasada is always changing to maximize difficulty and enable long-term efficacy. Our own proprietary interpretive language runs within the browser to deter attackers from deciphering client-side code. Resilient obfuscation levels the playing field by shifting the skillset from easy to reverse engineer JS to our own polymorphic method. Obfuscated code and the detection logic within are randomized and change dynamically to nullify prior learnings. All communications between the client and Kasada are encrypted. So, given that we need to make our scrapers more human-like as possible, let’s see what we can do to bypass it. Free Solutions with Chrome Playwright In , I’ve tested Kasada with Chrome with no success with the following setup, which has proven its reliability in time. our Anti-Detect Anti-Bot matrix Again, thanks to Dimitar and its post on the Crawlio page, I wanted to give it another try. So, I’ve modified my test scraper and reviewed the parameters used by Chrome, and it worked! I've left only a few options to disable the Chrome sandbox, the first run notice, and the automation-controlled flag, but I’ve added: ignore_default_args=["--enable-automation"] This behaves like the old ‘—disable-infobars’ option, which was used to not show the notice that “Chrome is controlled by an automated test service”. I was struggling to disable it when using Playwright and finally found that, in this way, I could disable it. I’ve also added the option: ‘--disable-blink-features=AutomationControlled’ The result was that I could open the first page of our target website without any trouble and info bar. With Firefox Playwright Another way to use to tackle Kasada is by opening a Firefox instance and loading the target website from it. Playwright We have already seen it working in the Anti-Detect Anti-Bot matrix, and the setup is pretty straightforward. Undetected Chromedriver The same can be said for the solution. Undetected Chromedriver In case you don’t know what the is, it’s basically a Chromedriver version specifically adapted for web scraping, with all the settings and configuration set up to be almost identical to a Chrome browser used by a real person. Undetected Chromedriver Without any additional setup, you can bypass Kasada’s challenge. Commercial Solutions With Playwright GoLogin Instead of opening a Chrome or Firefox browser, we can use browser and its multiple profiles offered to bypass Kasada. GoLogin’s In this case, we’re going to attach the script to an open GoLogin instance, but the result is the same. Playwright Bright Data Web Unblocker The last solution proposed; it’s always a commercial one, but it’s the only one that doesn’t require a headful browser. As we have seen , is a proxy API we can integrate into our Scrapy projects (or any other tool), and it automatically handles all the settings and features needed to bypass the Kasada challenge. in its product review the Bright Data Web Unblocker Final Remarks In my experience, Kasada has been a real issue for our web scraping activities until 2022, but with further studies on my side and tools and settings available, we now have plenty of options to bypass this solution. There’s no need to say that all web scraping activities should be done ethically, and all these techniques are needed to scrape only the data we are allowed to get. In this landscape, it’s interesting to see how far this cat-and-mouse game will still go on, at the cost of the user experiences and search engine positioning on websites heavily protected. Also published here