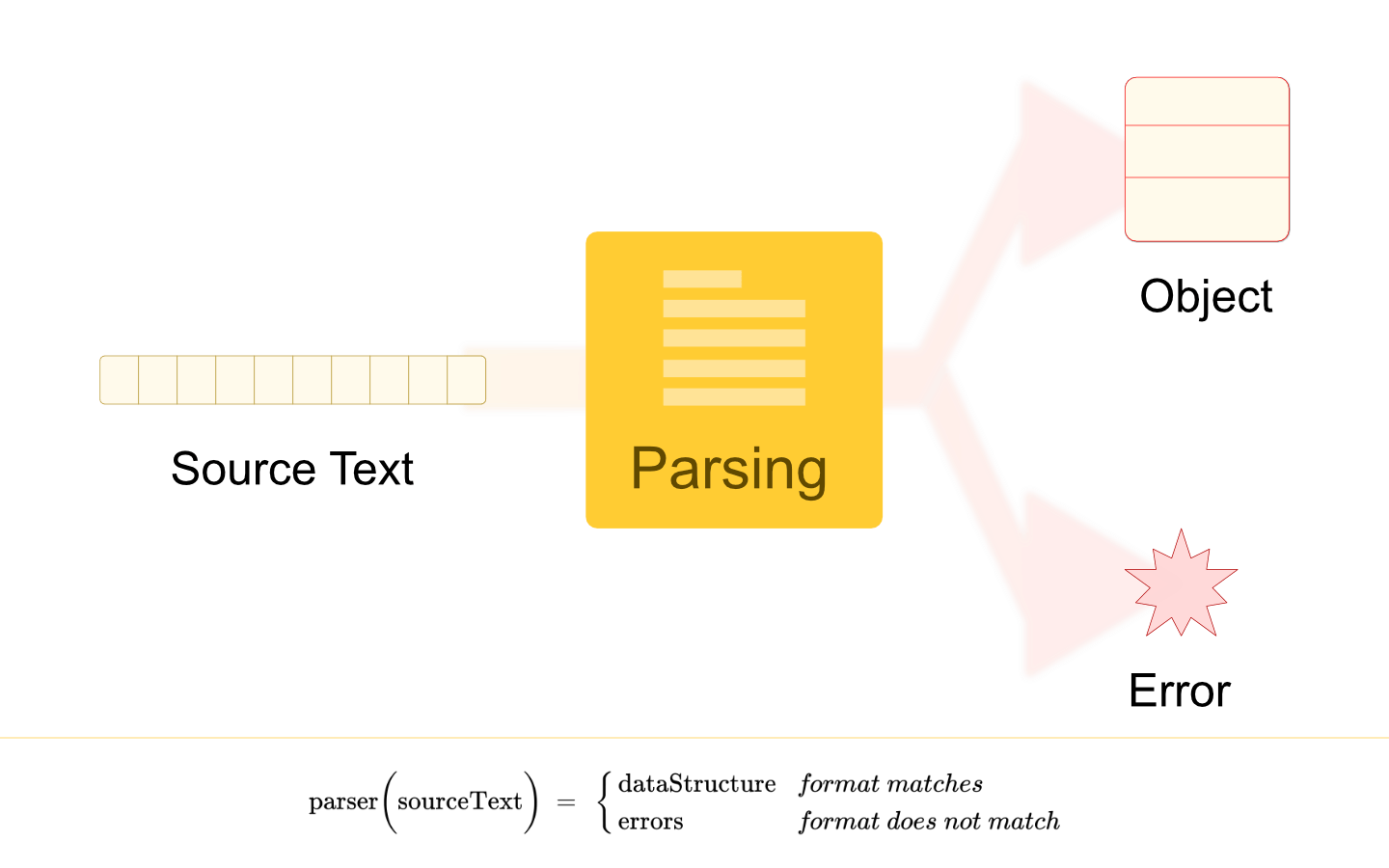
is a process of converting into a . A data structure type can be any suitable representation of the information engraved in the . Parsing formatted text data structure source text type is a common and standard choice for XML parsing, HTML parsing, JSON parsing, and any programming language parsing. The output tree is called or . In an HTML context, it is called the (DOM). Tree Parse Tree Abstract Syntax Tree Document Object Model A CSV file parsing can result in a of a . List List of values or List of Record objects Type is a choice for natural language parsing. Graph A piece of program that does parsing is called . Parser How it works Parser analyses against the format* prescribed. If source text does not match against format error is thrown or returned. source text If source text does not match against format error is thrown or returned. If matches then “data structure” is returned. *format is coded inside the parser. Format is the DNA of a parser. Small Case Study Consider an example of Date parsing from a string (source) in format to Date object: DD-MM-YYYY { day; month; year; } class Date int int int Implementation Note For Date parsing, I would be using ¹ ( for short). Regex can be matched against a string. It also helps in extracting part of the source text Regular Expression regex if it is matched. Note: This is going to be a small-scale illustration of parsing with “Regex.” This might be a fair approach for one-two lines input text but not in every case . You may have to write a parser by hand (most complex) or use Parser Generator tools (moderately complex). Code The parsing and extracting the Date element is as: String date = ; Pattern dateMatcher = Pattern.compile( ); Matcher matcher = dateMatcher.matcher(date); (matcher.find()) { day = Integer.parseInt(matcher.group( )); month = Integer.parseInt(matcher.group( )); year = Integer.parseInt(matcher.group( )); Date(day, month, year); } { DateParseException(date + ) } "20-05-2012" // 1. defining a regular expression "(\\d{2})-(\\d{2})-(\\d{4})" // 2. matching a regular expression // 3. if pattern matches if // extract day int 1 int 2 int 3 // 4. validate date : skipped code return new else // throw Error throw new " is not valid" The code is written in Java. How does this code work: 1. Date formatted as DD-MM-YYYY can be matched using regex: (\d{ })-(\d{ })-(\d{ }) # where \d matches any digit between to , # {n} means how many times the last character type is expected # () is called capturing group and enclosed part string that would be extracted. # Each group is numbered, the first group is assigned , the second one is given number , and so on 2 2 4 0 9 of "1" "2" 2. The given date as the string is matched against the defined regex. 