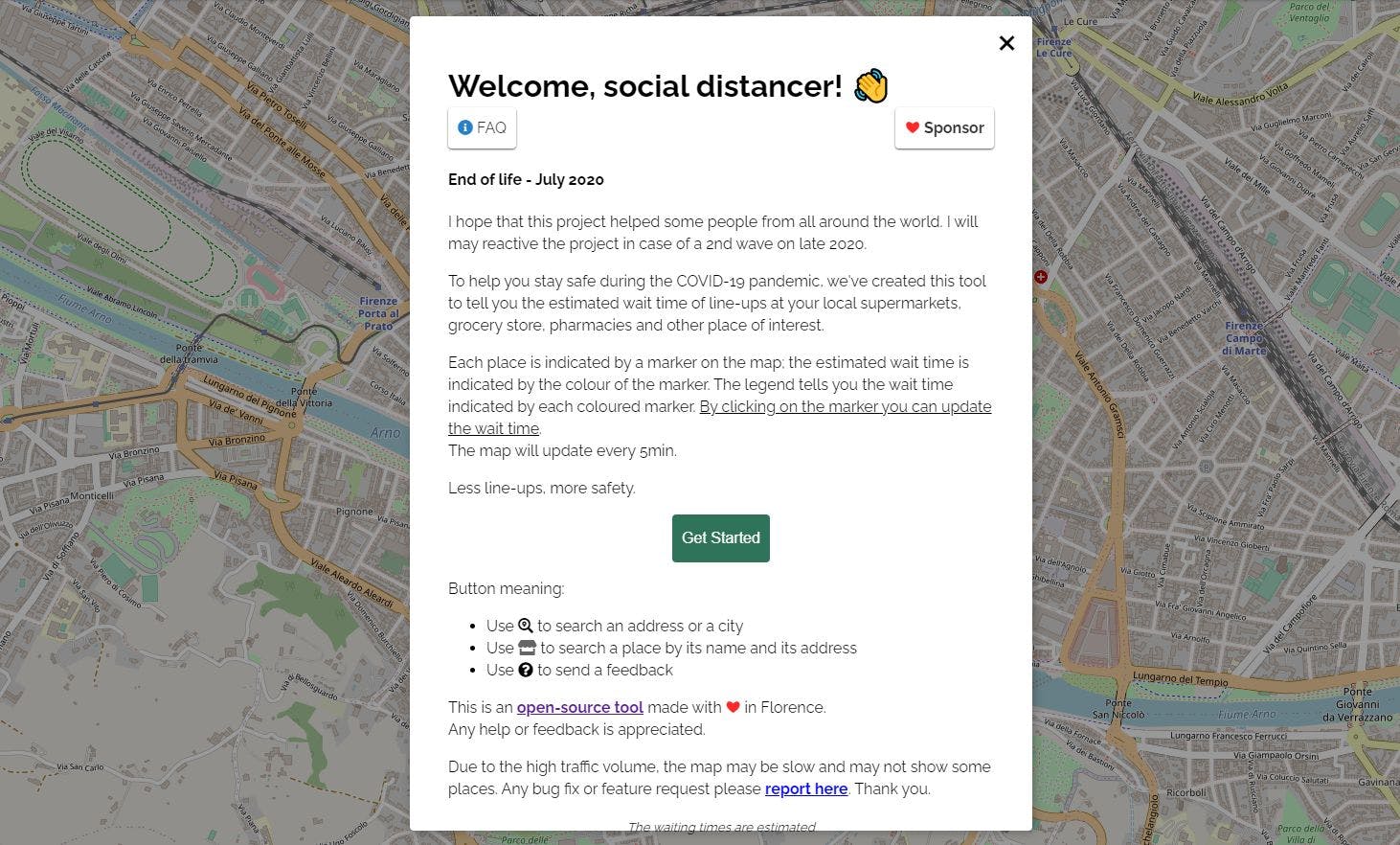
The context In March 2020, the world froze. A damn virus has spread across the globe and people have locked themselves up in their homes, safe. Getting out was a risk. Go shopping, another one. The problem is that the longer you stay out and in contact with other people, the more likely you are to contract the virus. Especially in closed and unventilated environments. The project that I am presenting to you was created primarily for personal use and then, by word of mouth, it was used worldwide (geographically). The project was not for profit but only to help others. Since June 2020, it has been discontinued due to the slight improvement in cases and the clarity that has been made about the virus, as well as the various security measures that have been applied at the health level. The reason why In the days following the global lockdown, supermarkets, pharmacies, and parapharmacies were attacked by people in search of basic goods and necessities. Immediately after the announcement of the lockdown, many supermarkets struggled to manage the influx of people, forcing them to gather outside the supermarket, standing in line, and waiting to enter the building. The gathering of people in line in front of shopping malls and pharmacies made me think. Why not create some sort of tracking based on Google Maps data? Kind of how it works for traffic. So the goal was to create a map with the various points of interest, such as food, bakers, pharmacies, supermarkets, liquor stores, etc. where the waiting times retrieved by Google were shown (at the time this API was not public, that is, there was no endpoint, while now it *) giving the user the possibility to add temporal feedback for the store in which he was located. The use of the map aimed to schedule the exit of the house towards our point of interest at the moment in which there was the least waiting time to enter. Crowdsourcing was then fundamental for the success of all this, since Google's data is based on the time, the popularity of the place, and how many devices are nearby. User feedback was therefore crucial. * Google now displays the wait data in one place directly in Maps. Costs The project is open source and development costs are not considered as those developed for personal use and then immediately shared publicly. At the start of the whole project, i.e. Redis, API backend in Python and the frontend resided on my Raspberry PI 3B model. After about 7 days from the publication online, the site already counted about 10K visits per day and Raspberry was no longer able to satisfy the requests at the same time. So I decided to move everything to the cloud using OVH and DigitalOcean for the backend and Github Pages for the frontend. The backend, with Redis and the API in Python, I replicated on 4 VPS in the cloud divided as follows: 3 DigitalOcean (New York, London, San Francisco) and OVH (Europe). The specifications were almost the same, that is 2GB of Ram and 3.2GHz dual-core. In total, I spent about $ 25 per