






Published on April 18, 2024
Listen to this Podcast
Published on April 18, 2024
Published on April 16, 2024

Published on April 15, 2024

PROMOTED










Javascript
"Not a real programming language" since 1995.

Published on October 17, 2022
Published on August 18, 2020

Published on October 16, 2022

Published on March 1, 2023

Published on February 12, 2021

Published on October 3, 2016

Published on November 6, 2022

Published on May 21, 2020

Published on April 16, 2018

Published on August 29, 2023
Devops
How Devs from Venus and Ops from Mars get along for fast and furious software development? Is DevOps with CI/CD the nitromethane to your SDLC?
The DevOps tag is sponsored by Aptible. Write a #DevOps story today to win from $18,000!

Published on August 7, 2023
Published on August 6, 2023
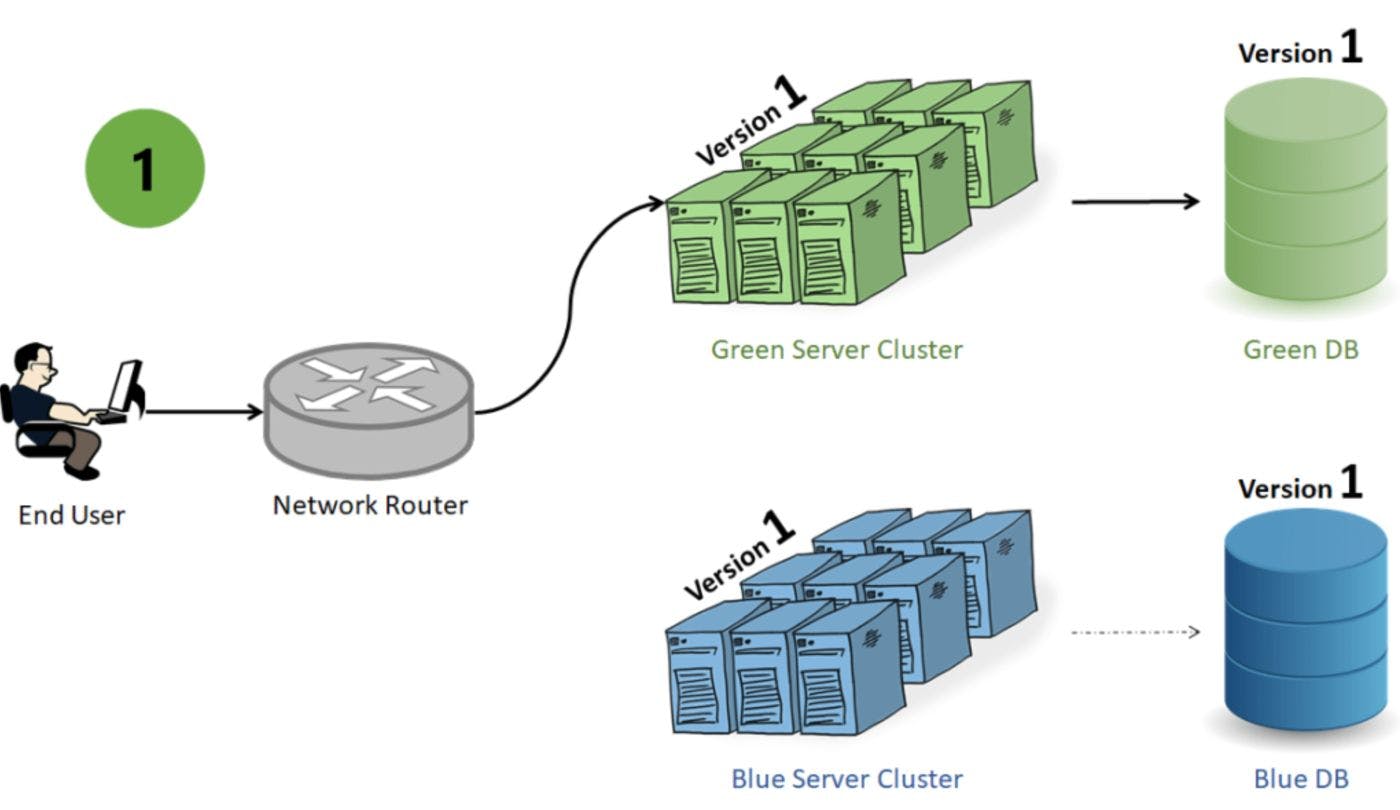
Published on August 9, 2023

