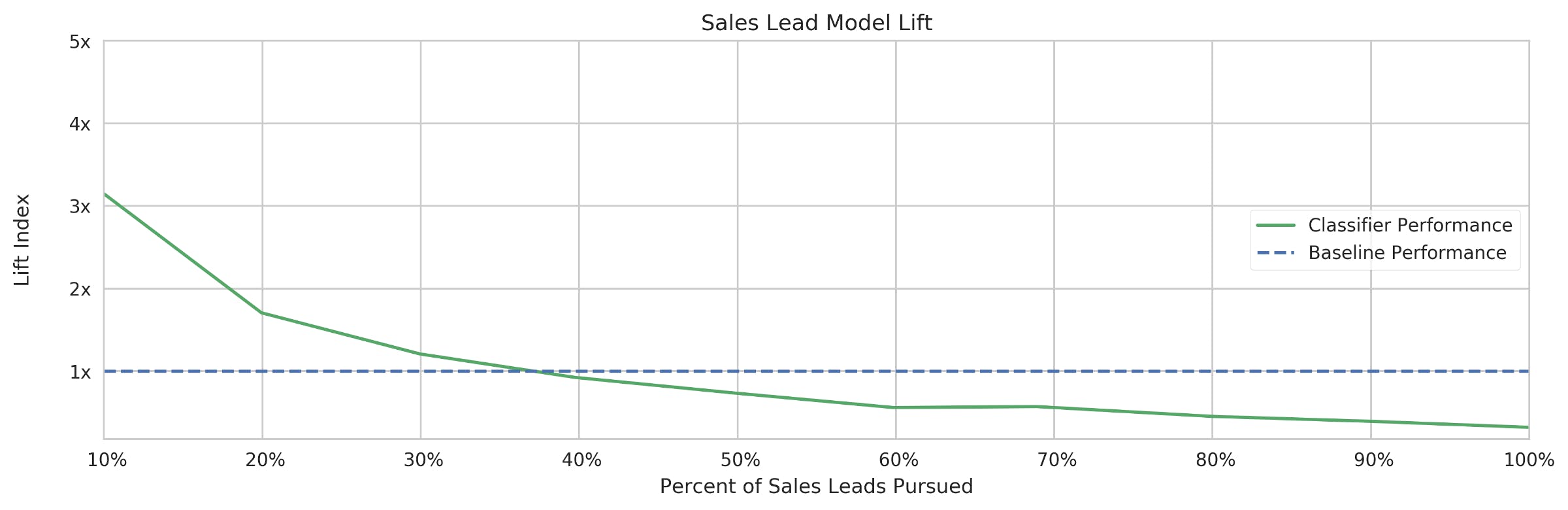
Tools so simple even your sales team will understand! You’ve created a model to predict which sales leads are likely to turn into convert into paying customers. The model is a true work of algorithmic beauty — its your Mona Lisa, but better since it actually does something useful. You have tuned the parameters and cross-validated the results, which means the only thing left to do is present your work to the company’s executives. “No problem” you think to yourself, you’ll just talk them through a Confusion Matrix and ROC curve and wait for them to lavish you in riches and praise. Anyone who has tried to walk stakeholders through predictive model performance knows that you are more likely to get strained expressions and blank stares than a standing ovation. So I want to share a simple called a lift chart that we’ve come to rely on at Oracle for translating model performance into business impact. business tool Model Lift A Lift chart is a visual way of showing how much better we are at predicting successful outcomes with a model than if we were to guess at random. More importantly, it shows the likelihood of responding positively for different groups within the scored population. Metrics like ROC AUC and F1 Score are popular because they summarize model performance in a single number. In most applied machine learning tasks, however, budget constraints force us to focus on a subset of the population. More on this later, but for now let’s take a look at an example lift chart. This plot shows the lift for our example of trying to predict which sales leads will turn into customers. Based on this plot, we can see that the top 10% of leads (as identified by the model) are a little over 3x more likely to become customers than if we were to pursue leads at random. After the top 35% of leads, we’ve exhausted the predictive power of the model and the lift < 1x indicates that leads beyond this point are less likely to become customers the “typical” lead. Applying Business Context to the Lift Chart You’re probably thinking to yourself “Great, so what?” Aside from controlling for the base success rate, a lift chart doesn’t appear to be anything special. From a data science perspective this is true, it’s simply the of different groups within your modeled population. precision The real power of the lift chart comes from the fact that it puts our machine learning problem into the same terms in which business decisions are made — marginal cost and benefit. Let’s say that each sales lead your company decides to pursue costs $100 in personnel and marketing costs. Based on a separate analysis, you calculate that the of a new customer is $500. We can easily overlay this information on top of the lift chart to show the expected revenue per lead — the probability that a sales lead converts into a customer multiplied by the LTV of that new customer. lifetime value (LTV) The difference between the green expected revenue curve and the red cost curve is the profit the company can expect from those leads. If the goal is to maximize the company’s dollar profit, we should pursue the top 40% of leads identified by the model. Beyond this point, the cost of going after each lead outweighs the expected benefits, eating into the company’s profits. Communicating Business Impact So is your mind blown yet? …no? That’s the point! The beauty of the lift chart is that it is so straight forward that anyone can look at it and intuitively grasp its meaning. The most striking feature of the plots above is that there isn’t a trace of data science verbiage anywhere to be found. No need to begin your presentations with a preamble on true vs false positives, precision vs recall, or sensitivity vs specificity. In fact, there’s no