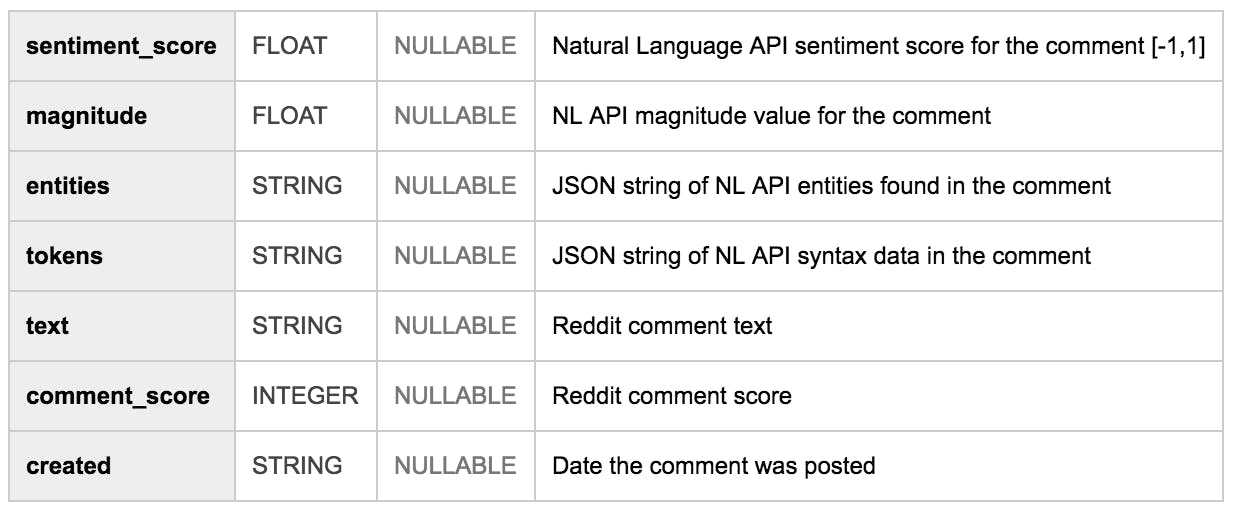
In honor of today being , I thought it would be interesting to do some NLP on Reddit comments about marijuana (shout out to for this idea!). My teammate has conveniently made , so I took a subset of those comments and ran them through Google’s . April 20th Yufeng Guo Felipe Hoffa all Reddit comments available in BigQuery Natural Language API The comment data I looked only at comments from the November 2016 table since a lot of marijuana legislation was passed during that time Of 71 million comments during November 2016 . 49,717 comments (.07%) contained the words ‘marijuana’ or ‘cannabis’ For quality control, I looked only at comments with Reddit score > 100. I also narrowed the dataset to English comments. That left me with . Here’s my BigQuery schema: 12,789 comments to analyze Number of comments by day in November 2016 What did the volume of pot-related comments throughout November look like? We see a big spike in the number of comments around the election, which makes sense: seven states changed their marijuana laws during the 2016 election. What adjectives do people use when they talk about pot? The Natural Language API’s syntax analysis method tells us the part of speech of each word in a sentence, which makes it easy to get all of the adjectives used in these comments. Which adjectives were used most frequently in conjunction with ‘marijuana’ and ‘cannabis’? I also wondered if the top adjectives used each day changed throughout the month. Making use of BigQuery’s handy I used this query to find the top 3 adjectives used each day: partitioning SELECT * FROM (SELECT day, adjective, count(*) c,row_number() over(partition by day order by count(*) desc) seqnumFROM `sara-bigquery.reddit_pot_nlp.adj_day`GROUP BY 1, 2ORDER BY day, c desc)WHERE seqnum <= 3ORDER BY day Here’s a snippet of the output from November 5th to the 10th (the 4th column is the number of mentions for a word, and the last column is from the query above): seqnum We can see that ‘good’, ‘more’, ‘other’ and legal were part of the vocabulary throughout the month, but during the election the adjectives ‘medical’ and ‘recreational’ came into play. What else do people talk about when they talk about pot? The Natural Language API’s endpoint can tell us! It will extract any known entities from our text, along with their Wikipedia URL if it exists. Here are the most common entities mentioned in conjunction with marijuana on Reddit: analyzeEntities Get started with your own text Want to do this sort of thing on text that’s not related to marijuana? That’s cool too. This NL analysis can be applied to any sort of text — news articles, customer service feedback, speech transcriptions, and more. You can try out the Natural Language API with your own text. For example, here’s the results of syntax annotation on one of the comments from my dataset above: directly in the browser If you want to follow the approach I used in this analysis, here are the steps: Get the you’d like to analyze from BigQuery. Download the results as JSON to a local file Reddit data Reading from the local file, send the text to the NL API and write the NL output to a separate file. You can do this from your favorite language, I used Node.js — . code here Upload your newline delimited JSON file to BigQuery, it can automatically detect the schema: Go forth and process your text! Extra: training a custom text model with word embeddings Machine learning APIs are pretty magical in that they take your data and give you back detailed information about it — all without requiring you to think about what’s happening under the hood. You can think of it kind of like ordering a pastry: you provide money and a bakery gives you back a chocolate chip cookie. This will result in a delicious cookie a lot of the time, but sometimes you may decide you want to add white chocolate chips or toffee bits to your cookie. In this case you’re going to have to it, which likely involves making it yourself even if it may ruin some of the magic. After you’ve gotten over this fear you can either use a recipe someone else has written (BYO ingredients) or live dangerously and write your own. customize The machine learning equivalent of making your cookie from scratch is building and training a model with your own data. I’ve recently started exploring this side of machine learning by looking at : a model for learning the relationships between words in a dataset. As the name implies, it takes words as input and outputs : a vector representation of a word in a set of text. word2vec word vectors Using the word2vec and , I fed the model a subset of the Reddit comment data (~55k words, 8k unique) to generate a visualization of word embeddings: sample on GitHub this tutorial Word embeddings essentially map words to vectors by extracting the meaningful words from a large text dataset and determining the semantic relationship between them. We can see in the visualization above that the model did a pretty good job clustering related words together: ‘rights’, ‘laws’, and ‘legalization’ are grouped together, as is ‘marijuana’ and ‘cannabis’. I could use this trained model to predict the topic of a comment or generate a new comment. I’m just getting started with custom models, so I’d love to hear your feedback and suggestions! Leave a comment or find me on Twitter . Next steps? Sara Robinson Want to do more cannabis analysis? My colleague has made genomics data for 1000 cannabis strains available in BigQuery. , or head over to BigQuery to check out the . Allen Day Details here public dataset