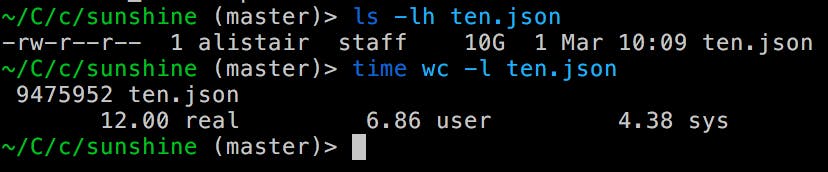
Yesterday I noticed that — even with as simple a task as counting lines in a , with as battle-tested a tool as . my laptop’s SSD is so fast, any single core can’t keep up file wc This evening, after taking on lots of advice from the lovely commenters on , I found a better way. the reddit thread The key idea is to have one thread doing absolutely nothing except: reading in data to a byte array, and passing the array to another thread to do the “processing” (if you can glorify newline-counting with that word). , the venerable unix tool, counts lines in the same thread (check out this I sketched up yesterday from the BSD wc source). wc hyper-stripped down implementation default way of reading in lines (line-seq, which uses BufferedReader under the hood) performs UTF decoding on the same thread, which (as I noticed yesterday) is a real bottleneck when your SSD is pumping through well over a gigabyte of data per second. Clojure’s And the one in my mid-2015 MBP is nowhere near top-of-the-line anymore: The parallel version I coded up tonight takes an average of 6.9 seconds to finish, which is around a 60% improvement. Not only that, but it’s not using the ugly low-level threading and concurrency primitives of the JVM, but the fairly high-level abstraction of core.async. (I also tested it against much smaller files and found a similar speedup). Here’s the code: It’s getting late here, so I’m not going to dive into it, but it just implements that core idea I mentioned above of keeping one thread dedicated to doing the system call and little else. Here’s the . If you have questions or comments, jump over to . full namespace, requires and all the /r/clojure reddit thread It seems like this issue of CPU-bound IO is going to become more important as we move towards faster SSDs, more cores, but static clock speeds. I wonder how standard libraries (like Clojure’s and Java’s) will adapt to keep up with the pace? [edit: check out the awesome unix-y ways of dealing with multi-core IO people came up with in the /r/programming thread] [edit2: here’s the whole Clojure file , if you want to try running or modifying it. and if you want to generate a test file, try: “ ] head -c 10G /dev/random > random.txt”