month. The total is $ 75 for 3 months. For the domain, not being a commercial project, I reused my former domain thejoin.tech, creating the subdomain https://covid19-waiting-time.thejoin.tech/ The included traffic was 10GB per month, so it wasn't a backend issue. By importing, via git, all the setup on the Cloud allowed me to satisfy (in the whole life cycle) more than 1Mln of users and more than 2.1Mln of sessions in 3 months of the life of the project with more than 1.5K contemporary user. How it worked I'll briefly explain the idea and the mechanism behind it. For the more technical part, I leave you the link to the post. The Github repository is available on my profile: https://github.com/TheJoin95/covid19-market-waiting-times The idea was born with a simple map created in JS (using Leaflet.js) where the various markers of the various points of interest were added, previously retrieved from the Here and Google API. The data was persisted on Redis and, thanks to the Geo operator, could be easily searched through geospatial queries in order to provide geo-localized data and markers. Redis was the most logical choice to provide fast, precise responses and with a TTL on persistence to the various requests so as not to overload the memory. All the functionalities, from the search by location or by address/place to the WebIAM through to the map navigation and crowdsourcing features have been developed incrementally and thanks to the help of some contributors for the graphic part. All this within 25 days, after 8 hours of work. The front-end does not use any framework other than the task runner Grunt to be able to include the various pieces of HTML, minify the CSS / JS / HTML files, and the web workers to be able to use it in the form of PWA (progressive web app). This choice made development very fast with no dependency or compatibility issues. However, compatibility is guaranteed both on mobile (being responsive) thanks to polyfill. The APIs were instead developed in Python and deployed on the 4 instances mentioned above and use Flask as a micro-framework for API and uWSGI as a web server. I must say that uWSGI was the best choice due to the low level of configuration it makes available to us. Turn-ups There have been a lot of likes, tweets, and shares on all kinds of social media and blog/news sites. I was really pleased to help people all over the world, to receive negative and positive feedback in order to improve a tool that was helping thousands of people in the same situation and with the same problem. It was certainly one of the best projects I've worked on and I've had the pleasure of dedicating time to, as well as my passion. Understanding how a prototype released locally on the Raspberry at home to then be made public for friends and then globally taught me a lot… this project was aimed at helping myself, but in the end, it also helped other people. I may not have solved many problems or complexities, but the testimonies make me understand that there was a little help… and this is enough for me.