
398 reads
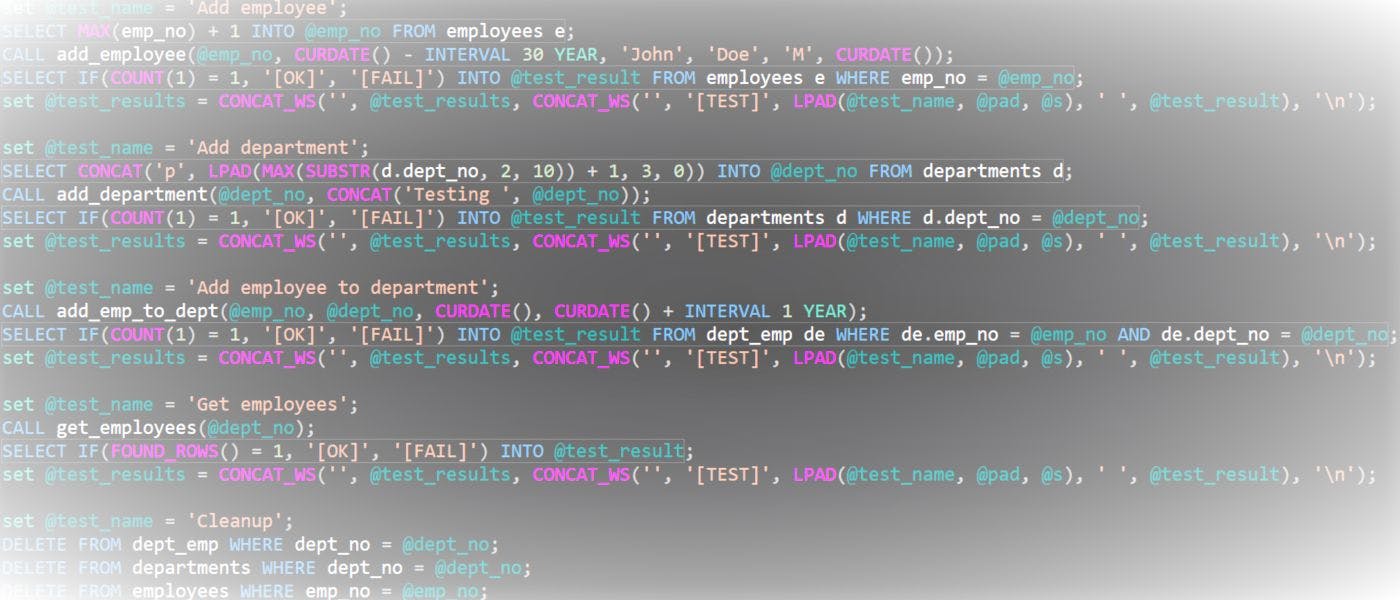
Generating Unique Values for Test Data in MySQL
by
March 15th, 2023






Story's Credibility


Story's Credibility
About Author

Software Developer
Comments

TOPICS





Related Stories










5 Best Microservices CI/CD Tools You Need to Check Out
@ruchitavarma
Sep 13, 2021