
RAVEN PROTOCOL





- Company Ranking
- Stock Price
RAVEN PROTOCOL (RAVEN)
EVERGREEN INDEX #10381
Raven Protocol's stories on HackerNoon
Technology evolves every day, impacting our lives more and more. Don’t miss out on the tech of tomorrow via these remarkable technology stories.
Namespace.gg: A Solution To The (Centralized) Identity Crisis
Fri Oct 13 2023 By Decent Land Labs

Are IDOs the Next Alternative to IEOs and ICOs?
Fri Dec 18 2020 By Serge Baloyan
Can IDOs #RightTheWrongs of ICOs and IEOs?
Fri Jul 09 2021 By Victor Ugochukwu

What Happened to the Ico?
Thu Jul 08 2021 By Ruben Merre

Why Developers Are Buzzing About Mozilla’s Fix-The-Internet Incubator
Tue May 26 2020 By Sherman Lee
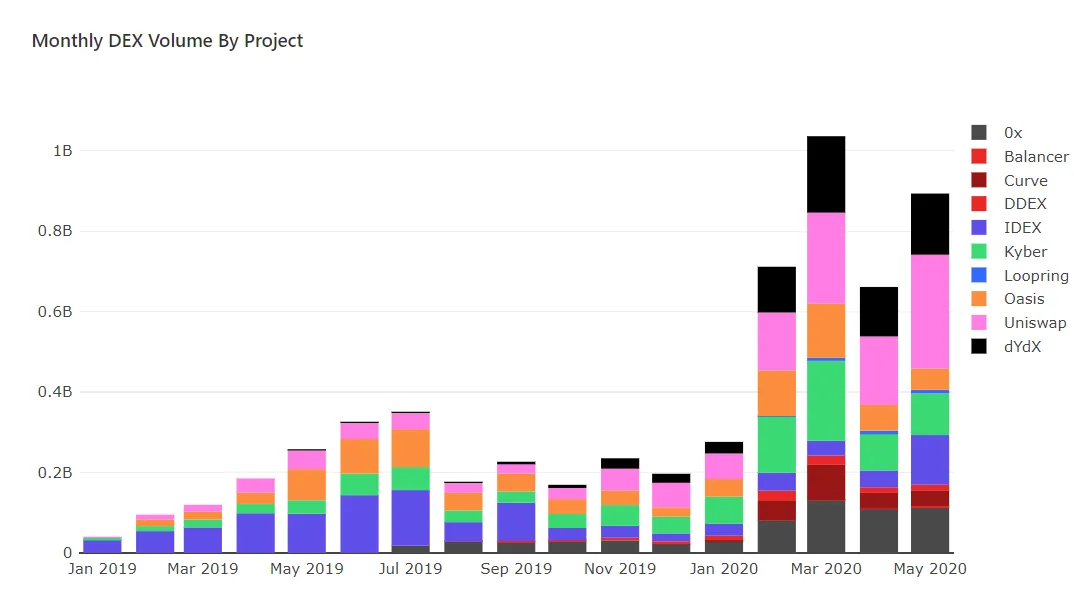
Examining Decentralized Exchange Token Sales
Thu Jun 18 2020 By Ingamar

T-Mobile’s Accelerator and Innovation Lab is Paving the Way for 5G Adoption Across the US
Tue May 26 2020 By Sherman Lee

Crypto Investors: Did You Already Miss the Next Evolution of Blockchain Fundraising?
Mon Apr 29 2019 By Sherman Lee

Everipedia Culture Roundup #12: Smooth Groves and Big Moves
Thu Mar 28 2019 By David Liebowitz

Strategic Partnerships of PixEOS
Fri Jan 04 2019 By Crypto Stella

Builders gonna build.
Wed Aug 15 2018 By Sherman Lee

2020 Noonies Awards: Official Winners of The Internet Now Declared
Tue Oct 20 2020 By Natasha Nel
Raven Protocol's Related Companies
Explore a rich selection of stories about your favorite games, how they are made, and the people that make them, from gamers and game developers worldwide.HiddenLayer
hiddenlayer.com
 Founded
Founded2022
 Worth
Worth251.2M
Adversarial Attacks on Large Language Models and Defense Mechanisms by Prakash Velusamy
The Remonetization of Gold and The Dawn of Tokenized Trust by Olayimika Oyebanji
Jarvis ML
jarvisml.com
Founded2021
When Will We See Bitcoin's Top? by www.jarvis-labs.xyz
How Far Are We From a Real World Jarvis? by Ida Jessie Sagina
Blue Lock AI
bluelockai.com
Founded2022
Missed Bitcoin? Here’s How to buy Bitcoin Cash by Vamshi Vangapally
How to buy Ethereum in USA, Australia, Europe & Singapore by Vamshi Vangapally
Ground Signal
groundsignal.com
Founded2015
The Rise of Tech in Vancouver by twaye
My Raspberry Pi on 2 Wheels by Hendrik Ewerlin
Plend
plend.co.uk
Founded2020
Backing the Boom: Why the Rise of Generative AI is Nothing Like the Dotcom Bubble by Dmytro Spilka
5 Cryptocurrency Staking Providers - A Review by Crypto Adventure
Razoroo
razoroo.com
Founded2012
3%
How Machine Learning is Transforming Biotech by Mia Fischer
How To Migrate from .NET Core 2.2 to .NET Core 3.1: Real Life Project by nopCommerce
Representing this company? Click here to claim and customize this page!
Reviews About Raven Protocol