Published on August 7, 2023
Published on August 8, 2023
Published on August 9, 2023
Published on August 7, 2023

Published on August 8, 2023

Published on August 7, 2023

Published on August 7, 2023
Python
I have this awesome Python library that -- wait, are you on 2 or 3?

Published on October 12, 2021
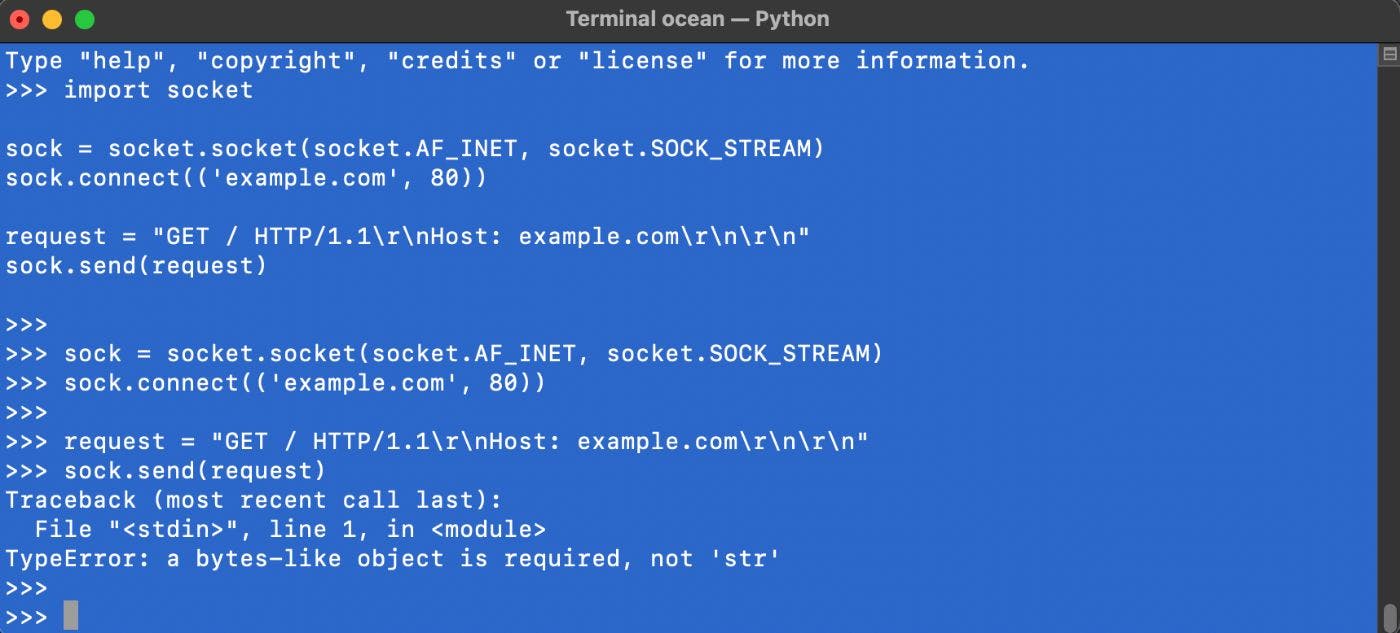
Published on April 6, 2023
Published on March 23, 2023

Published on November 23, 2022

Published on June 23, 2023

Published on July 18, 2022

Published on January 5, 2021

Published on November 26, 2018

Published on February 24, 2023

Published on September 20, 2023
Programming
"Programming today is a race between software engineers striving to build bigger and better idiot-proof programs, and the Universe trying to produce bigger and better idiots. So far, the Universe is winning." - Rich Cook, The Wizardry Compiled.