3. If the match is successful, then the day, month, and year are extracted from the source string using provided by Regular Expression API. It is a standard construct in any Regular Expression API in any language. Group Construct 4. The extracted date parts can be validated; related code is skipped for you to exercise. This is an illustration of Regular Expression based parsing, which is limited to format, which can be defined by regular expressions. It is of parsing. A programming language or format like XML parsing is complex in nature. You can refer to the book named “ ” to get an idea about a full-scaled parsing. a basic example Crafting Interpreters You can also read about “ ” Lezer: Code Mirror’s Parsing System Phases of Parsing can be scoped as a composition of Scanning and Syntactic Analysis or just Syntactic Analysis. Parsing Scanning is a process of converting a stream of characters into Scanning tokens. A token represents a “concept” introduced by format. Logically, a token can be considered as a label assigned to one or more characters. From a processing point of view: A is an object, can contain , location information, and more. token lexeme³ In Java language: if, while, int are examples of tokens. In date parsing, tokens are defined by Regex; (day, month), (separator), (year) are tokens. Note: Day and month are the same token type. A token is defined by “the pattern of characters” not by locations of characters. \d{2} — \d{4} Scanning is also called or . A part of the program which does scanning is called Tokenization Lexical Analysis Lexer or Scanner or Tokenizer. Syntactic Analysis analyses the structure formed as keeping tokens in order as their positions. It also validates and extracts engraved data to create the preferred Data Structure. Syntactic Analysis In date parsing example: “day is followed by month and year.” The order is checked by Regex Engine. Extraction is done based on order and matches. Errors reported by this phase are called . Going back to Date parsing example, is an invalid Date; however, is a valid Date because rule says so. It may seem absurd, but parsers generally validate Syntactic Errors 99-JAN-2021 99–99–9999 (\d{2})-(\d{2})-(\d{4}) Syntactic Correctness. Closing Notes The scale of parsing determines the inclusion or exclusion of Scanning as part of it: It is beneficial for big-scale parsing like language (natural or programming) parsing to keep Scanning, and Syntactic Analysis separated. In this case, Syntactic Analysis is called parsing. For small-scale parsing like Date, it may not be beneficial to distinct Lexer and Syntactic Analysis. In this case, it is called . Scannerless Parsing Many times, parsing tasks are delegated to parser code generators like or . These tools require a set of rules or grammar and generate parser code. Antlr Lex The generated parsers produce a tree upon parsing, which may not be the desired data structure; however, these libraries provide sufficient APIs to convert the constructed tree to the desired data structure. There is more in Parser world; the type of parsing styles: top-down or bottom-up, Leftmost or Rightmost derivation. These design styles limit parsing capabilities of the parser. You may visit the following link to get a synoptic view of these design choices and their comparison: https://tomassetti.me/guide-parsing-algorithms-terminology/#tablesParsingAlgorithms Footnotes is an algebraic expression² representing a group of strings. Regular Expression An algebraic expression utilizes symbols and operators. is a raw string version of Token. A Lexeme Previously published at https://themightyprogrammer.dev/article/parsing