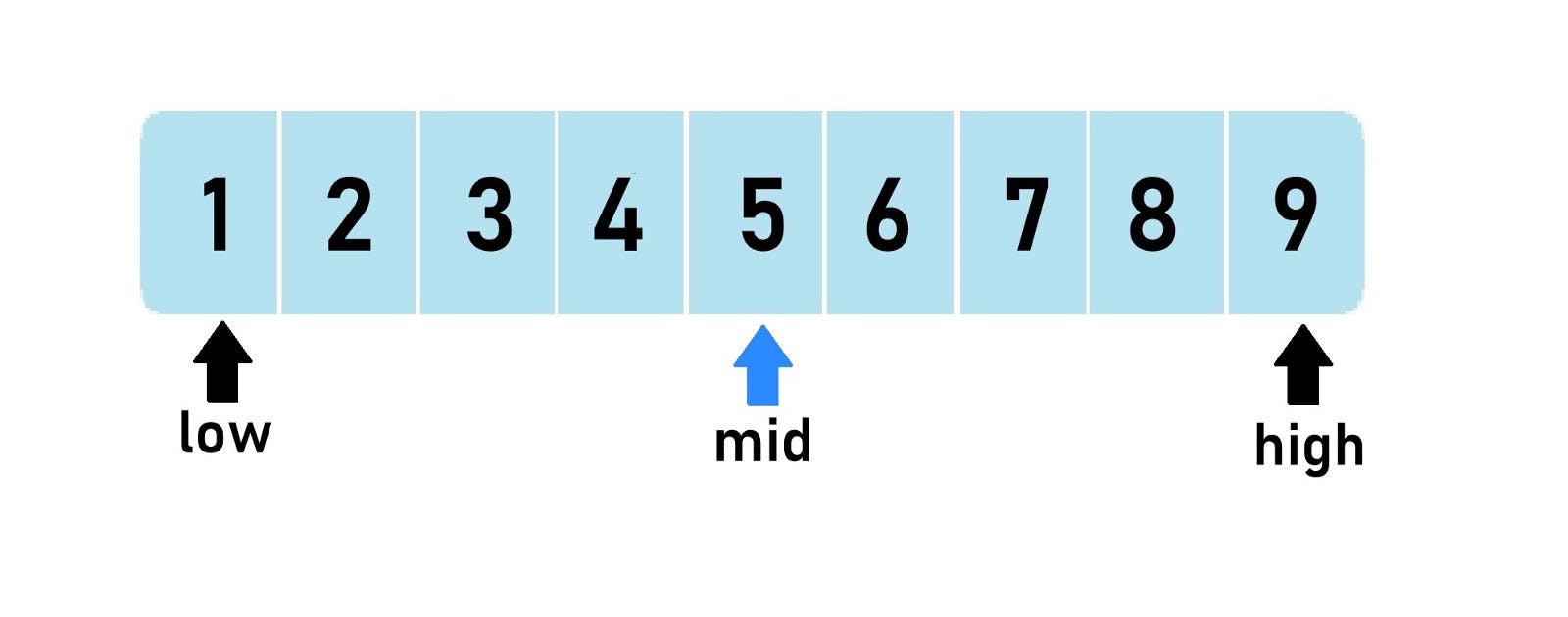
In this part of creating your programming language, we will implement arrays. Please see the previous parts: Building Your Own Programming Language From Scratch Building Your Own Programming Language From Scratch: Part II - Dijkstra's Two-Stack Algorithm Build Your Own Programming Language Part III: Improving Lexical Analysis with Regex Lookaheads Building Your Own Programming Language From Scratch Part IV: Implementing Functions The full source code is available over on . GitHub Our language will provide the following abilities for the arrays: Define an array array = { 1, 2, 3 } Define an empty array empty_array = { } Contain arbitrary types of values: plain types, structure instantiations, function invocations, nested operators with other arrays, and any other composite expressions inheriting the interface Expression arbitrary_array = { 1, "two", false, new Structure[4], get_value[5], { 6, 7 * 8 } } Append a value to the defined array with operator << array = { 1, 2 } array << 3 # will contain { 1, 2, 3 } Access array’s value by index position first_value = array{0} Update array’s value by index position array{0} = 1 array{1} = array{array{0} + 1} + 1 1 Lexical analysis We will begin with lexical analysis. Basically, it’s a process to divide the source code into tokens, such as keyword, identifier/variable, operator, etc. First, to define the array, we add curly brackets as the lexeme. We can’t use the square brackets or round brackets as they are already taken by the functions/structures definitions and by expression operators accordingly. { } GroupDivider [ ] ( ) package org.example.toylanguage.token; ... public enum TokenType { ... GroupDivider("(\\[|\\]|\\,|\\{|})"), ... } Second, we need to introduce a new Operator lexeme to define the "append a value to array" operation. We’ll extend the current less than operator by adding an quantifier after it, which will be able to catch either one or two symbols: << < {1,2} < ... public enum TokenType { ... Operator("([+]|[-]|[*]|[/]|[%]|>=|>|<=|[<]{1,2}|[=]{1,2}|!=|[!]|[:]{2}|[(]|[)]|(new|and|or)(?=\\s|$))"), ... } With all this being set, we will catch all the needed lexemes properly with defined TokenType values. 2 Syntax analysis In this section, within the syntax analysis, we will convert tokens obtained from the lexical analysis into final statements following our language’s array rules. Arrays are just like any other part of the expression without any additional statements. Therefore, we just need to extend the existing functionality for the . ExpressionStatement 2.1 ArrayExpression First, to declare any values in our array, we define the class and add the of values, which will accept the values to allow us to place non-final values such as variables, structure invocations, function invocations, operators, and any other Expression implementations. Next, we implement the interface, which requires us to override the method. It’s a deferred interface to transform array expressions into final values, which will be invoked only during direct code execution: ArrayExpression List Expression Expression evaluate() Expression Value package org.example.toylanguage.expression; @RequiredArgsConstructor @Getter public class ArrayExpression implements Expression { private final List<Expression> values; @Override public Value<?> evaluate() { return new ArrayValue(this); } } 2.2 ArrayValue The next class we implement is , which will accept the as a constructor argument to gather all the details about the array state. To change the array values, we include the corresponding , , methods: ArrayValue ArrayExpression getValue() setValue() appendValue() package org.example.toylanguage.expression.value; public class ArrayValue extends Value<List<Value<?>>> { public ArrayValue(ArrayExpression expression) { this(expression.getValues() .stream() .map(Expression::evaluate) .collect(Collectors.toList())); } public Value<?> getValue(int index) { if (getValue().size() > index) return getValue().get(index); return NULL_INSTANCE; } public void setValue(int index, Value<?