Published on September 2, 2021

Published on August 18, 2023
Published on January 13, 2023
Published on October 16, 2023

Published on November 14, 2020

Published on August 25, 2023

Published on September 30, 2023

Published on August 18, 2023
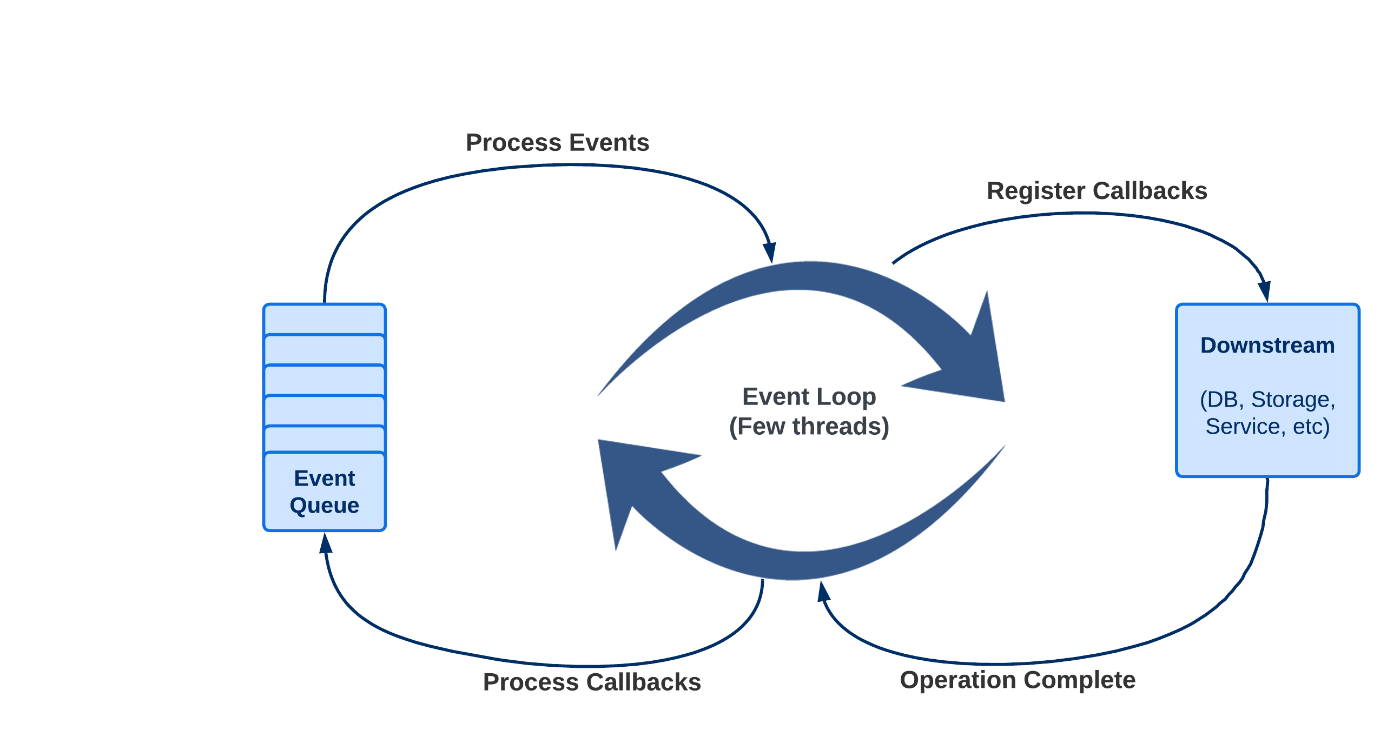
Published on April 27, 2023

Published on September 4, 2023
Web Development
HTML/CSS, Javascript, Angular, React, and other stories by those who build the frontend of the Internet.

