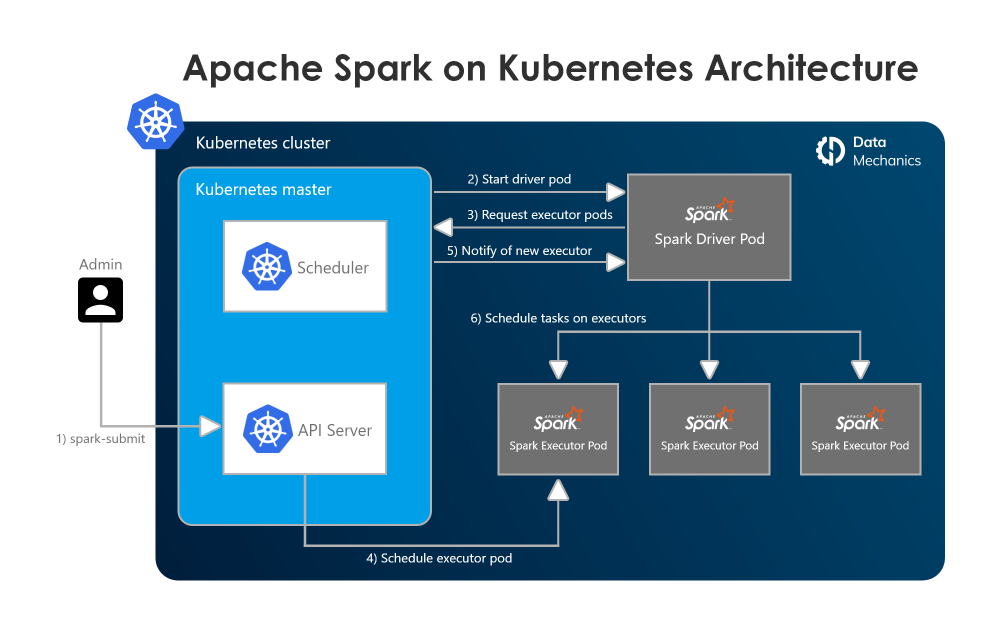
803 reads
Docker Dev Workflow for Apache Spark
by byJean-Yves "JY" Stephan@jstephan
byJean-Yves "JY" Stephan@jstephan
Co-Founder @ Data Mechanics (www.datamechanics.co). Previously software engineer @ Databricks.
December 19th, 2020





Co-Founder @ Data Mechanics (www.datamechanics.co). Previously software engineer @ Databricks.


Co-Founder @ Data Mechanics (www.datamechanics.co). Previously software engineer @ Databricks.
About Author

Co-Founder @ Data Mechanics (www.datamechanics.co). Previously software engineer @ Databricks.
Comments