> value) { if (getValue().size() > index) getValue().set(index, value); } public void appendValue(Value<?> value) { getValue().add(value); } } We can also override the method, as it will be used by the and to compare: equals() EqualsOperator NotEqualsOperator ... public class ArrayValue extends Value<List<Value<?>>> { ... @Override public boolean equals(Object o) { if (this == o) return true; if (o == null) return false; if (getClass() != o.getClass()) return false; //noinspection unchecked List<Value<?>> oValue = (List<Value<?>>) o; return new HashSet<>(getValue()).containsAll(oValue); } } 2.3 Operator 2.3.1 ArrayValueOperator With the implementation, we can already instantiate arrays and fill them with values. The next goal is to access the array’s value by index position. For this purpose, we'll create the operator implementation, which contains two operands. The method will use the first operand as the array itself and the second operand as an index. The method is used to set the array’s value by index using the same operands: ArrayExpression BinaryOperatorExpression evaluate() assign() package org.example.toylanguage.expression.operator; public class ArrayValueOperator extends BinaryOperatorExpression implements AssignExpression { public ArrayValueOperator(Expression left, Expression right) { super(left, right); } @Override public Value<?> evaluate() { Value<?> left = getLeft().evaluate(); if (left instanceof ArrayValue) { Value<?> right = getRight().evaluate(); return ((ArrayValue) left).getValue(((Double) right.getValue()).intValue()); } return left; } @Override public void assign(Value<?> value, VariableScope variableScope) { Value<?> left = getLeft().evaluate(); if (left instanceof ArrayValue) { Value<?> right = getRight().evaluate(); ((ArrayValue) left).setValue(((Double) right.getValue()).intValue(), value); } } } The new interface can be used to set the variable's value only within the assignment operator: AssignExpression = public interface AssignExpression { void assign(Value<?> value, VariableScope variableScope); } public class AssignmentOperator extends BinaryOperatorExpression { ... @Override public Value<?> evaluate() { if (getLeft() instanceof AssignExpression) { Value<?> right = getRight().evaluate(); ((AssignExpression) getLeft()).assign(right, variableScope); } ... } } 2.3.2 ArrayAppendOperator Next, to transform the "append a value to array" operator defined as Operator lexeme, we create a new implementation. The left operand is still the array itself, and the right operand is the value we want to append: << BinaryOperatorExpression package org.example.toylanguage.expression.operator; public class ArrayAppendOperator extends BinaryOperatorExpression { public ArrayAppendOperator(Expression left, Expression right) { super(left, right); } @Override public Value<?> evaluate() { Value<?> left = getLeft().evaluate(); if (left instanceof ArrayValue) { Value<?> right = getRight().evaluate(); ((ArrayValue) left).appendValue(right); } return getLeft().evaluate(); } } Don’t forget to include this operator in the enum. It will have the same precedence as the Assignment operator: << Operator ... public enum Operator { ... ArrayAppend("<<", ArrayAppendOperator.class, 0), Assignment("=", AssignmentOperator.class, 0); ... } 2.4 ExpressionReader In this section, we will complete syntax analysis for the array integration by reading an actual array instantiation and the array’s value. To make it work, we need to extend the implementation to support array expressions within Dijkstra's Two-Stack algorithm. ExpressionReader 2.4.1 Array instantiation First, we will read the array instantiation. We extend the filter to support the curly brackets as the marker of array beginning: readExpression() package org.example.toylanguage; public class StatementParser { ... private class ExpressionReader { ... private Expression readExpression() { while (hasNextToken()) { ... } } private boolean hasNextToken() { if (tokens.peekSameLine(TokenType.Operator, TokenType.Variable, TokenType.Numeric, TokenType.Logical, TokenType.Null, TokenType.Text)) return true; //beginning of an array if (tokens.peekSameLine(TokenType.GroupDivider, "{")) return true; return false; } } } Next, we implement the corresponding case for the GroupDivider lexeme: { private Expression readExpression() { while (hasNextToken()) { Token token = tokens.next(); switch (token.getType()) { case Operator: ... default: String value = token.getValue(); Expression operand; switch (token.getType()) { case Numeric: ... case Logical: ... case Text: ... case Null: ... case GroupDivider: if (Objects.equals(token.getValue(), "{")) { operand = readArrayInstance(); break; } case Variable: default: ... } operands.push(operand); } } ... } The pattern for the array expression is the same as for the function invocation except for using the curly brackets instead of square brackets: we read the array's values as the expressions divided by a comma within the curly brackets. In the end, we build the with the obtained values: Expression ArrayExpression // read array instantiation: { 1, 2, 3 } private ArrayExpression readArrayInstance() { List<Expression> values = new ArrayList<>(); while (!tokens.peekSameLine(TokenType.GroupDivider, "}")) { Expression value = new ExpressionReader().readExpression(); values.add(value); if (tokens.peekSameLine(TokenType.GroupDivider, ",")) tokens.next(); } tokens.next(TokenType.GroupDivider, "}"); //skip close curly bracket return new ArrayExpression(values); } 2.4.2 Access array’s value by index Accessing the array’s value by index position is less straightforward than the array’s append operation because our Dijkstra’s Two-Stack algorithm inside the ExpressionReader cannot handle the array’s index defined within the curly brackets as an operator. To solve this limitation, we will read the operator with operands together as a composite operand the same way we did read the structure instantiation, except for the fact that we don’t have the "new" operator in front of the structure and the array’s index is defined inside curly brackets instead of square brackets: // read array's value: array{index} private ArrayValueOperator readArrayValue(Token token) { VariableExpression array = new VariableExpression(token.getValue()); tokens.next(TokenType.GroupDivider, "{"); Expression arrayIndex = new ExpressionReader().readExpression(); tokens.next(TokenType.GroupDivider, "}"); return new ArrayValueOperator(array, arrayIndex); } private Expression readExpression() { while (hasNextToken()) { Token token = tokens.next(); switch (token.getType()) { case Operator: ... default: String value = token.getValue(); Expression operand; switch (token.getType()) { case Numeric: ... case Logical: ... case Text: ... case Null: ... case GroupDivider: ... case Variable: default: if (!operators.isEmpty() && operators.peek() == Operator.StructureInstance) { ... } else if (tokens.peekSameLine(TokenType.GroupDivider, "[")) { ... } else if (tokens.peekSameLine(TokenType.GroupDivider, "{")) { operand = readArrayValue(token); } else { ... } } operands.push(operand); } } ... } 3 Tests We have finished embedding arrays in both lexical and syntax analyzers. Now we should be able to read array expressions, access and update array values. Let’s implement a more realistic task - the recursive binary search algorithm: fun binary_search [ arr, n, lo, hi, key ] if hi >= lo then mid = (hi + lo) // 2 # floor division if arr{mid} < key then return binary_search [ arr, n, mid + 1, hi, key ] elif arr{mid} > key then return binary_search [ arr, n, lo, mid - 1, key ] else then return mid end else then return -1 end return end arr = {10, 20, 30, 50, 60, 80, 110, 130} arr << 140 arr << 170 n = 10 print binary_search [ arr, n, 0, n - 1, 10 ] # 0 print binary_search [ arr, n, 0, n - 1, 80 ] # 5 print binary_search [ arr, n, 0, n - 1, 170 ] # 9 print binary_search [ arr, n, 0, n - 1, 5 ] # -1 print binary_search [ arr, n, 0, n - 1, 85 ] # -1 print binary_search [ arr, n, 0, n - 1, 175 ] # -1