





289 reads
Generating Unique Values for Test Data in MySQL
by Yuri DanilovMarch 15th, 2023





Too Long; Didn't Read
In the [previous article] we looked at the possibilities of writing tests for MySQL. We eventually created a script that provides the results in a structured way. There are a number of refinements that can improve the test execution experience. One of them concerns using unique values for some text fields.
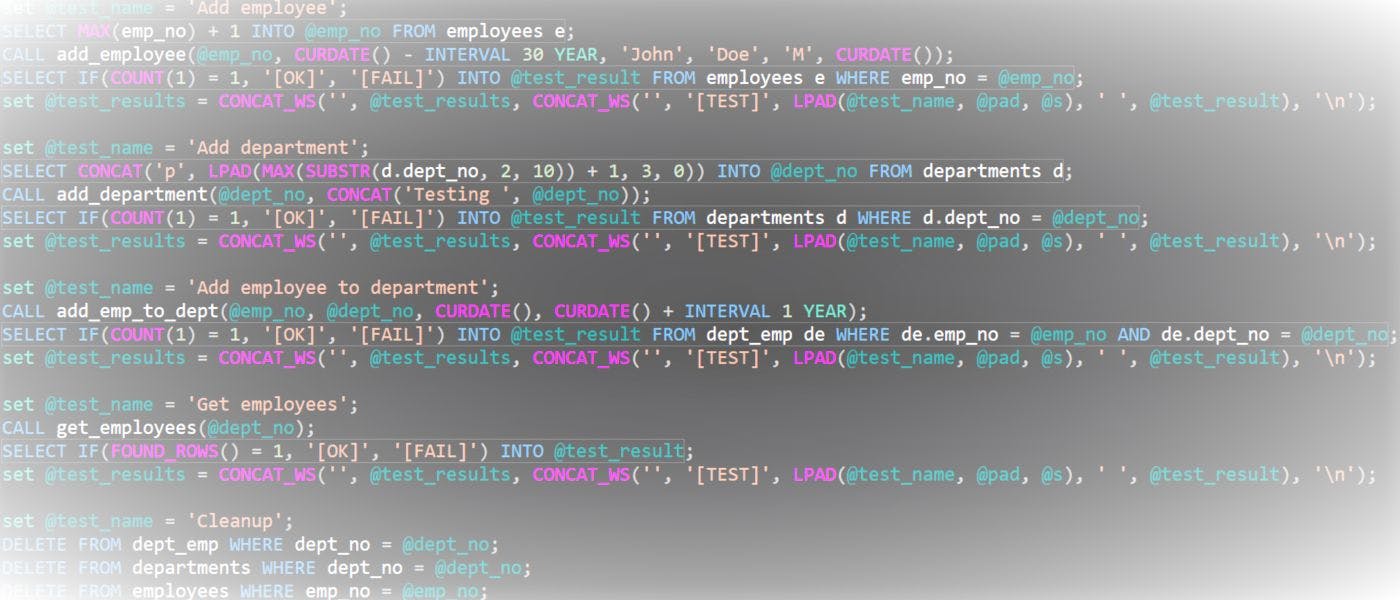

In the previous article, we looked at the possibilities of writing tests for MySQL, and eventually created a script that provides the results in a structured way.
However, there are a number of refinements that can improve the test execution experience.
One of them concerns unique values.
Reasons for Using Unique Values
It makes sense to generate unique values for some text fields for each run of the script for three main reasons:
-
For fields requiring uniqueness
-
To delete test data in tables without primary keys
-
To delete test data in case of an error while executing the script
In the first case, there is a possibility that the text data of the script will coincide with those already existing in the database being tested.
In the second, you need a field that is an alternative to the primary key. In the third, due to the linearity of the script structure, if an error occurs at any of the stages, the script execution will be interrupted, and the test data deletion block will not be executed.
In this case, the IDs of the created test records will be lost. There are also less obvious reasons for generating unique values.
Let's consider the ways of their generation.
Ways of Generation
Based on date and time:
SELECT DATE_FORMAT(NOW(6), '%Y%m%d_%H%i%s.%f');
In most cases, the tests are not run very frequently, then you can use the date and time with microsecond precision.
Based on a random value:
SELECT MD5(RAND());
Based on a universal unique identifier using a built-in database function:
SELECT UUID();
Based on connection ID:
SELECT CONNECTION_ID();
You can also use the connection ID to distinguish between the data generated by different connections executing the test script.
The Length
The length of a unique value can be limited using an appropriate format or function (such as uuid_short) and can be extended by concatenating two or more unique values. Based on the previous statement, it follows that these methods can be combined.
The examples given allow us to achieve uniqueness, but it is still difficult to select records generated in this way. To do this, it is convenient to use a certain prefix, which will be constant, but it will not be contained in the real data in the database.
This may be a combination of characters that is impossible (or unlikely) to type from the keyboard or the way in which real data gets into the database.
For example, a prefix like this:
set @prefix = '─TEST─';
It looks like a regular string with a dash, but when typed from the keyboard, a normal dash (or minus sign) has code 45, while here, the character code is 196.
Currently, most text fields are stored in utf8 encoding (or similar, which supports a large set of characters), so it will not be difficult to find the desired combination.
Actually, the Process
As a result, unique values will be set by the commands:
set @prefix = '─TEST─';
set @uid = CONCAT(@prefix, DATE_FORMAT(NOW(6), '%Y%m%d_%H%i%s.%f'));
An example of a test string identifier:
─TEST─20230314_170915.645455
Eventually, to delete test data, it is enough to execute commands like this on all the tables where this data was created:
set @prefix = '─TEST─%';
DELETE FROM users WHERE NAME LIKE @prefix;
In the case of foreign keys, you can select IDs by prefix, and delete them:
DELETE FROM user_items WHERE user_id IN (SELECT id FROM users WHERE name LIKE @prefix);
DELETE FROM users WHERE NAME LIKE @prefix;
Some Limitations
It should be noted that commands with a search by like, in most cases, will be executed without using indexes, i.e., lead to a full scan, which may affect performance. Therefore, it is reasonable to adhere to the following rules when deleting test data by prefix:
- Do not perform deletion every time you run the test, if possible.
- Perform deletions at specific intervals.
- Use the flag of correct completion of the test script, and perform the deletion only in case of an error.
- Restrict search with additional filters, e.g., by date (last week or day)
Using these principles will help make the test data management process more efficient.

L O A D I N G
. . . comments & more!
. . . comments & more!
About Author

TOPICS
THIS ARTICLE WAS FEATURED IN...



RELATED STORIES



A Basic Guide to MySQL Tests Automation #mysql
Apr 25, 2023


139 Stories To Learn About Cicd #cicd
Apr 11, 2023



