658 reads
Deconstructing a Serverless Cloud OS





Too Long; Didn't Read
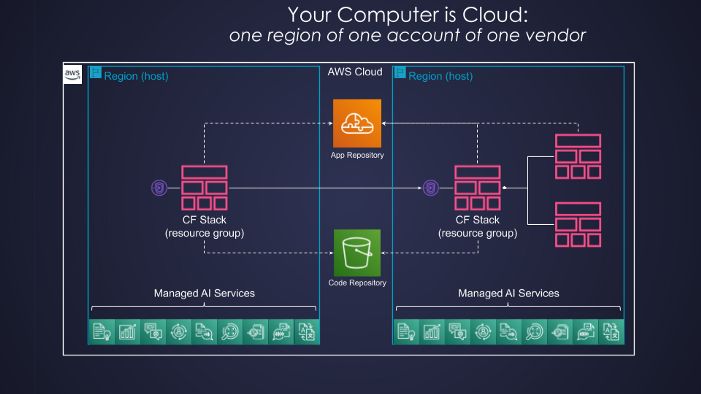
Serverless technology has produced truly disruptive change, yet to be fully absorbed by the software industry. We need to stop talking about faster horses and start talking about race cars. Cloud functions constitute a crucial ingredient in the serverless revolution, they are just one piece of a bigger puzzle. To utilize the full potential of disruption, one has to think anew and act anew. To make real breakthroughs, a RADICAL RETHINKING of many familiar concepts is required: What is a serverless cloud computer?Companies Mentioned
Coins Mentioned






Asher Sterkin
@asher-sterkin
Software technologist/architect. 40 years in the field. Focused on Cloud Serverless Native solutions
Learn More
LEARN MORE ABOUT @ASHER-STERKIN'S
EXPERTISE AND PLACE ON THE INTERNET.
EXPERTISE AND PLACE ON THE INTERNET.

L O A D I N G
. . . comments & more!
. . . comments & more!