





85,675 reads
Complexity and Strategy





Too Long; Didn't Read
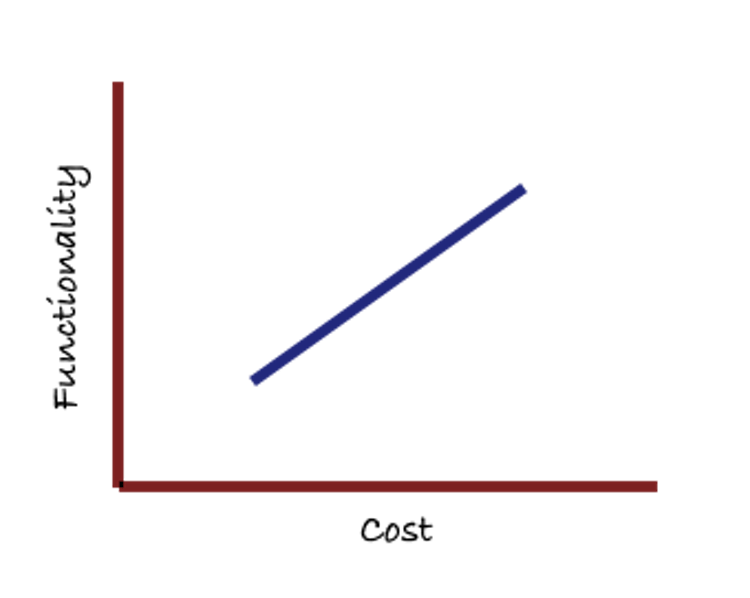
I struggled with how to think about complexity through much of my career, especially during the ten years I spent leading Office development. Modeling complexity impacted how we planned major releases, our technical strategy as we moved to new platforms, how we thought about the impact of new technologies, how we competed with Google Apps, how we thought about open source and throughout “frank and open” discussions with Bill Gates on our long term technical strategy for building the Office applications.Companies Mentioned




Terry Crowley
@terrycrowley
Recreational Programmer

L O A D I N G
. . . comments & more!
. . . comments & more!
About Author

TOPICS
THIS ARTICLE WAS FEATURED IN...



RELATED STORIES



AI Anxiety #artificial-intelligence
Oct 26, 2017


Events in C#: An Easy-to-Understand Guide #c-sharp
Apr 18, 2024