need to discuss probability at all (which is a good thing since ). humans generally suck at it While simplicity is the great benefit of the lift chart, it is also one of it’s biggest barriers to adoption. There’s something anticlimactic to data scientists about capping off a 6 month R&D project by walking the CEO through a chart that looks like it was lifted from an Econ 101 textbook. Too often data scientists will use presentations as an opportunity to prove their value by showing how complex their work is. However, the focus should be on the business outcomes driven by the work rather than the work itself, which is exactly what the lift chart does. Creating a Lift Chart: Step-by-Step Let’s walk through the steps of creating lift charts similar to those above. I’m going to use Python (specifically scikit-learn, pandas, and matplotlib) in this example, but the important thing here is the intuition and not the code. Step 1: Create Predictive Model: The following steps will apply to any binary classification task, regardless of the feature set or the type of algorithm used. For our example problem, I created a 10,000 row dataset with 20 features that are used to train a decision tree model to predict whether each sales lead will successfully convert into a paying customer (y=1) or remain a non-customer (y=0). Again the type of classifier is not important here, as the following steps will be the same regardless of whether you are using naive bayes, SVM, random forest, or even good ol’ linear regression. Step 2: Score Observations and Split into Deciles Using the features in your test set (x_test), predict the probability of a success (y_test = 1) for each sales lead. Then sort leads in descending order based on predicted probability and split the leads into 10 equal groups. Since Python is zero-based, group 0 contains leads that are most likely to buy (according to their score) and leads in group 9 are the ones least likely to to become customers. Comments: In practice, it’s hard for us to know how accurate these probabilities are since each lead in our dataset will act only once. This means that we can’t judge model performance based on the outcomes of individual leads, but we can look at the outcomes for a group of leads with a similar probability of becoming a customer. Step 3: Calculate Conversion Rate within Deciles Within each group, sum the number of successfully converted leads (y_test=1) and divide by the total number of leads in that group. This will give you the percent of leads in each group who converted to customers. : Another benefit of the lift chart is that it provides a quick way to check for overfitting. The group with the highest scores should have the most successful conversions and the conversion rate of each succeeding group should be monotonically decreasing. In practice it’s not uncommon to see a little jaggedness in the tail of the plot, but if groups with lower scores are consistently outperforming those with higher scores, then it is probably worth going back to your model to ensure that it is generalizing properly. Comments Step 4: Index to Baseline Conversion Rate and Plot To help give the lift numbers meaning, we need to calculate the baseline conversion rate. This is simply the percent of leads, regardless of bucket, who converted into customers (y_test =1). Then divide the conversion rate of each bucket by the baseline conversion rate. This is all you need for the lift chart! The code that I used to create the chart in Matplotlib is below, but you could just as easily create the chart in Excel. For reference, here is the data underlying the plot
















![What Are Convolution Neural Networks? [ELI5]](https://hackernoon.imgix.net/images/69s32rn.jpg?auto=format&fit=max&w=3840)











