10,050 reads
Exploding And Vanishing Gradient Problem: Math Behind The Truth





Too Long; Didn't Read
<strong>Hello Stardust!</strong> Today we’ll see mathematical reason behind exploding and vanishing gradient problem but first let’s understand the problem in a nutshell.People Mentioned
Companies Mentioned


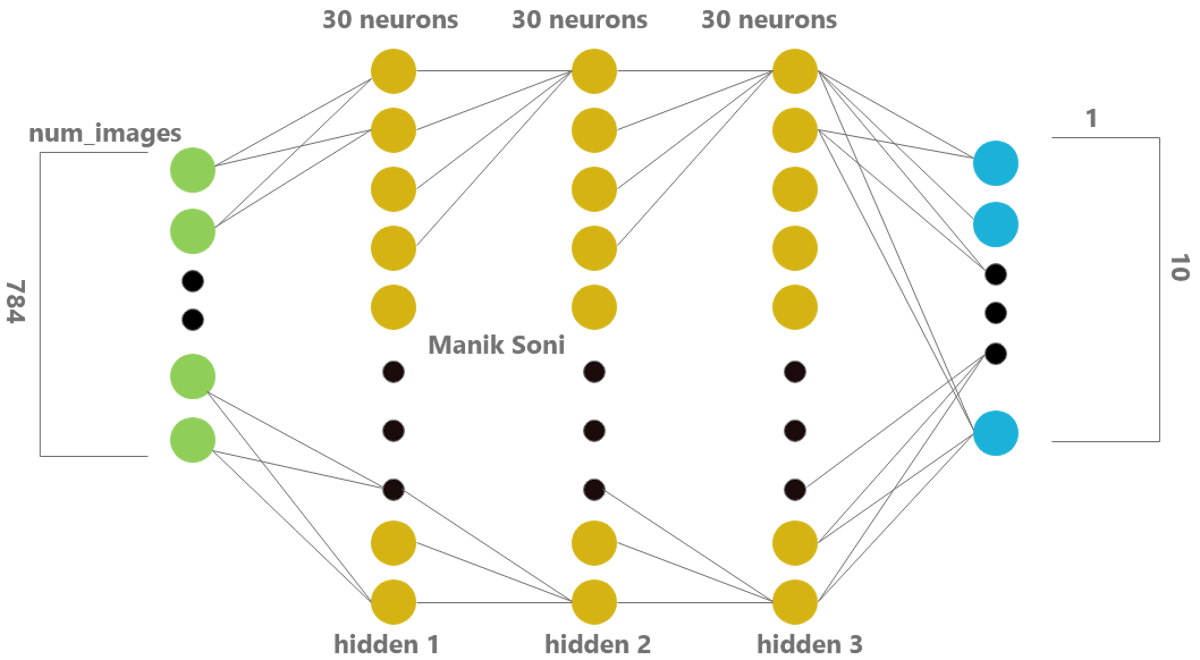



Manik Soni
@maniksoni653
SDE @Amazon
Learn More
LEARN MORE ABOUT @MANIKSONI653'S
EXPERTISE AND PLACE ON THE INTERNET.
EXPERTISE AND PLACE ON THE INTERNET.

L O A D I N G
. . . comments & more!
. . . comments & more!