Published on January 31, 2023

Published on February 5, 2023

Published on September 14, 2023

Published on January 8, 2021

Published on March 18, 2023

Published on May 29, 2023

Published on March 10, 2023

Published on March 2, 2023

Published on October 11, 2023

Published on August 22, 2017

Published on August 17, 2023
Coding
“Any fool can write code that a computer can understand. Good programmers write code that humans can understand.” ― Martin Fowler

Published on June 16, 2022
Published on June 18, 2020

Published on September 17, 2018

Published on November 7, 2019

Published on April 27, 2023
Published on July 3, 2017

Published on June 26, 2023
Published on April 9, 2024

Published on October 28, 2023

Published on May 2, 2020
Typescript
Javascript's superset, pedigree if you will, providing additional syntax and a more seamless integration with your editor.

Published on October 10, 2022

Published on November 2, 2022

Published on February 26, 2024
Published on October 18, 2022

Published on October 11, 2023

Published on February 26, 2024

Published on May 12, 2023

Published on July 12, 2023
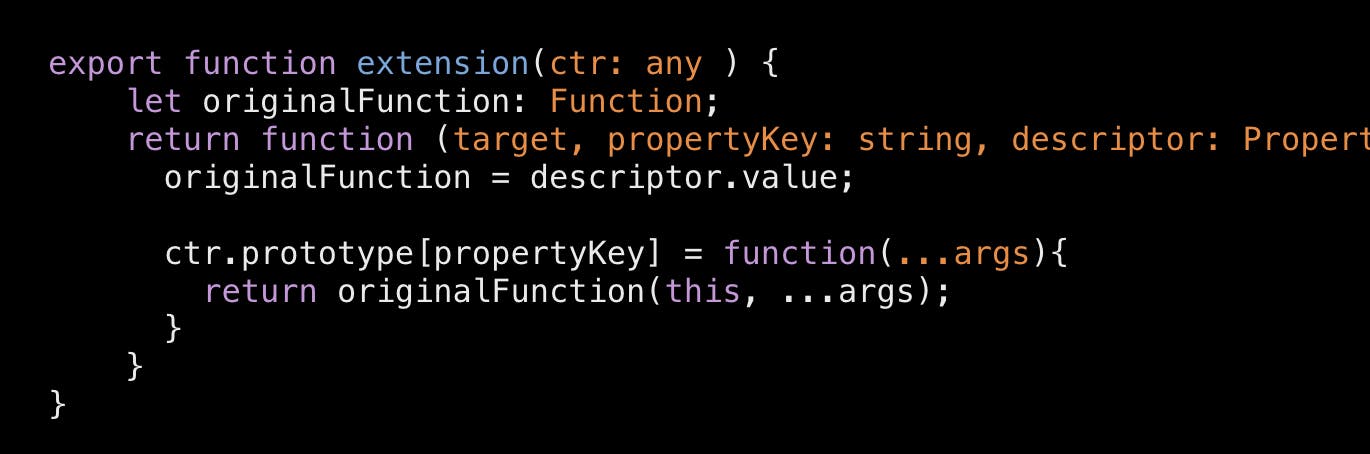
Published on January 8, 2020

Published on June 21, 2023
Dotnet
Published on February 20, 2024

Published on April 12, 2024

Published on April 15, 2024

Published on April 15, 2024

Published on April 11, 2024

Published on April 16, 2024

Published on April 10, 2024

Published on April 6, 2021

Published on April 4, 2024

Published on August 14, 2023
Domain Driven Design

Published on March 18, 2024

Published on February 16, 2023
React
Reteaching people basic web skills since 2013.

Published on June 21, 2023

Published on January 8, 2024

Published on June 28, 2022

Published on June 6, 2023

Published on January 4, 2024

Published on August 30, 2023

Published on January 3, 2024

Published on May 25, 2023
Published on September 2, 2019

Published on February 2, 2023
Other programming stories published today
You Don’t Need JavaScript Native Methods!
Thanga Ganapathy
How to Use Stackalloc: Day 28 of 30-Day .NET Challenge
Sukhpinder Singh


