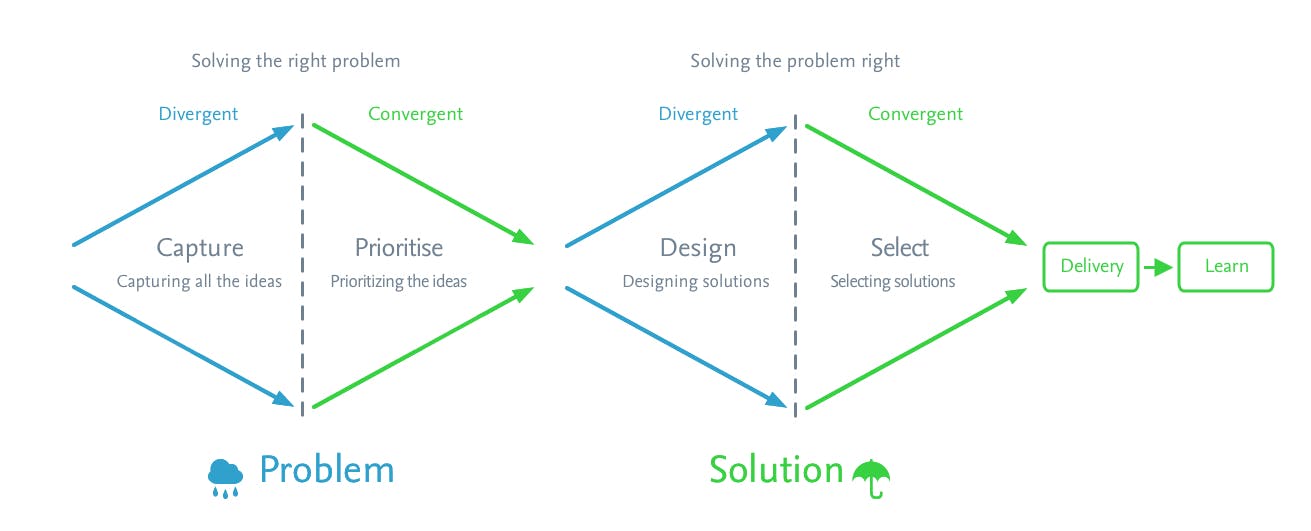
Discovery is undertaken in two steps with continuous iteration within each step. Step one is ensuring we are and step two is ensuring we are . This post is about step one in this process, AKA diamond one (D1) - . I started this series with an . Again thanks to the . solving the right problem solving the problem right my previous post explains step two, AKA diamond two (D2) overview of how to apply the double diamond to product discovery British design council for their very awesome double diamond Whilst D2 involves a lot of doing e.g experimenting, and failing efficiently, D1 involves a lot of pondering - data informed pondering. Doing a great job in D2 is pointless if we haven’t done due diligence in D1 - remembering from the that building awesome products that nobody uses, is not that awesome. So making sure we are solving the right problem is the key to being awesome ¯\_(ツ)_/¯. This is why D1 is the foundation of the product. original post Diamond one is the foundation of the product D1 is where strategy comes in to play. The strategy is normally coming from the c-suite supported by the strategy team who undertake massive amounts of research to determine the long term (3 to 5+ year) direction of the company. As product managers, it is our job to ship products which support this strategy. This can be referred to as the "business impact" of our products. As product managers, it is our job to ship products which support this strategy The first thing is which "customer outcomes" will have the most “business impact” - i.e which customer problems can we solve to deliver business value. we need to learn One way to do this is the driver tree. The driver tree, not to be confused with an inverted funnel, is the practice of starting with the metric we want to increase - the “thing we optimizing for” - and then branching out to all the things that drive that metric (driver trees need to be an entire post). These drivers are the levers which the product may be able to influence. This is where we undertake divergent (exploratory) user research - using the customer advisory board (CAB) and key internal stakeholders, for example the support organisation, speaking to support teams and looking at support tickets/feedback. Also deep diving into the available analytics. This is iterative. As new ideas for problems worth solving arise we are validating these problems with users using convergent (validation) user research. Convergent and divergent. Rinse and repeat. Once we have established which drivers we think the product can influence (i.e. which customer problems we think we can solve) we can carve out some inspirational objectives. Next we need to define concrete metrics which can be delivered within three months - key results. It is super important to work closely with your data analyst to ensure that the metrics are sound i.e. the metrics measure what you want they can be pulled from the data that you can get. and There is much written about OKRs, and I am no expert, but as a practitioner I can testify that having inspiring objectives which support the organization's strategy coupled with metrics which measure progress toward those objectives works pretty well. It is this framework which I use to evaluate problems/opportunities in D1. If solving a problem does not potentially move the needle on one of the key results, the idea goes to the bottom of the list - but try to avoid ‘decision debt’ - if an idea is totally ridiculous, it should be clear that this is the case. It’s only fair. In summary Looking at D1 we first apply divergent thinking - what are all the problems we could be solving - followed by convergent thinking - what problems should we be solving for our customers which move the needle on a metric we care about. This identifies which opportunities feed into D2. I mentioned D1 is the foundation of our work, and there is a lot of thinking involved - but don’t overthink it. We just don’t want junk going into D2. We can do an awesome job in D2 but building awesome products that nobody uses, is not that awesome.