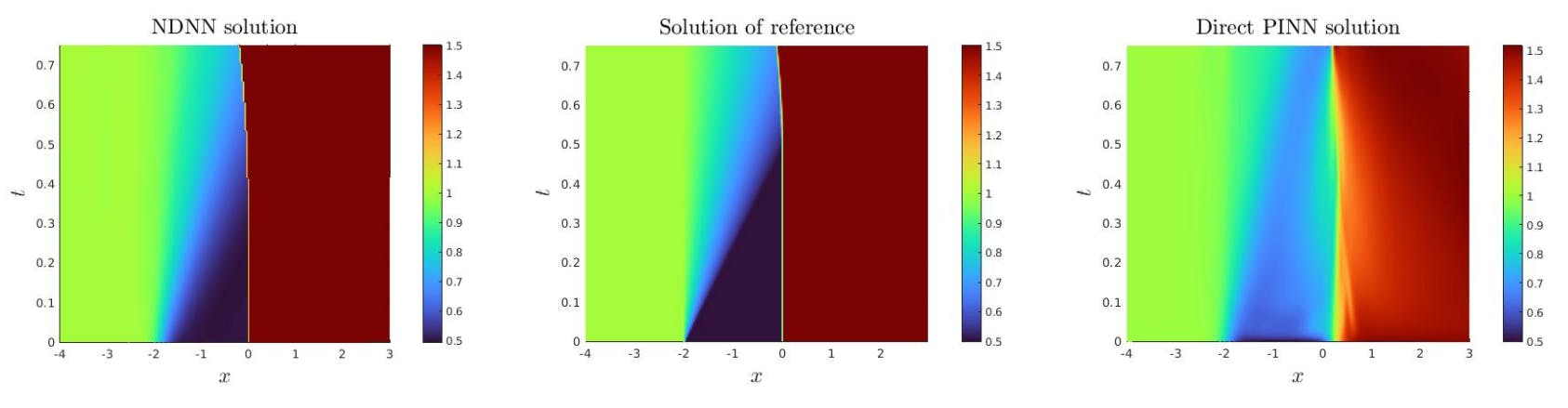
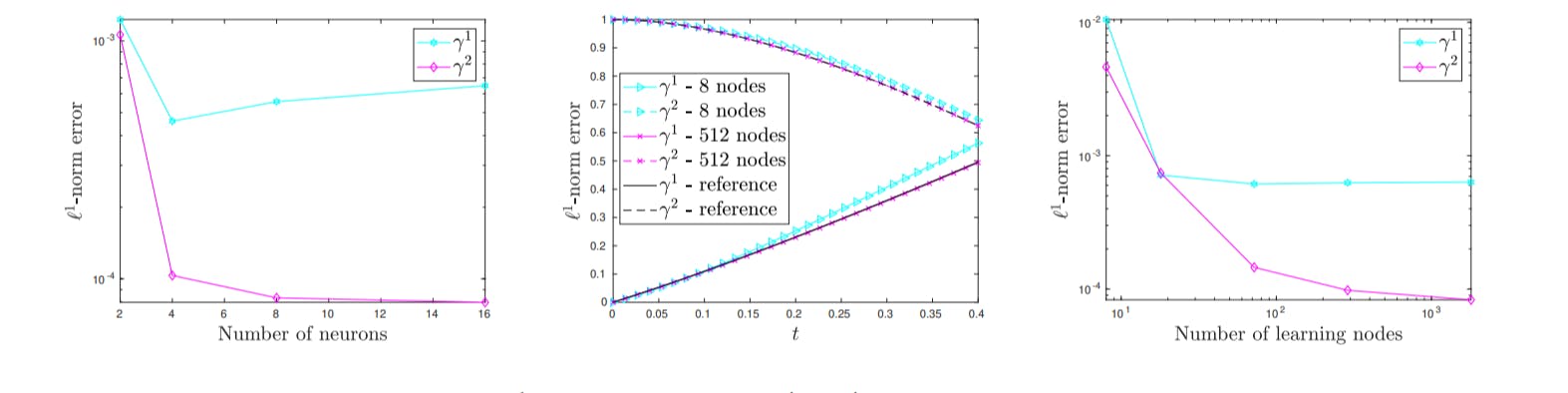
195 reads
How Scientists Taught AI to Handle Shock Waves
by byHyperbole@hyperbole
byHyperbole@hyperbole
Amplifying words and ideas to separate the ordinary from the extraordinary, making the mundane majestic.
September 20th, 2025





Audio Presented by
Amplifying words and ideas to separate the ordinary from the extraordinary, making the mundane majestic.
Story's Credibility


Amplifying words and ideas to separate the ordinary from the extraordinary, making the mundane majestic.
Story's Credibility
About Author

Amplifying words and ideas to separate the ordinary from the extraordinary, making the mundane majestic.
Comments