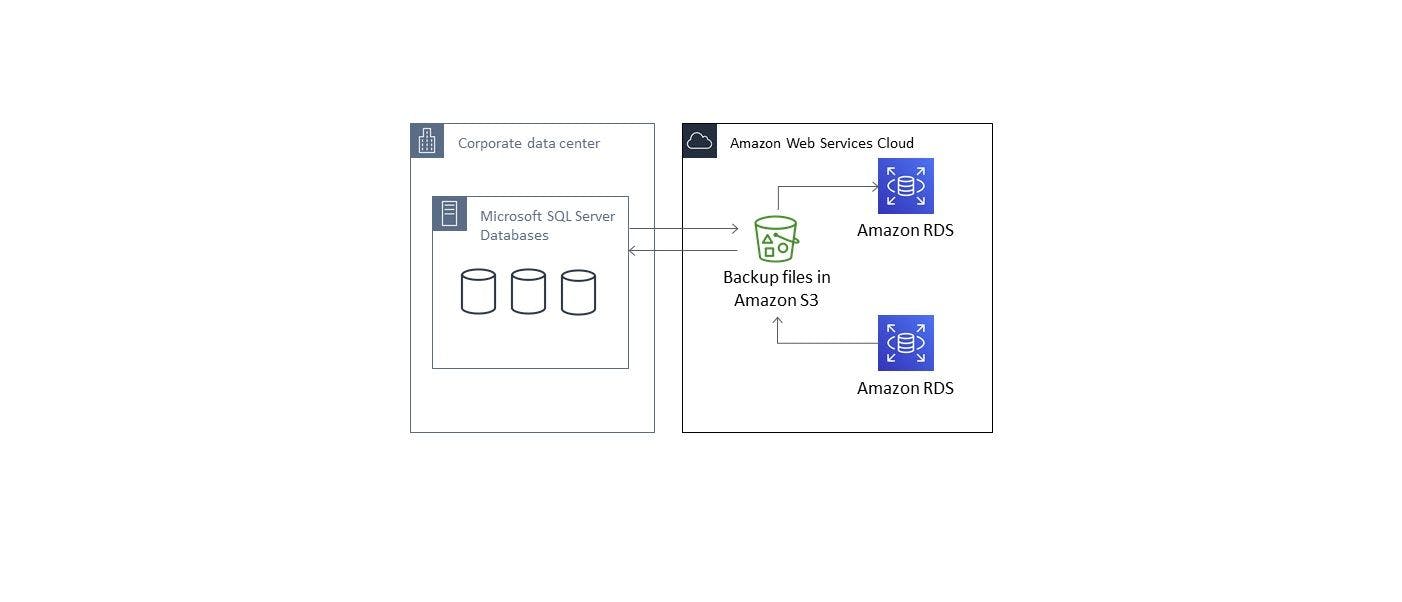
Introduction Nowadays, databases are used in almost all applications. They allow you to store various kinds of information. But today it is no longer necessary to have a dedicated server for databases; it is enough to have a subscription plan of a cloud provider. This will allow you to avoid such problems as when you missed the point of server maintenance and the database became unavailable. Moreover, using a cloud database will allow you to have the computing power that suits you and your cloud server will always cope with requests from users, or you will not have excess database server capacity. In addition, this will expose you to the maintenance of the database, and besides that, you will not need to deal with the management of the operating system on which the database is installed. Today, we have three major cloud providers: Amazon, Microsoft, Google. In the article, I will show you how easy it is to bring any of your MS SQL database to Amazon RDS, namely, how to create a database in the cloud, connect it to MS SQL Management Studio, create S3 bucket with restoring database file, create an Option Group and attach the option group to Amazon RDS, deploy a database from a backup copy, and show you the problem when restoring from MS SQL Management Studio. I would like to note, I note that this article was created for training and I will use a free tier AWS account and a free database from Microsoft. Creating Amazon RDS The first thing to do is create a database in Amazon RDS and configure it. Let's go to the RDS tab and choose to create a new MS SQL Server database. For our example, using the RDS Free Usage Tier is also fine but for real projects, if you have a large database, you need to think carefully about the correct instance size for the database (Image 1). By click next and set the RDS parameters, namely the version of SQL Server DB instance type. In the “DB insctece identifyer” section, select a name for the database and enter a username and password (Image 2). Next, we will move to the “Configure advanced settings” section and be sure to check the port, namely 1433 for MS SQL and indicate the VPC, if net we will create a new one and set Public accessibility to true Image 3. As you can see in Image 4, we have created a database. Connecting the database to MS SQL Management Studio There are many MS SQL database management systems out there, but I will use MS SQL Management Studio. Next, let's create a connection to the database. To do this, go to MS SQL Management studio and specify the parameters for connecting to the database, namely Endpoint (example is Image 5) and the login and password specified earlier. On a successful connection, you should see a list of databases from RDS. Since we do not have any database yet, we will only display “rdsadmin” database (Image 6) This completes the step. Now, we move to the next step. Creating an S3 bucket The second is to create an S3 bucket. It must be created in the same region as Amazon RDS. This condition is required and this is indicated by the Amazon documentation. Let's upload to the .bak file. To do this, let's create an S3 bucket in the same region, and this is important, and load the .bak file into the extension. For our example, I used Microsoft Adventure works, which is fine for our example, but for a real project, you should use your database .bak file (Image 7). This step is complete, we can move on to the next step. Creating an Option Group Third, we create a new option group, because by default no backups can be created in it. To do this, go to “Option Group in Amazon RDS” (Image 8) and click Create Group, since we cannot change the default group. Next, we will give a name to our group and indicate the engine and its version (Image 9) Next, add a new option to the option we just created and add SQLSERVER_BACKUP_RESTORE (Image 10) Next - we connect our option group instead of the default To do this, move on in the settings of our Amazon RDS and change the Option Group in the settings (Image 11) Next, we agree with the modification of the DB instance (Image 12) This step is complete, we can move on to the next step. Restoring the Database Fifth - connect and run the database recovery script. Now we just need to run the script to restore the database. To do this, move on to MS SQL Management Studio and create a new request following code: exec msdb.dbo.rds_restore_database @restore_db_name='CodeProjectDatabase', @s3_arn_to_restore_from='arn:aws:s3:::s3bucketrestore/AdventureWorks2016.bak' Where: is the DB name, - S3 bucket name AdventureWorks2016.bak is the name of the .bak file The result is shown in image 12. restore_db_name s3bucketrestore You can check the status using the command: exec msdb.dbo.rds_task_status The result should be successful, then your database is exactly restored (Image 13). Restoring the database from MS SQL Management Studio In this step, I want to show the reason that we have chosen such a long path to restore the database. As you know, the MS SQL Management Studio uses the Restore database command, but one does not work, as shown in Image 14. If you go to the MS SQL Management Studio and choose to restore the database, you will get the same error as I did. Conclusion In the article, I showed you how easy it is to bring any of your MS SQL databases to AWS RDS, namely, how to create a database in the cloud, connect it to MS SQL Management Studio, create an S3 bucket with restoring database file, create an Option Group and attach the option group to AWS RDS, deploy a database from a backup copy, and show you the problem when restoring from MS SQL Management Studio. Now everyone can do it by following these steps. References https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/SQLServer.Procedural.Importing.html